SSIS数据同步实践
背景
测试环境
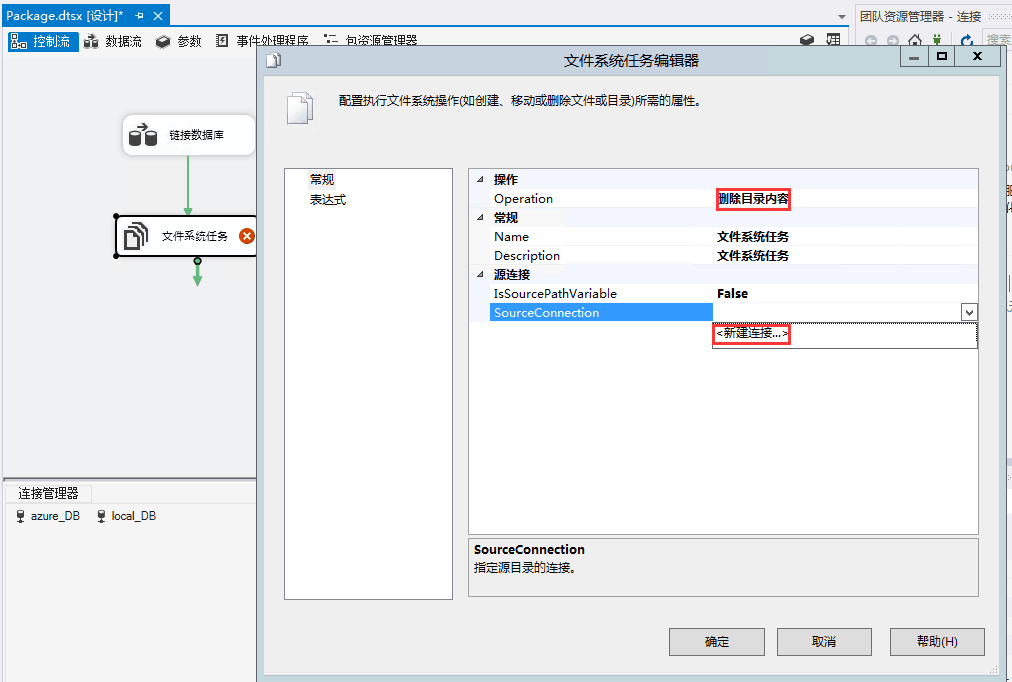
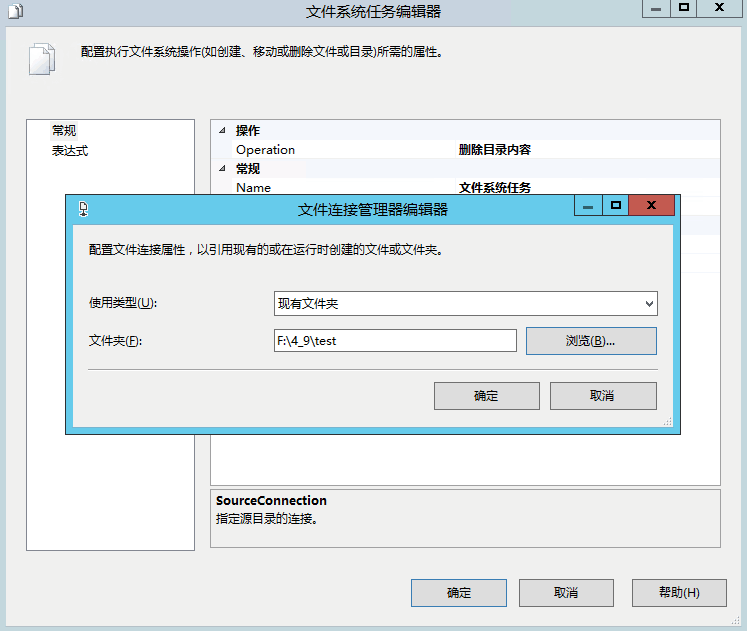
测试步骤
DECLARE @TableNames AS TABLE
(
id INT IDENTITY(1, 1),
tableName VARCHAR(100)
); DECLARE @sTableDiff NVARCHAR(1000);
DECLARE @tableName VARCHAR(100);
DECLARE @counter INT;
DECLARE @maxCount INT; INSERT INTO @TableNames
SELECT a.name
FROM sys.sysobjects a
INNER JOIN
(
SELECT object_id
FROM sys.columns
WHERE is_rowguidcol = 1
OR is_identity = 1
UNION
SELECT object_id
FROM sys.indexes
WHERE index_id = 1
