Hive 系列(五)—— Hive 分区表和分桶表
一、分区表
1.1 概念
Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大。
分区为 HDFS 上表目录的子目录,数据按照分区存储在子目录中。如果查询的 where 字句的中包含分区条件,则直接从该分区去查找,而不是扫描整个表目录,合理的分区设计可以极大提高查询速度和性能。
这里说明一下分区表并 Hive 独有的概念,实际上这个概念非常常见。比如在我们常用的 Oracle 数据库中,当表中的数据量不断增大,查询数据的速度就会下降,这时也可以对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据存放到多个表空间(物理文件上),这样查询数据时,就不必要每次都扫描整张表,从而提升查询性能。
1.2 使用场景
通常,在管理大规模数据集的时候都需要进行分区,比如将日志文件按天进行分区,从而保证数据细粒度的划分,使得查询性能得到提升。
1.3 创建分区表
在 Hive 中可以使用 PARTITIONED BY 子句创建分区表。表可以包含一个或多个分区列,程序会为分区列中的每个不同值组合创建单独的数据目录。下面的我们创建一张雇员表作为测试:
CREATE EXTERNAL TABLE emp_partition(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
PARTITIONED BY (deptno INT) -- 按照部门编号进行分区
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/hive/emp_partition';1.4 加载数据到分区表
加载数据到分区表时候必须要指定数据所处的分区:
# 加载部门编号为20的数据到表中
LOAD DATA LOCAL INPATH "/usr/file/emp20.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=20)
# 加载部门编号为30的数据到表中
LOAD DATA LOCAL INPATH "/usr/file/emp30.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=30)1.5 查看分区目录
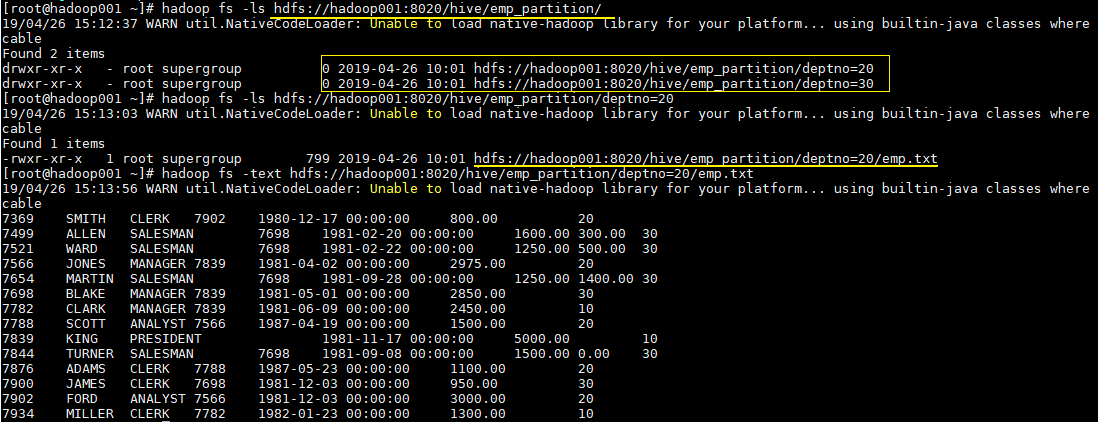
这时候我们直接查看表目录,可以看到表目录下存在两个子目录,分别是 deptno=20 和 deptno=30,这就是分区目录,分区目录下才是我们加载的数据文件。
# hadoop fs -ls hdfs://hadoop001:8020/hive/emp_partition/这时候当你的查询语句的 where 包含 deptno=20,则就去对应的分区目录下进行查找,而不用扫描全表。
二、分桶表
1.1 简介
分区提供了一个隔离数据和优化查询的可行方案,但是并非所有的数据集都可以形成合理的分区,分区的数量也不是越多越好,过多的分区条件可能会导致很多分区上没有数据。同时 Hive 会限制动态分区可以创建的最大分区数,用来避免过多分区文件对文件系统产生负担。鉴于以上原因,Hive 还提供了一种更加细粒度的数据拆分方案:分桶表 (bucket Table)。
分桶表会将指定列的值进行哈希散列,并对 bucket(桶数量)取余,然后存储到对应的 bucket(桶)中。
1.2 理解分桶表
单从概念上理解分桶表可能会比较晦涩,其实和分区一样,分桶这个概念同样不是 Hive 独有的,对于 Java 开发人员而言,这可能是一个每天都会用到的概念,因为 Hive 中的分桶概念和 Java 数据结构中的 HashMap 的分桶概念是一致的。
当调用 HashMap 的 put() 方法存储数据时,程序会先对 key 值调用 hashCode() 方法计算出 hashcode,然后对数组长度取模计算出 index,最后将数据存储在数组 index 位置的链表上,链表达到一定阈值后会转换为红黑树 (JDK1.8+)。下图为 HashMap 的数据结构图:
