(2)ElasticSearch在linux环境中集成IK分词器
1.简介
ElasticSearch默认自带的分词器,是标准分词器,对英文分词比较友好,但是对中文,只能把汉字一个个拆分。而elasticsearch-analysis-ik分词器能针对中文词项颗粒度进行粗细提取,所以对中文搜索是比较友好的。IK分词器有两种类型ik_smart和ik_max_word,前者提取词项粒度最粗,后者最细。而ElasticSearch默认并不支持IK分词器,需要自己安装。
2.前期准备
2.1下载elasticsearch-analysis-ik分词器组件
到GitHub下载页https://github.com/medcl/elasticsearch-analysis-ik/releases
下载elasticsearch-analysis-ik-7.8.0版本(因为我的elasticsearch版本是7.8,所以这里IK分词器组件对应下载版本也是7.8),如图所示:
3.ik分词器部署
3.1创建ik分词器文件夹
在elasticsearch/elasticsearch-7.8.0/plugins目录下创建ik分词器文件夹(文件夹名称一定要命名为ik,不然启动elasticsearch时候会报错的),创建文件夹命令如下:
mkdir /home/deng/elasticsearch/elasticsearch-7.8.0/plugins/ik
再通过Xftp把之前下载好的elasticsearch-analysis-ik-7.8.0.tar.gz安装包传输到installpackage中:
3.2解压ik分词器安装包
先切换到ik文件夹目录:
cd /home/deng/elasticsearch/elasticsearch-7.8.0/plugins/ik
把elasticsearch-analysis-ik安装包解压到ik目录当中。本人这里演示是先在本地先解压elasticsearch-analysis-ik-7.8.0.zip安装包,然后再通过Xftp复制文件传输到服务端的ik文件夹中,当然大伙也可以直接使用命令解压,这里就不详说了,解压后如图所示:
解压完ik分词器安装包后,重启elasticsearch。
4.测试ik分词
4.1ElasticSearch标准分词
在测试ik分词之前,我们通过kibana的dev_tools工具来看看elasticsearch自带标准分词器效果:
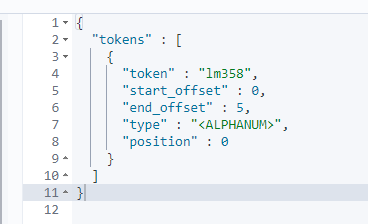
POST _analyze
{
"text": ["LM358"]
}
POST _analyze
{
"text": ["LM358,LM"]
}

POST _analyze
{
"text": ["LM358 LM"]
}
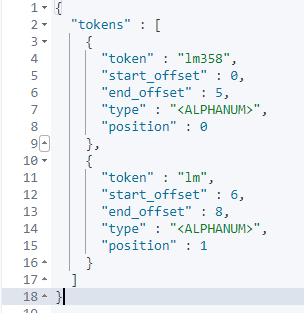
POST _analyze
{
"text": ["我是中国人!"]
}
通过上面效果图,我们知道ElasticSearch标准分词器只会把大部分符号跟空格符作为分词标准从而拆分词项,而对中文则是将每个词作为标准拆分,所以ElasticSearch标准分词并不能满足常见中文搜索业务,而这时候ik分词器就能发挥它的作用了,下面我们再来看看IK分词效果就会明白了。
4.2ik分词
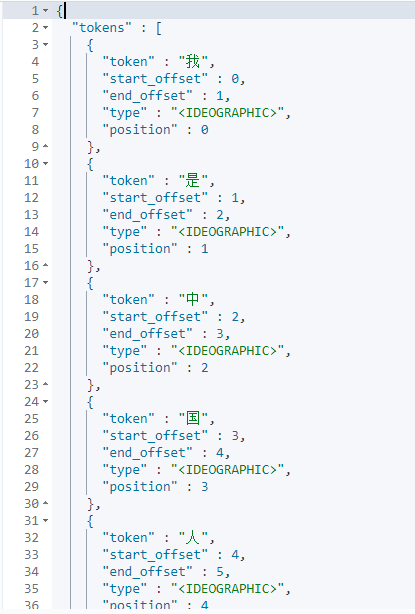
在简介里面介绍过ik分词器有两种分词类型ik_smart和ik_max_word,前者提取词项粒度最粗,后者最细。下面我们同样通过kibana的dev_tools工具来看看ik分词器效果:
POST _analyze
{
"analyzer":"ik_smart",
"text": ["我是中国人!"]
}

POST _analyze
{
"analyzer":"ik_max_word",
"text": ["我是中国人!"]