) b
ON a.id = b.object_id
WHERE a.type = 'U' --and a.name='TMonStoreCheck'; SET @counter = 1; SELECT @maxCount = COUNT(name)
FROM sys.sysobjects a
INNER JOIN
(
SELECT object_id
FROM sys.columns
WHERE is_rowguidcol = 1
OR is_identity = 1
UNION
SELECT object_id
FROM sys.indexes
WHERE index_id = 1
) b
ON a.id = b.object_id
WHERE a.type = 'U' --and a.name='TMonStoreCheck'; WHILE @counter <= @maxCount
BEGIN
SELECT @tableName = tableName
FROM @TableNames
WHERE id = @counter;
SELECT @sTableDiff = ''; SET @sTableDiff
= ' "C:\Program Files\Microsoft SQL Server\130\COM\tablediff.exe" -sourceserver [faqb6n86e4.database.chinacloudapi.cn] -sourceuser ymjj -sourcepassword ***** -sourcedatabase xw_dl_1009676_01 -sourcetable ' + @tableName + ' -destinationserver [butt-joint] -destinationuser sa -destinationpassword ****** -destinationdatabase xw_dl_1009676_01 -destinationtable '+@tableName+' -f F:\4_9\test\'+@tableName EXEC master..XP_CMDSHELL @sTableDiff
SET @counter = @counter + 1;
END;
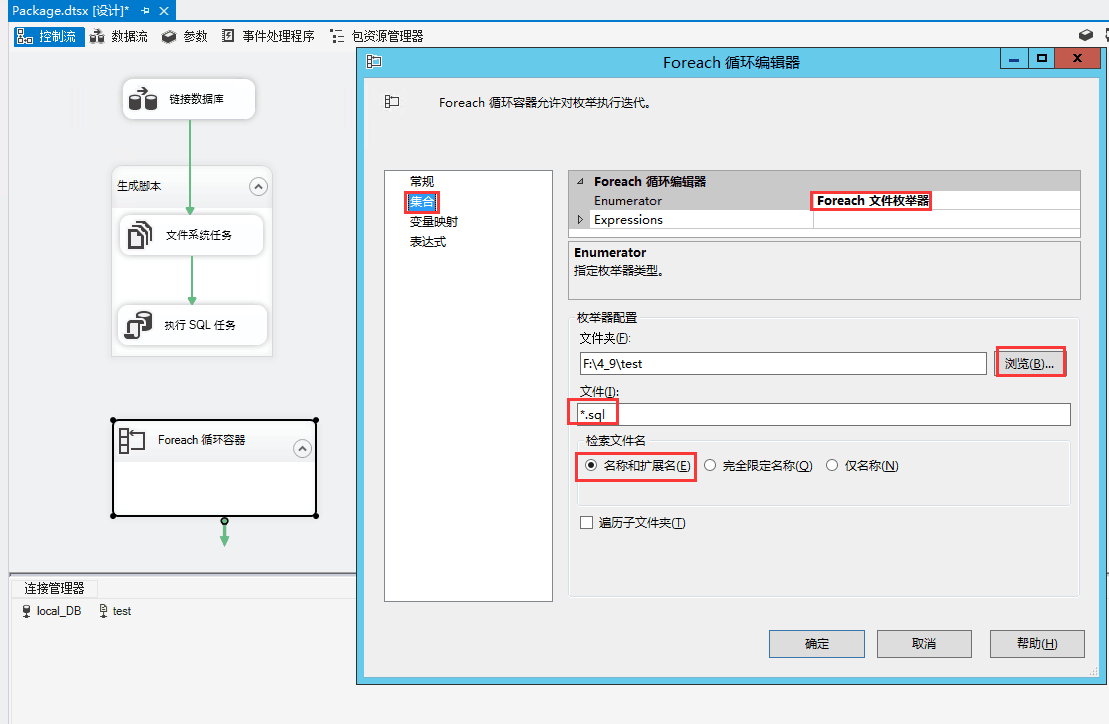