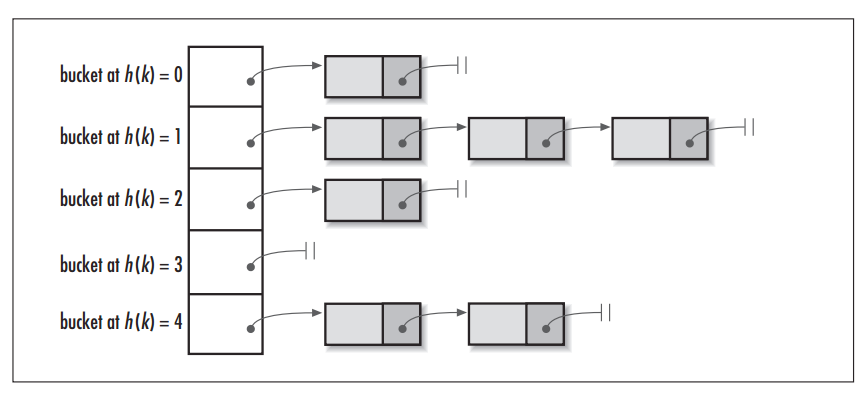
图片引用自:HashMap vs. Hashtable
1.3 创建分桶表
在 Hive 中,我们可以通过 CLUSTERED BY 指定分桶列,并通过 SORTED BY 指定桶中数据的排序参考列。下面为分桶表建表语句示例:
CREATE EXTERNAL TABLE emp_bucket(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
CLUSTERED BY(empno) SORTED BY(empno ASC) INTO 4 BUCKETS --按照员工编号散列到四个 bucket 中
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/hive/emp_bucket';1.4 加载数据到分桶表
这里直接使用 Load 语句向分桶表加载数据,数据时可以加载成功的,但是数据并不会分桶。
这是由于分桶的实质是对指定字段做了 hash 散列然后存放到对应文件中,这意味着向分桶表中插入数据是必然要通过 MapReduce,且 Reducer 的数量必须等于分桶的数量。由于以上原因,分桶表的数据通常只能使用 CTAS(CREATE TABLE AS SELECT) 方式插入,因为 CTAS 操作会触发 MapReduce。加载数据步骤如下:
1. 设置强制分桶
set hive.enforce.bucketing = true; --Hive 2.x 不需要这一步在 Hive 0.x and 1.x 版本,必须使用设置 hive.enforce.bucketing = true,表示强制分桶,允许程序根据表结构自动选择正确数量的 Reducer 和 cluster by column 来进行分桶。
2. CTAS导入数据
INSERT INTO TABLE emp_bucket SELECT * FROM emp; --这里的 emp 表就是一张普通的雇员表可以从执行日志看到 CTAS 触发 MapReduce 操作,且 Reducer 数量和建表时候指定 bucket 数量一致:

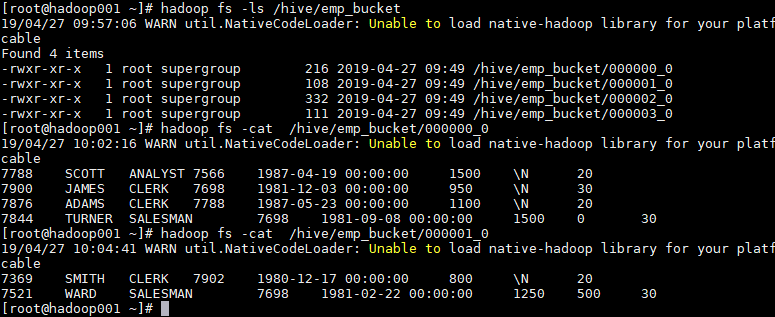
1.5 查看分桶文件
bucket(桶) 本质上就是表目录下的具体文件:
三、分区表和分桶表结合使用
分区表和分桶表的本质都是将数据按照不同粒度进行拆分,从而使得在查询时候不必扫描全表,只需要扫描对应的分区或分桶,从而提升查询效率。两者可以结合起来使用,从而保证表数据在不同粒度上都能得到合理的拆分。下面是 Hive 官方给出的示例:
CREATE TABLE page_view_bucketed(
viewTime INT,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING )
PARTITIONED BY(dt STRING)
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;此时导入数据时需要指定分区:
INSERT OVERWRITE page_view_bucketed
PARTITION (dt='2009-02-25')
SELECT * FROM page_view WHERE dt='2009-02-25';参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Hive 系列(五)—— Hive 分区表和分桶表的更多相关文章
- Hive 学习之路(五)—— Hive 分区表和分桶表
一.分区表 1.1 概念 Hive中的表对应为HDFS上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为HDFS上表目录的子目录,数据按照分区存储在子目录中.如 ...
