Tensorflow&CNN:验证集预测与模型评价
版权声明:本文为博主原创文章,转载 请注明出处:https://blog.csdn.net/sc2079/article/details/90480140
- 写在前面
本科毕业设计终于告一段落了。特写博客记录做毕业设计(路面裂纹识别)期间的踩过的坑和收获。希望对你有用。
目前有:
1.Tensorflow&CNN:裂纹分类
2.Tensorflow&CNN:验证集预测与模型评价
3.PyQt5多个GUI界面设计
本篇博客主要是评估所训练出来的CNN分类模型的性能。主要有几点:验证集预测、多分类混淆矩阵、多分类评价指标、预测结果堆叠图。
- 环境配置安装
运行环境:Python3.6、Spyder
依赖模块:Skimage、Tensorflow(CPU)、Numpy 、Matlpotlib等
- 开始工作
1.读取验证集图片
在验证集数据目录下有五个文件夹,分别以数字0-4命名,代表裂纹类型。其中,每个文件夹下各有100张图片。
def read_img(path):
cate=[path+x for x in os.listdir(path)]
imgs=[]
labels=[]
for idx,folder in enumerate(cate):
for im in glob.glob(folder+'/*.jpg'):
#print('reading the images:%s'%(im))
img=io.imread(im)
img=transform.resize(img,(100,100))
#img=normlization(img)
imgs.append(img)
labels.append(idx)
return np.asarray(imgs,np.float32),np.asarray(labels,np.int32)
path='d://test//img2//'
data,label=read_img(path)
#打乱顺序
num_example=data.shape[0]
arr=np.arange(num_example)
np.random.shuffle(arr)
data=data[arr]
label=label[arr]
x_val=data
y_val=list(label)
y_val即为每张图片的实际裂纹类型所对应的数字标签。
2.裂纹类型预测
def prediction(data):
with tf.Session() as sess:
model_path='d://test//model2'
saver = tf.train.import_meta_graph(model_path+'//model-13-2019_05_01.meta')
saver.restore(sess,tf.train.latest_checkpoint(model_path+'./')) # 加载最新模型到当前环境中
graph = tf.get_default_graph()
x = graph.get_tensor_by_name("x:0")
feed_dict = {x:data}
logits = graph.get_tensor_by_name("logits_eval:0")
classification_result = sess.run(logits,feed_dict)
#根据索引通过字典对应裂纹的分类
output = tf.argmax(classification_result,1).eval()
return output
tf.reset_default_graph() #清除过往tensorflow数据记录
sess=tf.Session()
sess.run(tf.global_variables_initializer())
y_predict=prediction(x_val)
输出为0-4的数字,分别代表预测结果为纵向裂纹、横向裂纹、块状裂纹、龟裂裂纹、无裂纹。
3.混淆矩阵绘制
一般二分类问题的混淆矩阵如下所示:
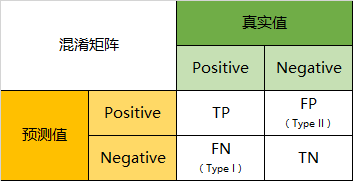
现绘制多分类的混淆矩阵,方法如下:
def plot_confusion_matrix(confusion_mat):
plt.imshow(confusion_mat,interpolation='nearest',cmap=plt.cm.Paired)
plt.title('Confusion Matrix')
plt.colorbar()
tick_marks=np.arange(5)
plt.xticks(tick_marks,tick_marks)
plt.yticks(tick_marks,tick_marks)
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.show()
confusion_matrix = tf.contrib.metrics.confusion_matrix(y_val,y_predict, num_classes=None, dtype=tf.int32, name=None, weights=None)