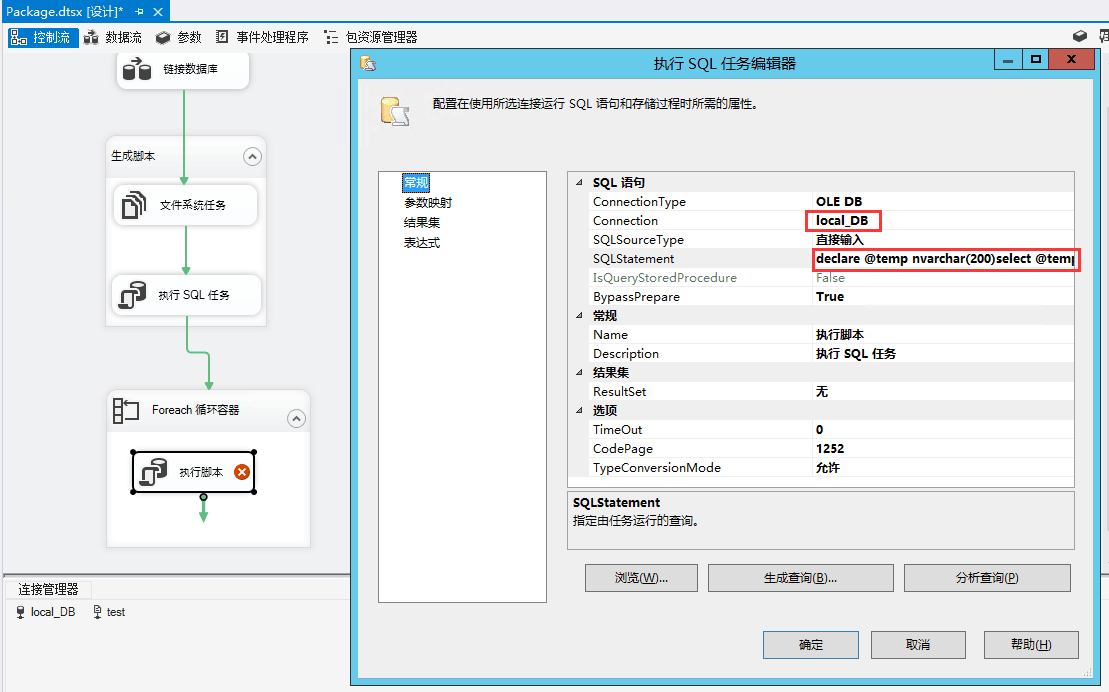
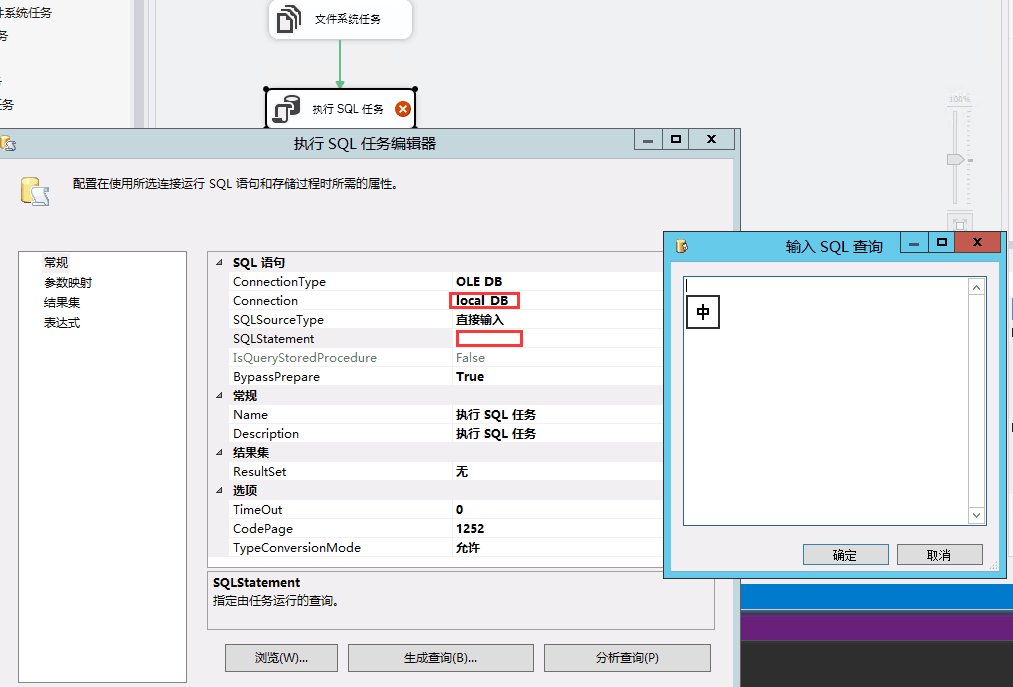
declare @temp nvarchar(200)
select @temp ='"F:\Program Files\Microsoft SQL Server\Client SDK\ODBC\130\Tools\Binn\sqlcmd.exe" -a 32576 -S butt-joint -d xw_dl_1009676_01 -i F:\4_9\test\'+ ? +' -f 65001'
EXEC master..xp_cmdshell @temp
- 可能需要安装NET Framework 3.5, 否则sqlcmd无法正常执行;
- sqlcmd 的前期测试,为了方便问题定位可以使用 -o 选项把错误信息打印出文本;
- sqlcmd 后面切记加 -f 65001,避免中文在数据库中插入后,select显示乱码的情形;
- 当插入的脚本文件非常大比如超100M+的时候建议加上-a选项,并保障内存富裕;