}

通过上面效果图,我们大概会了解到ik分词器不会跟ElasticSearch标准分词器一样只会把每个汉字拆分为单独一个词项,而是会根据分词类型(ik_smart,ik_max_word)把汉字拆分为不同词项,而且ik_smart拆分颗粒度比较粗糙,ik_max_word拆分颗粒度比较细致。
5.ik分词扩展词典
通过官方文档,我们知道ik分词器还支持扩展词典。我们先在elasticsearch/elasticsearch-7.8.0/plugins/ik/config目录下新建一个custom文件夹,在custom文件夹中再新建一个UTF-8编码的.txt文件,命名为mydic.dic(具体操作命令我就不详说了)内容如下图所示: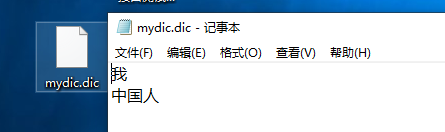
然后在elasticsearch/elasticsearch-7.8.0/plugins/ik/config目录下IKAnalyzer.cfg.xml 配置文件中修改如下配置(只修改ext_dict即可):
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!--<entry key="remote_ext_dict">location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
然后重启elasticsearch,再通过kibana的dev_tools工具来看看ik分词器扩展效果:
POST _analyze
{
"analyzer":"ik_max_word",
"text": ["我是中国人!"]
}
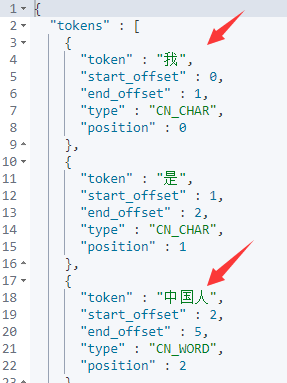
6.ik热词更新
根据官方介绍,目前IK分词器是支持热词更新的,可以将需自动更新的热词放在一个UTF-8编码的.txt文件里,放在nginx或其他简易http server下,当.txt文件修改时,http server会在客户端请求该文件时自动返回相应的Last-Modified和ETag(该http请求需要返回两个头部header标识,一个是Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,IK分词器就会去抓取新的分词进而更新词库)。可以另外做一个工具来从业务系统提取相关词汇,并更新这个热词.txt文件。
下面演示我使用iis作为http server服务器,新建一个名称叫hotword站点,站点下有一个hotword.txt文件,应用池托管为v 4.0集成模式。
同时配置下如下两个选项: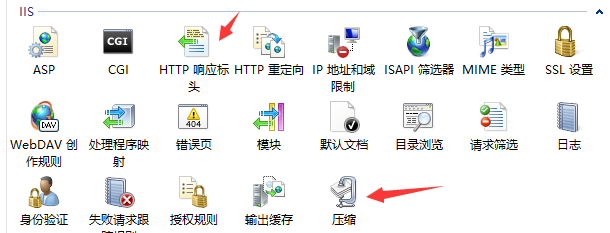

hotword.txt内容如下: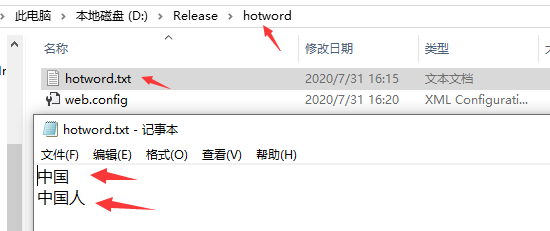
这里要注意一点细节,因为http请求返回的内容格式是一行一个分词,所以hotword.txt词项要用换行符用 \n换行。
然后再通过在elasticsearch/elasticsearch-7.8.0/plugins/ik/config目录下IKAnalyzer.cfg.xml 配置文件中修改如下配置:
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://192.168.18.4:8082/hotword.txt</entry>
其中http://192.168.18.4:8082/hotword.txt是如上我本地部署热词站点。然后重启elasticsearch,在/elasticsearch/elasticsearch-7.8.0/logs/elasticsearch.log中可以看到加载的热词列表,如下所示:
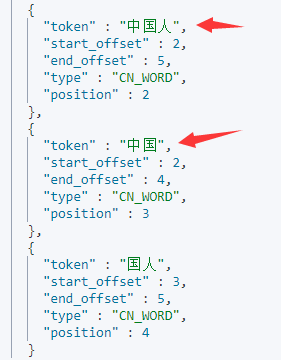
通过kibana的dev_tools工具来看看ik分词器效果:
POST _analyze
{
"analyzer":"ik_max_word",
"text": ["我是中国人!"]