confusion_matrix = sess.run(confusion_matrix)
plot_confusion_matrix(confusion_matrix)
结果如下:

一般来说,混淆矩阵对角线颜色越深,说明预测结果越准确,所训练的模型的泛化性能越强。由结果可以看到,其对角线颜色较深,模型较好。
4.评价指标
二分类问题主要有以下指标:

而对于多分类问题,通常有”宏“和”微“之分。这里我使用的是宏指标,如下:
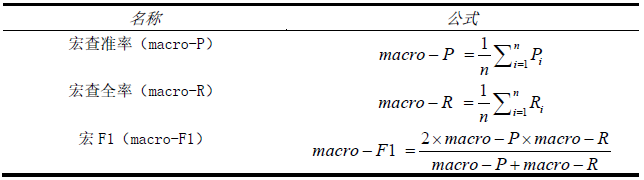
实现方法如下:
accu = [0,0,0,0,0]
column = [0,0,0,0,0]
line = [0,0,0,0,0]
recall =[0,0,0,0,0] #召回率
precision = [0,0,0,0,0] #精准率
accuracy = 0 #准确率
Macro_P = 0 #宏查准率(宏精准率)
Macro_R=0 #宏查全率(宏召回率)
#准确率
for i in range(0,5):
accu[i] = confusion_matrix[i][i]
accuracy+= float(accu[i])/len(y_val)
#宏召回率
for i in range(0,5):
for j in range(0,5):
column[i]+=confusion_matrix[j][i]
if column[i] != 0:
recall[i]=float(accu[i])/column[i]
Macro_R=np.array(recall).mean()
#宏精准率
for i in range(0,5):
for j in range(0,5):
line[i]+=confusion_matrix[i][j]
if line[i] != 0:
precision[i]=float(accu[i])/line[i]
Macro_P = np.array(precision).mean()
#宏F1
Macro_F1 = (2 * (Macro_P * Macro_R)) / (Macro_P+Macro_R)
结果如下:
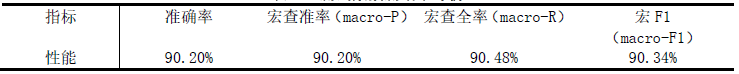
可以看出,各指标都在90%以上,模型较好。
5.绘制堆叠条形图
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
label_list = ['纵向裂纹', '横向裂纹', '块状裂纹', '龟裂裂纹','无裂纹']
num_list1 = accu
num_list2 = [100-i for i in accu]
x = range(len(num_list1))
rects1 = plt.bar(left=x, height=num_list1, width=0.45, alpha=0.8, color='green', label="预测正确")
rects2 = plt.bar(left=x, height=num_list2, width=0.45, color='red', label="预测错误", bottom=num_list1)
plt.ylim(0, 120)
#for a,b in enumerate(num_list1):
# plt.text(b+1, a - 13, '%s' % b)
plt.ylabel("数量")
plt.xticks(x, label_list)
plt.xlabel("裂纹类型")
plt.title("测试集预测结果堆叠条形图")
plt.legend()
plt.show()
结果如下:

-总结
基本能对分类模型性能做简单评价,还未绘制其ROC曲线。
-鸣谢
1.模型评估与选择
2.实习点滴(11)–TensorFlow快速计算“多分类问题”的混淆矩阵以及精确率、召回率、F1值、准确率
Tensorflow&CNN:验证集预测与模型评价的更多相关文章
- Tensorflow&CNN:裂纹分类
版权声明:本文为博主原创文章,转载 请注明出处:https://blog.csdn.net/sc2079/article/details/90478551 - 写在前面 本科毕业设计终于告一段落了.特 ...
- 在进行机器学习建模时,为什么需要验证集(validation set)?
在进行机器学习建模时,为什么需要评估集(validation set)? 笔者最近有一篇文章被拒了,其中有一位审稿人提到论文中的一个问题:”应该在验证集上面调整参数,而不是在测试集“.笔者有些不明白为 ...
- 训练集(train set) 验证集(validation set) 测试集(test set)
转自:http://www.cnblogs.com/xfzhang/archive/2013/05/24/3096412.html 在有监督(supervise)的机器学习中,数据集常被分成2~3个, ...
- 使用sklearn进行数据挖掘-房价预测(6)—模型调优
通过上一节的探索,我们会得到几个相对比较满意的模型,本节我们就对模型进行调优 网格搜索 列举出参数组合,直到找到比较满意的参数组合,这是一种调优方法,当然如果手动选择并一一进行实验这是一个十分繁琐的工 ...