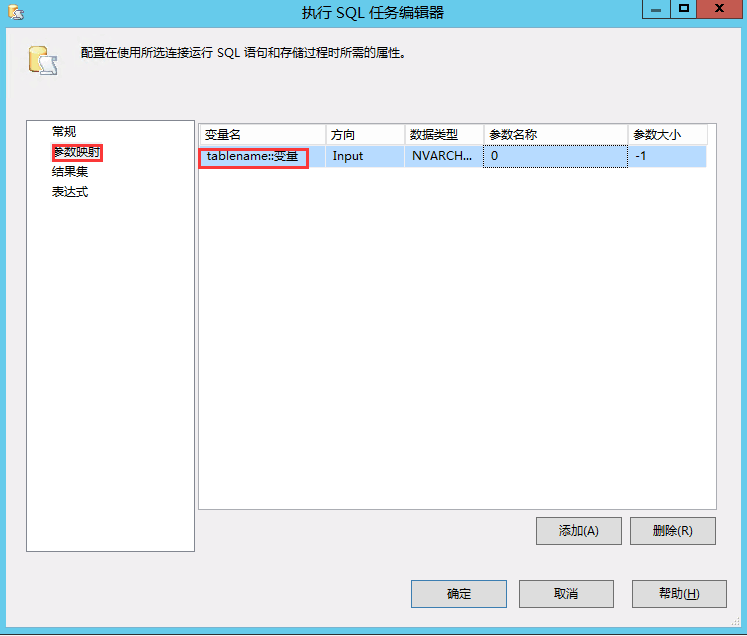
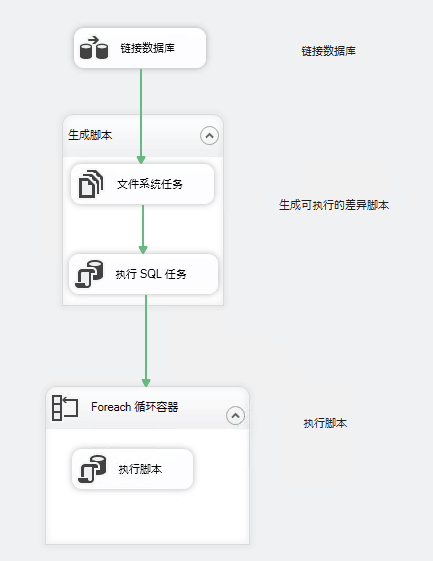
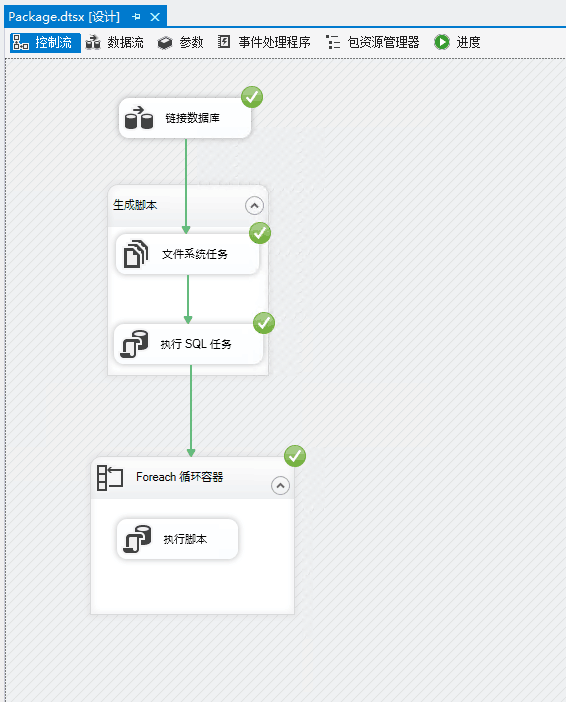
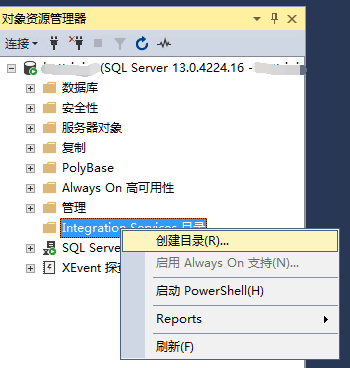
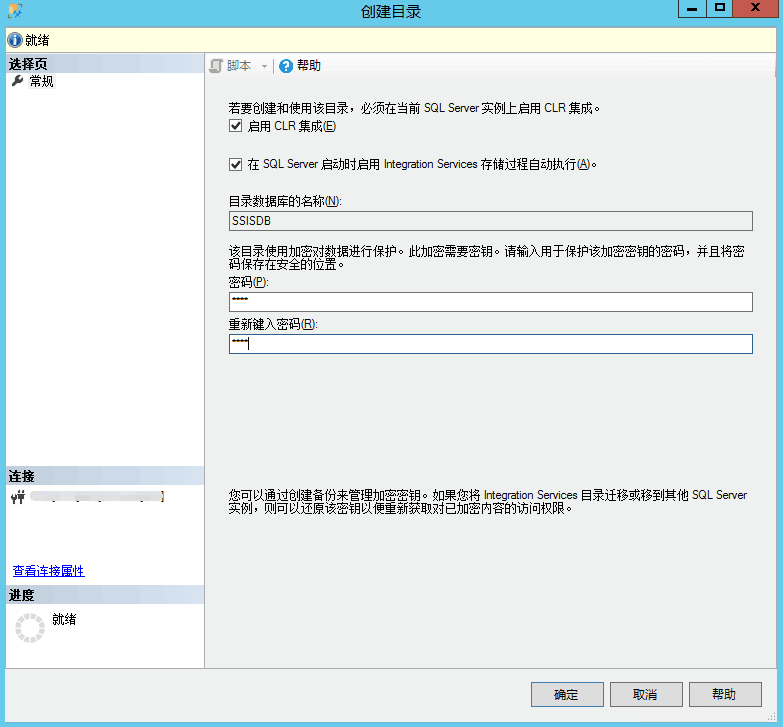
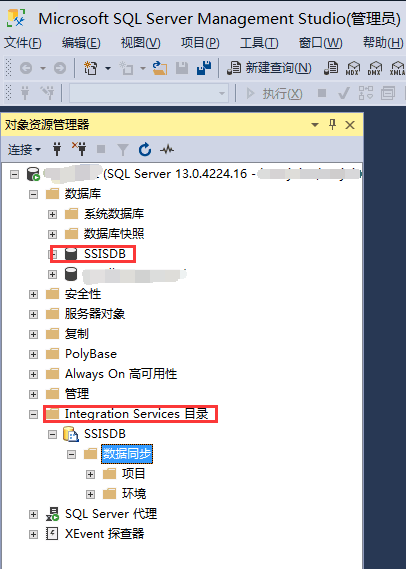
- SQL Server Integration Services 服务是否已正常启动;
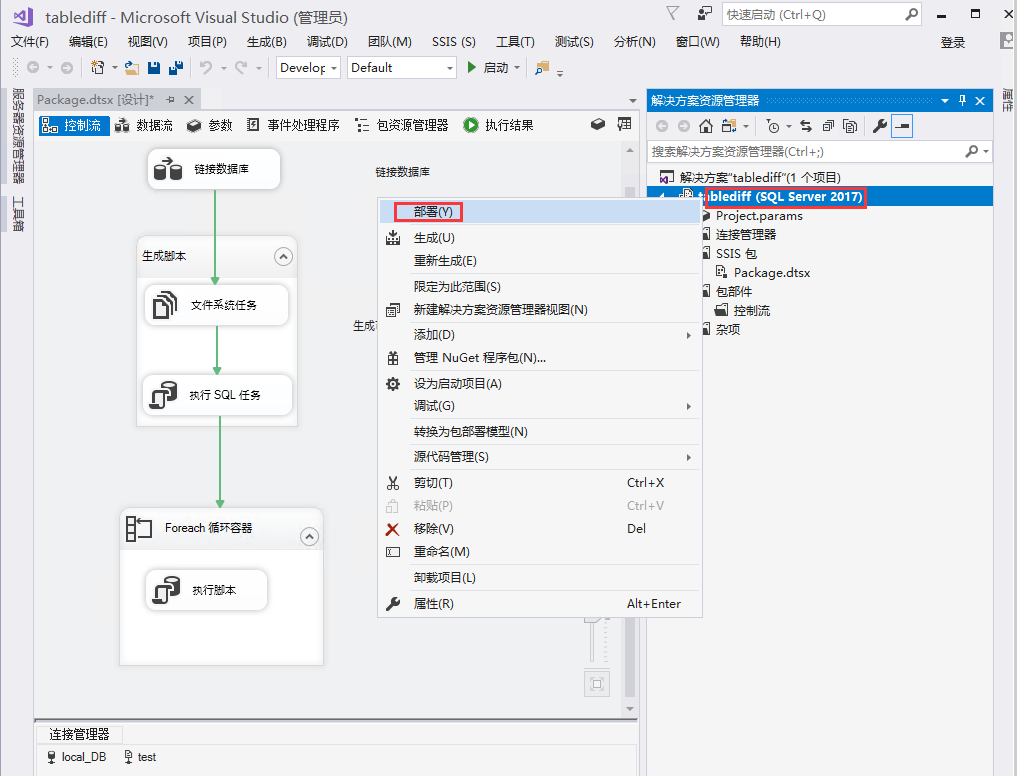
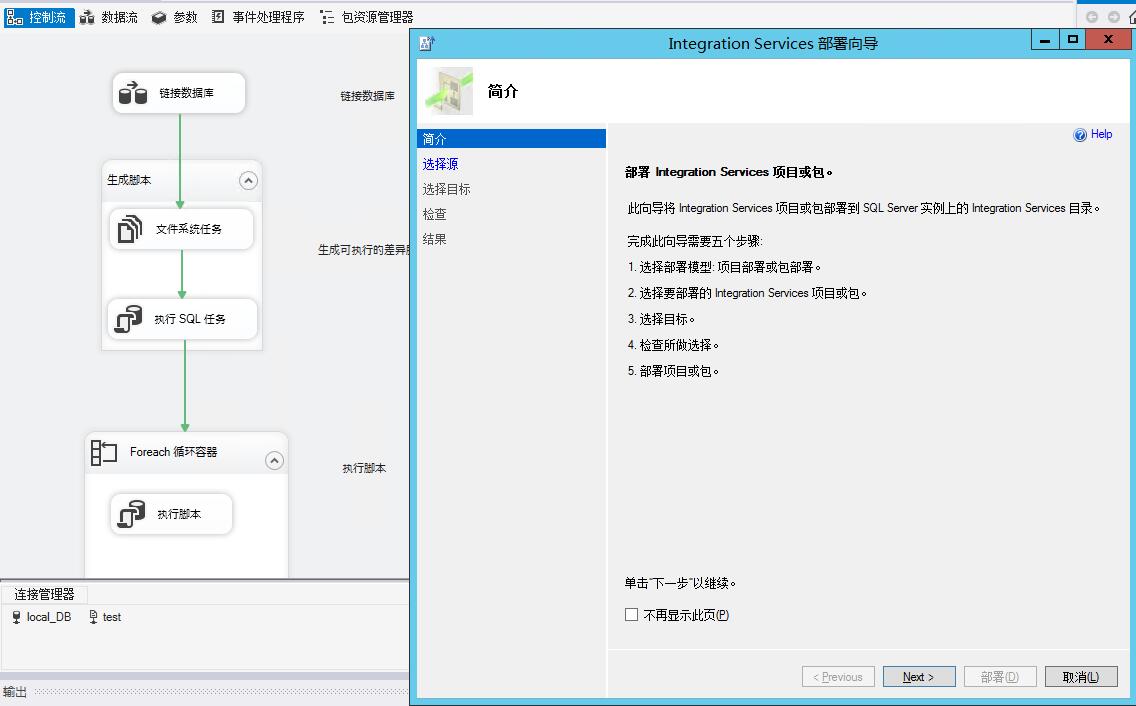
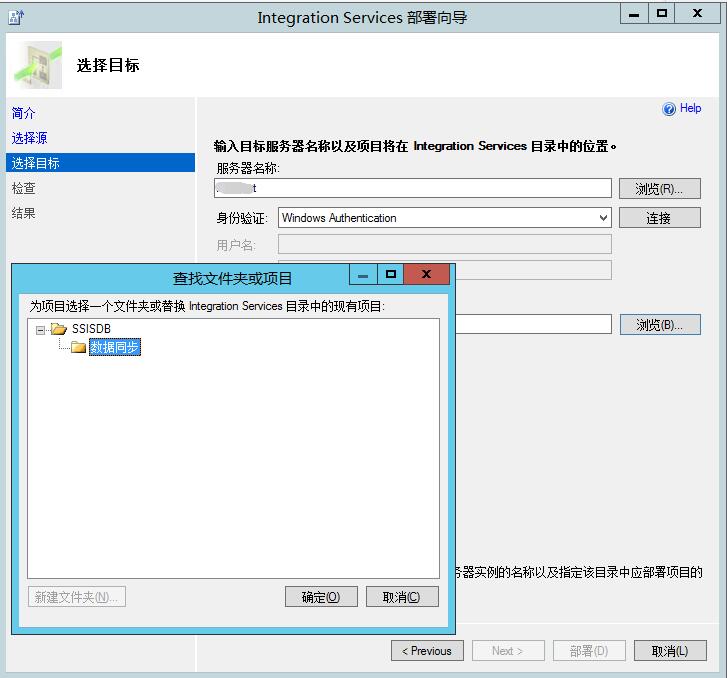
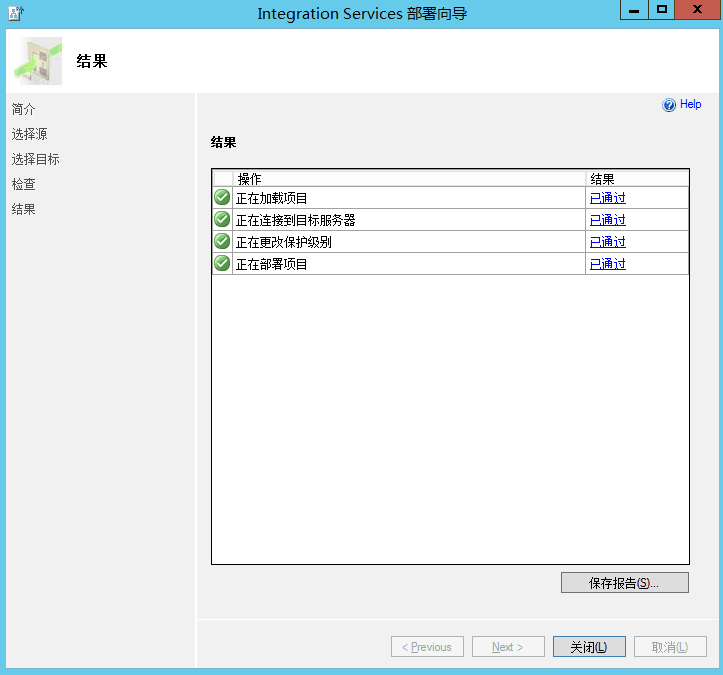
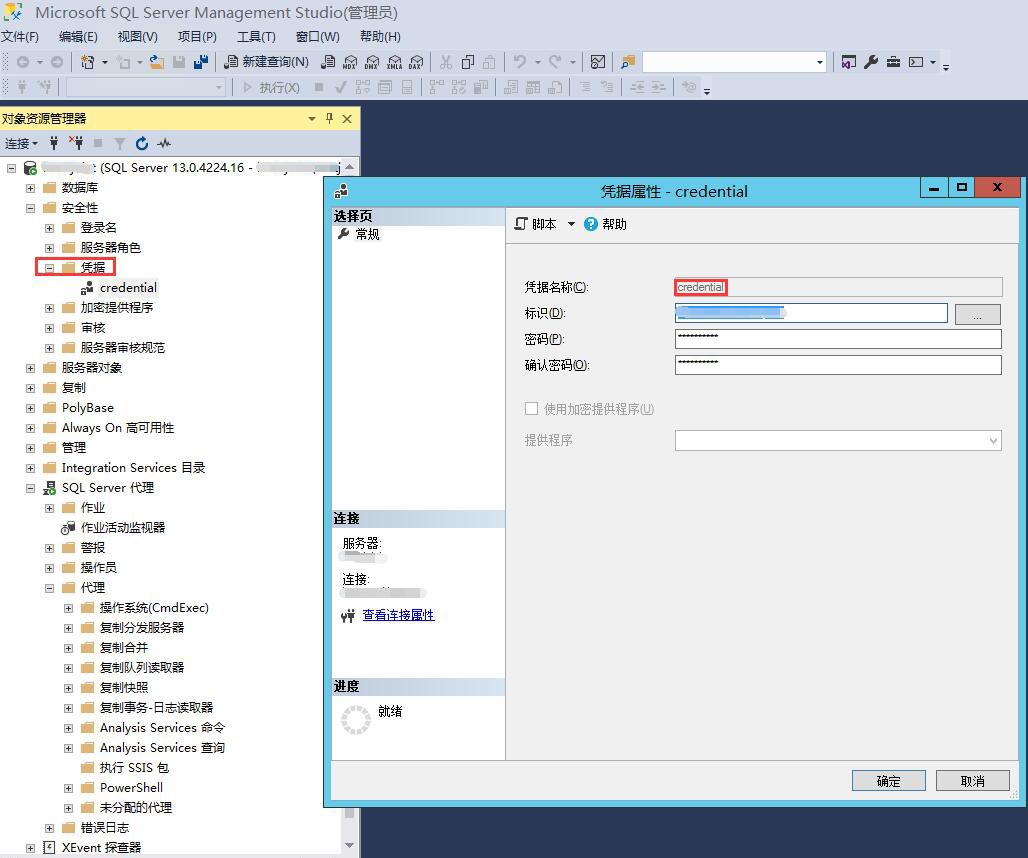