}
参考文献:
elasticsearch-analysis-ik
(2)ElasticSearch在linux环境中集成IK分词器的更多相关文章
- (3)ElasticSearch在linux环境中安装与配置head插件
1.简介 ElasticSearch-Head跟Kibana一样也是一个针对ElasticSearch集群操作的API的可视化管理工具,它提供了集群管理.数据可视化.增删改查.查询语句等功能,最重要还 ...
- Linux使用Docker启动Elasticsearch并配合Kibana使用,安装ik分词器
注意事项 这里我的Linux虚拟机的IP地址是192.168.1.3 Docker运行Elasticsearch容器之后不会立即有反应,要等一会,等待容器内部启动Elasticsearch,才可以访问 ...
- ES系列一、CentOS7安装ES 6.3.1、集成IK分词器
Elasticsearch 6.3.1 地址: wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3. ...
- Lucene介绍及简单入门案例(集成ik分词器)
介绍 Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和 ...
- Linux安装ElasticSearch7.X & IK分词器
前言 安装ES之前,请先检查JDK版本,es使用java编写,强依赖java环境.JDK安装过程略. 安装步骤 1.下载地址 点击这里下载7.2.0 2.解压elasticsearch-7.2.0-l ...
- Elasticsearch教程(三),IK分词器安装 (极速版)
如果只想快速安装IK,本教程管用.下面看经过. 简介: 下面讲有我已经打包并且编辑过的zip包,你可以在下面下载即可. 当前讲解的IK分词器 包的 version 为1.8. 一.下载zip包. 下面 ...
- docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head跨域问题 + IK分词器
0. docker pull 拉取elasticsearch + elasticsearch-head 镜像 1. 启动elasticsearch Docker镜像 docker run -di ...
- Elasticsearch集成ik分词器
1.插件地址https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.0.0/elasticsearch-anal ...
- Elasticsearch教程(二),IK分词器安装
elasticsearch-analysis-ik 是一款中文的分词插件,支持自定义词库,也有默认的词库. 开始安装. 1.下载 下载地址为:https://github.com/medcl/ela ...
随机推荐
- 手把手搭建一个属于自己的在线 IDE
背景 这几个月在公司内做一个跨前端项目之间共享组件/区块的工程,主要思路就是在 Bit 的基础上进行开发.Bit 主要目的是实现不同项目 共享 与 同步 组件/区块,大致思路如下: 在 A 项目中通过 ...
- .net 手动建DataTable 获取DataTable列名 修改DataTable 列的顺序
//创建 表 DataTable tables = new DataTable(); //添加 创建 列 //第一列 DataColumn cums = new DataColumn(); cums. ...
- <二分查找+双指针+前缀和>解决子数组和排序后的区间和
<二分查找+双指针+前缀和>解决子数组和排序后的区间和 题目重现: 给你一个数组 nums ,它包含 n 个正整数.你需要计算所有非空连续子数组的和,并将它们按升序排序,得到一个新的包含 ...
- 【C语言编程入门笔记】排序算法之快速排序,一文轻松掌握快排!
排序算法一直是c语言重点,各个算法适应不用的环境,同时,在面试时,排序算法也是经常被问到的.今天我们介绍下快速排序,简称就是快排. 1.快速排序思想: 快排使用 分治法 (Divide and con ...
- Python之dict字典详解
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,字典是另 一种可变容器模型,且可存储任意类型对象.具有极快的查找速度. 字典是一种通过名字或者关键字 ...
- NCEP数据资料获取 地面抬升指数
先放上数据地址:https://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanalysis.surface.html 美国国家环境预报中心(NCEP ...
- 【设计模式】第一篇:概述、耦合、UML、七大原则,详细分析总结(基于Java)
迷茫了一周,一段时间重复的 CRUD ,着实让我有点烦闷,最近打算将这些技术栈系列的文章先暂时搁置一下,开启一个新的篇章<设计模式>,毕竟前面写了不少 "武功招式" 的 ...
- BlockCanary界面卡顿检测
添加依赖: implementation 'com.github.markzhai:blockcanary-android:1.5.0' 运行后会同时安装检测工具,主要检测UI线程运行卡顿现象 pub ...
- 字符串截取 slice,substr,substring 的区别
一 只传递一个参数时候 let str = '0123456'; str.slice(5); //'56' str.substr(5); // '56' str.substring(5); // '5 ...
- Linux 环境编程:dirfd参数 有关解析
背景 在Unix环境编程中,系统提供了很多以at结尾的函数,如openat.fstatat等,而这类函数通常有一个特点,就是形参列表中多了int dirfd 例如: int open(const ch ...