- Android+TensorFlow+CNN+MNIST 手写数字识别实现
Android+TensorFlow+CNN+MNIST 手写数字识别实现 SkySeraph 2018 Email:skyseraph00#163.com 更多精彩请直接访问SkySeraph个人站 ...
- 【ML入门系列】(一)训练集、测试集和验证集
训练集.验证集和测试集这三个名词在机器学习领域极其常见,但很多人并不是特别清楚,尤其是后两个经常被人混用. 在有监督(supervise)的机器学习中,数据集常被分成2~3个,即:训练集(train ...
- [机器学习] 训练集(train set) 验证集(validation set) 测试集(test set)
在有监督(supervise)的机器学习中,数据集常被分成2~3个即: 训练集(train set) 验证集(validation set) 测试集(test set) 一般需要将样本分成独立的三部分 ...
- AI---训练集(train set) 验证集(validation set) 测试集(test set)
在有监督(supervise)的机器学习中,数据集常被分成2~3个即: 训练集(train set) 验证集(validation set) 测试集(test set) 一般需要将样本分成独立的三部分 ...
- ML基础 : 训练集,验证集,测试集关系及划分 Relation and Devision among training set, validation set and testing set
首先三个概念存在于 有监督学习的范畴 Training set: A set of examples used for learning, which is to fit the parameters ...
随机推荐
- 【JS新手教程】replace替换一个字符串中所有的某单词
JS中的replace方法可以替换一个字符串中的单词.语句的格式是: 需要改的字符串.replace(字符串或正则表达式,替换成的字符串) 如果第一个参数用字符串,默认是找到该字符串中的第一个匹配的字 ...
- react 生命周期图解
参考地址:https://www.cnblogs.com/gdsblog/p/7348375.html
- 常见问题:MySQL/排序
MySQL的排序分为两种,通过排序操作和按索引扫描排序. 按索引顺序扫描是一种很高效的方式,但使用的条件较为严格,只有orderby语句使用索引最左前列,或where语句与orderby语句条件列组合 ...
- IDEA 创建JAVA Maven Web 工程 不能建Sevlet文件
JAVA目录下建包而不是文件夹 需要添加依赖 <dependency> <groupId>javax.servlet</groupId> <artifactI ...
- 2019.10.28 IDEA入门指南(很多人问补充一篇)
Idea快速入门指南 1.安装 1.1.安装 我们使用的是最新的2017.3.4版本: 双击打开, 选择一个目录,最好不要中文和空格: 然后选择桌面快捷方式,请选择64位: 然后选择安装: 开始安装: ...
- Python23之内置函数filter()和map()
首先我们了解一个概念:迭代 迭代是访问集合元素的⼀种⽅式.迭代器是⼀个可以记住遍历的位置的对象.迭代器对象从集合的第⼀个元素开始访问,直到所有的元素被访问完结束.迭代器只能往前不会后退. 我们已经知道 ...
- FZU2018级算法第五次作业 m_sort(归并排序或线段树求逆序对)
首先对某人在未经冰少允许情况下登录冰少账号原模原样复制其代码并且直接提交的赤裸裸剽窃行为,并且最终被评为优秀作业提出抗议! 题目大意: 给一个数组含n个数(1<=n<=5e5),求使用冒泡 ...
- 以php中的比较运算符操作整型,浮点型,字符串型,布尔型和空类型
字符,数字,特殊符号的比较依赖ASC II表,本表原先有127个,后来又扩充了一些,里面包含了奇奇奇怪的符号. ASC II表 https://baike.baidu.com/item/ASCII/3 ...
- matplotlib笔记3
关于matplotlib的绘制图形的基本代码,我们可以参照下面的连接 https://matplotlib.org/gallery/index.html https://matplotlib.org/ ...
- Codeforces Round #421 (Div. 1) (BC)
1. 819B Mister B and PR Shifts 大意: 给定排列$p$, 定义排列$p$的特征值为$\sum |p_i-i|$, 可以循环右移任意位, 求最小特征值和对应移动次数. 右移 ...