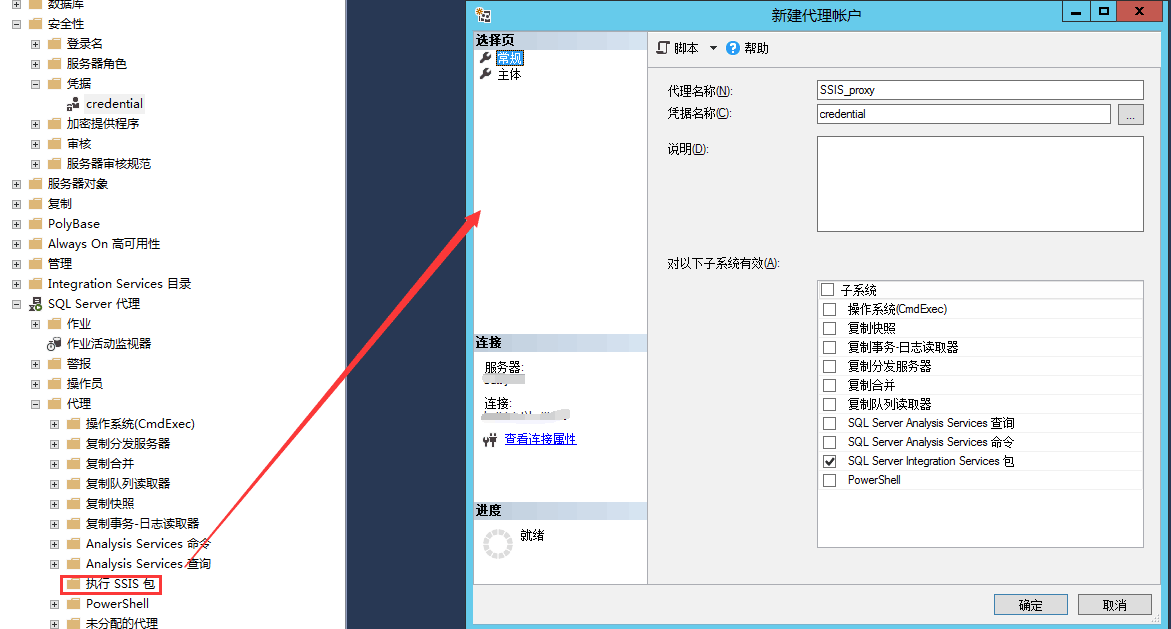
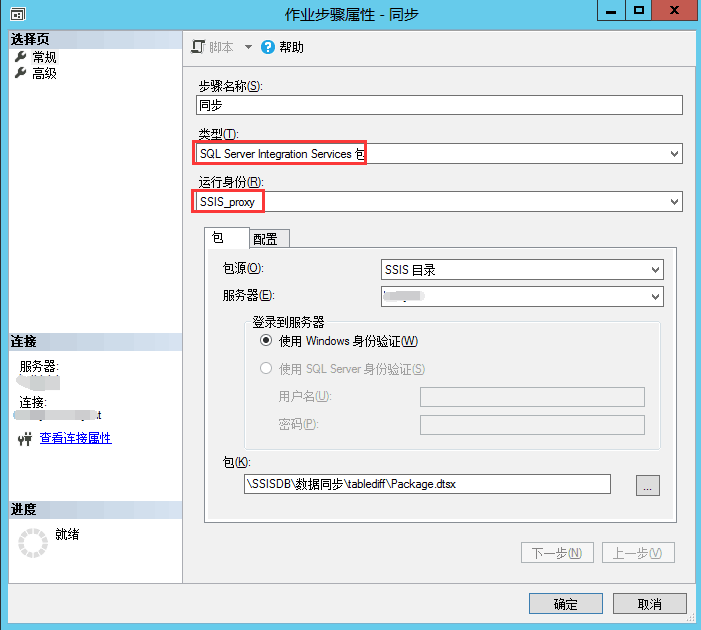
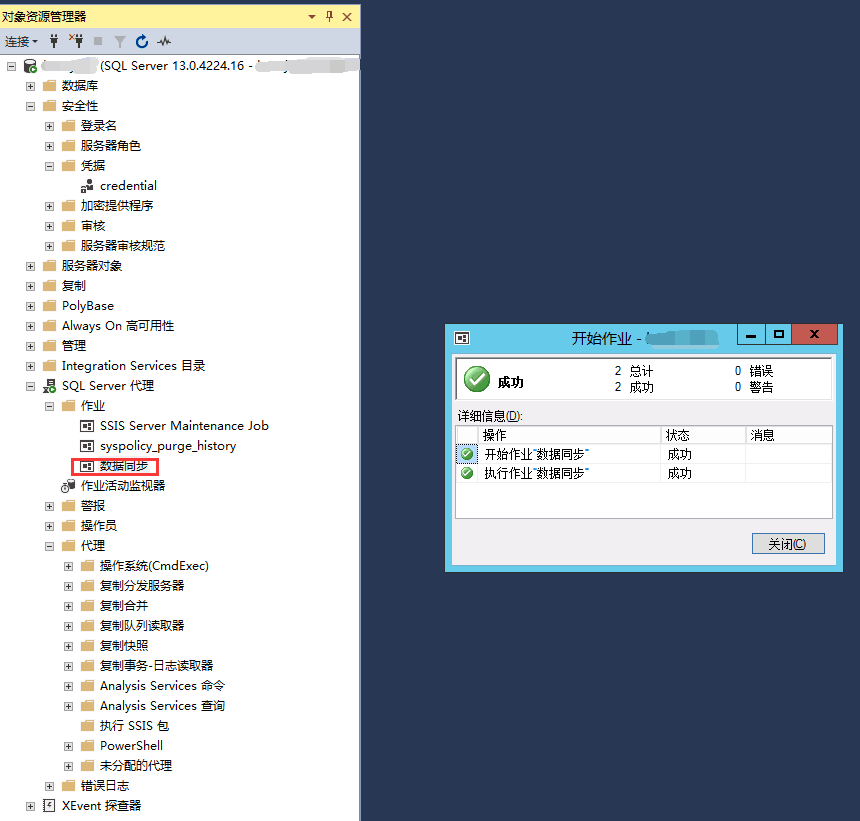
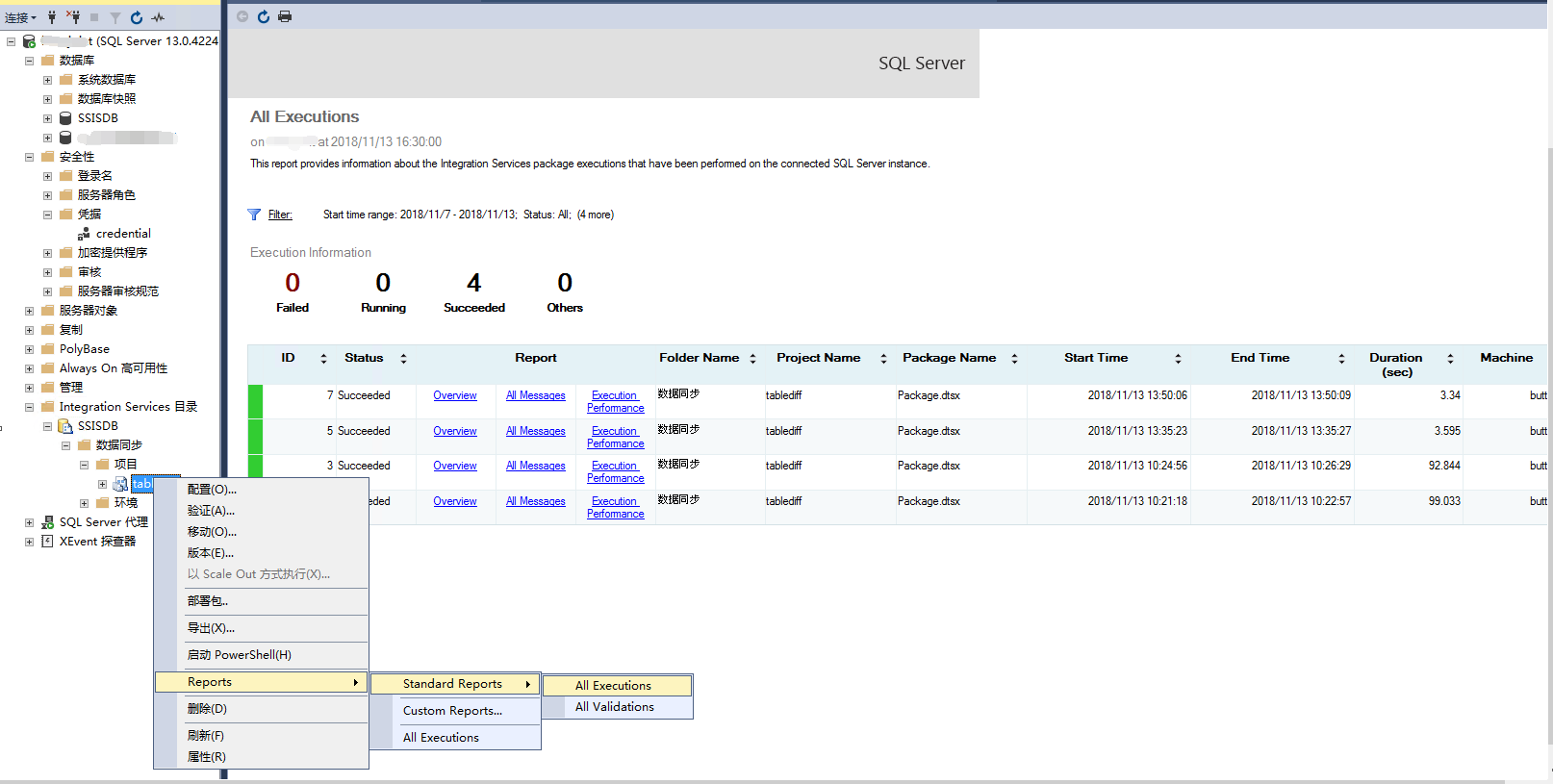

结论
- 上述是一个简单的SSIS数据同步实践,不同的业务需求的业务逻辑都可在3)中自定义;
- sqlcmd执行可能需要安装NET Framework 3.5, 否则sqlcmd无法正常执行;
- sqlcmd 的前期测试,为了方便问题定位可以使用 -o 选项把错误信息打印出文本;
- sqlcmd 后面建议加 -f 65001,避免中文在数据库中插入后,select原本是中文而显示乱码的情形;
- 确保部署的机器上SQL Server Integration Services 服务已安装并且正常启动;
- 确保SQL Server Agent 服务已正常启动;
- 在配置包的JOB的时候注意提前新建SSIS的代理,否则会有执行权限相关的问题;
- 当生成的执行脚本文件比较大的时候(比如超100M或更大),sqlcmd会报如下错误,建议在sqlcmd 加上 -a 选项,并保障执行sqlcmd的服务器有足够富裕的内存 ;
Shared Memory Provider: No process is on the other end of the pipe.
Communication link failure ---or
Msg 701, Level 17, State 139, Server *******, Line -5057
资源池“default”没有足够的系统内存来运行此查询。
后记
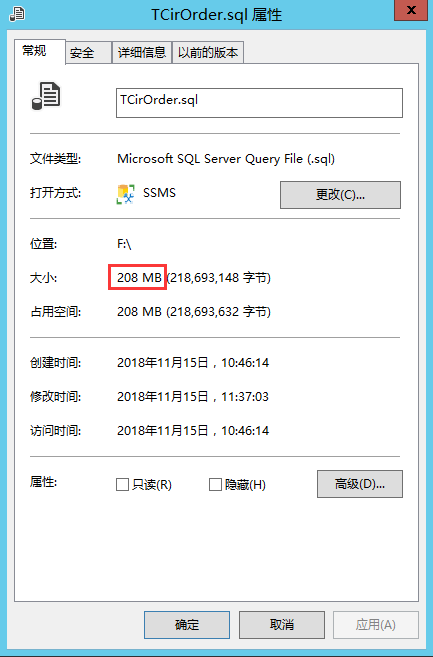
exec master..xp_cmdshell '"F:\Program Files\Microsoft SQL Server\Client SDK\ODBC\130\Tools\Binn\bcp.exe" test.dbo.TCirOrder in F:\TCirOrder.sql -E -n -C RAW -b 1000 -a 4096 -q -S butt-joint -T'
NULL
Starting copy...
SQLState = 22001, NativeError = 0
Error = [Microsoft][ODBC Driver 13 for SQL Server]String data, right truncation
SQLState = 22001, NativeError = 0
Error = [Microsoft][ODBC Driver 13 for SQL Server]String data, right truncation
SQLState = 22001, NativeError = 0
Error = [Microsoft][ODBC Driver 13 for SQL Server]String data, right truncation
SQLState = 22001, NativeError = 0
Error = [Microsoft][ODBC Driver 13 for SQL Server]String data, right truncation
SQLState = 22001, NativeError = 0
Error = [Microsoft][ODBC Driver 13 for SQL Server]String data, right truncation
SQLState = 22001, NativeError = 0
Error = [Microsoft][ODBC Driver 13 for SQL Server]String data, right truncation
SQLState = 22001, NativeError = 0
Error = [Microsoft][ODBC Driver 13 for SQL Server]String data, right truncation
SQLState = 22001, NativeError = 0
Error = [Microsoft][ODBC Driver 13 for SQL Server]String data, right truncation
SQLState = 22001, NativeError = 0
Error = [Microsoft][ODBC Driver 13 for SQL Server]String data, right truncation
SQLState = 22001, NativeError = 0
Error = [Microsoft][ODBC Driver 13 for SQL Server]String data, right truncation
NULL
BCP copy in failed
NULL
SSIS数据同步实践的更多相关文章
- 基于 MySQL Binlog 的 Elasticsearch 数据同步实践 原
一.背景 随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品.订单等数据的多维度检索. 使用 Elasticsearch 存储业务数据可以 ...
- 基于MySQL Binlog的Elasticsearch数据同步实践
一.为什么要做 随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品.订单等数据的多维度检索. 使用 Elasticsearch 存储业务数 ...
- SSIS 学习之旅 数据同步
这一章 别人也有写过但是我觉得还是写写比较好.数据同步其实就是想仿照 数据库的发布订阅功能 第一章:SSIS 学习之旅 第一个SSIS 示例(一)(上) 第二章:SSIS 学习之旅 第一个SSIS 示 ...
- 美团DB数据同步到数据仓库的架构与实践
背景 在数据仓库建模中,未经任何加工处理的原始业务层数据,我们称之为ODS(Operational Data Store)数据.在互联网企业中,常见的ODS数据有业务日志数据(Log)和业务DB数据( ...
- DB 数据同步到数据仓库的架构与实践
背景 在数据仓库建模中,未经任何加工处理的原始业务层数据,我们称之为ODS(Operational Data Store)数据.在互联网企业中,常见的ODS数据有业务日志数据(Log)和业务DB数据( ...
- 大数据实践-数据同步篇tungsten-relicator(mysql->mongo)
// mongo)";digg_bgcolor = "#FFFFFF";digg_skin = "normal"; // ]]> // [导读] ...
- ElasticStack系列之十一 & 同步 mysql 数据的实践与思考
问题 1. jdbc-input-plugin 只能实现数据库的追加,对于 elasticsearch 增量写入,但经常 jdbc 源一端的数据库可能会做数据库删除或者更新操作.这样一来数据库与搜索引 ...
- MongoDB DBA 实践5-----复制集集群的数据同步和故障转移
(1)复制集集群的数据同步 1>主节点数据库test,在其中goods集合中加入一个文档. 2>在副节点中查看 注意:SECONDARY是不允许读写的,要使用rs.slaveOk()获得读 ...
- 阿里Canal框架(数据同步中间件)初步实践
最近在工作中需要处理一些大数据量同步的场景,正好运用到了canal这款数据库中间件,因此特意花了点时间来进行该中间件的的学习和总结. 背景介绍 早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存 ...
随机推荐
- Ubuntu下PHP+MySQL+Apache+PHPStorm的安装和配置
粘贴自:https://www.jianshu.com/p/a6a0d2a29591 1.Apache的安装: $ sudo apt-get update $ sudo apt-get install ...
- 面试题——常见的gc算法有哪些?
常见的gc算法有哪些? java garbage collection是一个自动进程,用于管理程序使用的运行时内存.通过自动执行JVM,可以减轻程序中分配和释放内存资源的开销. 垃圾回收机制是由垃圾回 ...
- 使用ADB命令写Android自动化测试脚本
使用脚本来执行测试的特点: ●书写方便 ●基本上可以实现90%以上的功能性覆盖 ●测试结果需要通过自己观察整个过程和日志文件来得出的 ●有些外部的动作,脚本是无法实现的,比如录入指纹 ●只适配特定尺寸 ...
- Linux查找文件内容小技巧
目录 grep ag linux系统查找文件内容最常见的命令有grep和ag grep grep是比较常见的查找命令 # 在当前目录的py文件里查找所有相关内容 grep -a "broad ...
- 题解 [CF916E] Jamie and Tree
题面 解析 这题考试时刚了四个小时. 结果还是爆零了 主要就是因为\(lca\)找伪了. 我们先考虑没有操作1,那就是裸的线段树. 在换了根以后,主要就是\(lca\)不好找(分类讨论伪了). 我们将 ...
- Codeforces Round #453 (Div. 1) 901C C. Bipartite Segments
题 http://codeforces.com/contest/901/problem/C codeforces 901C 解 首先因为图中没有偶数长度的环,所以: 1.图中的环长度全是奇数,也就是说 ...
- kubernetes1.11.1 部署prometheus
部署前提:已经安装好了kubernetes的集群,版本是1.11.1,是用kubeadm部署的. 2台虚拟机:master:172.17.1.36 node1:172.17.1.40 pro ...
- BZOJ 2100: [Usaco2010 Dec]Apple Delivery spfa
由于是无向图,所以可以枚举两个终点,跑两次最短路来更新答案. #include <queue> #include <cstdio> #include <cstring&g ...
- NetMQ介绍
NetMQ 是 ZeroMQ的C#移植版本. 一.ZeroMQ ZeroMQ(Ø)是一个轻量级的消息内核,它是对标准socket接口的扩展.它提供了一种异步消息队列,多消息模式,消息过滤(订阅),对 ...
- java学习第一天:环境的配置
1.下载JDK,当前版本下载地址为:http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.htm ...