- 入门大数据---Hive分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- 一起学Hive——创建内部表、外部表、分区表和分桶表及导入数据
Hive本身并不存储数据,而是将数据存储在Hadoop的HDFS中,表名对应HDFS中的目录/文件.根据数据的不同存储方式,将Hive表分为外部表.内部表.分区表和分桶表四种数据模型.每种数据模型各有 ...
- Hive(六)【分区表、分桶表】
目录 一.分区表 1.本质 2.创建分区表 3.加载数据到分区表 4.查看分区 5.增加分区 6.删除分区 7.二级分区 8.分区表和元数据对应得三种方式 9.动态分区 二.分桶表 1.创建分桶表 2 ...
- hive 分区表和分桶表
1.创建分区表 hive> create table weather_list(year int,data int) partitioned by (createtime string,area ...
- Hive 教程(四)-分区表与分桶表
在 hive 中分区表是很常用的,分桶表可能没那么常用,本文主讲分区表. 概念 分区表 在 hive 中,表是可以分区的,hive 表的每个区其实是对应 hdfs 上的一个文件夹: 可以通过多层文件夹 ...
- Hive SQL之分区表与分桶表
Hive sql是Hive 用户使用Hive的主要工具.Hive SQL是类似于ANSI SQL标准的SQL语言,但是两者有不完全相同.Hive SQL和Mysql的SQL方言最为接近,但是两者之间也 ...
- 第2节 hive基本操作:11、hive当中的分桶表以及修改表删除表数据加载数据导出等
分桶表 将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去 开启hive的桶表功能 set hive.enforce.bucketing= ...
- hive中的分桶表
桶表也是一种用于优化查询而设计的表类型.创建通表时,指定桶的个数.分桶的依据字段,hive就可以自动将数据分桶存储.查询时只需要遍历一个桶里的数据,或者遍历部分桶,这样就提高了查询效率 ------创 ...
随机推荐
- MyBatis 使用枚举或其他对象
From<Mybatis从入门到精通> 1.笔记: <!-- 6.3 使用枚举或者其他对象 6.3.1 使用MyBatis提供的枚举处理器 不懂: 因为枚举除了本身的字面值外,还可以 ...
- 【题解】搬书-C++
搬书 Description 陈老师桌上的书有三堆,每一堆都有厚厚的一叠,你想逗一下陈老师,于是你设计一个最累的方式给他,让他把书 拿下来给同学们.若告诉你这三堆分别有i,j,k本书,以及每堆从下到上 ...
- Oracle 开发使用笔记一
1 前段时间换了新公司,工作一直很忙,没什么时间做总结! 关于几个知识点简单做下总结: 1绑定变量的使用: 1)使用几次,在后面的using中要声明几次,使用的顺序要对应声明的顺序 2 存储过程中执行 ...
- Java中的单例模式(Singleton Pattern in Java)
Introduction 对于系统中的某个类来说,只有一个实例是很重要的,比如只有一个timer和ID Producer.又比如在服务器程序中,配置信息保留在一个文件中,这些配置信息由一个单例对象统一 ...
- Excel催化剂开源第19波-一些虽简单但不知道时还是很难受的知识点
通常许多的知识都是在知与不知之间,不一定非要很深奥,特别是Excel这样的应用工具层面,明明已经摆在那里,你不知道时,永远地不知道,知道了,简单学习下就已经实现出最终的功能效果. 在程序猿世界里,也是 ...
- 求1到n的质数个数和O(n)
也许更好的阅读体验 \(\mathcal{AIM}\) 我们知道: 对于一个合数\(x\) 有\(x=p^{a_1}_1*p^{a_2}_2*...*p^{a_n}_n\) 现在给出一个\(n\) 求 ...
- sklearn使用技巧
sklearn使用技巧 sklearn上面对自己api的解释已经做的淋漓尽致,但对于只需要短时间入手的同学来说,还是比较复杂的,下面将会列举sklearn的使用技巧. 预处理 主要在sklearn.p ...
- 前端响应式のmedia文件分离
响应式cssのmedia文件分离 media简介 1.媒体查询,添加自CSS3 2.一个媒体查询由一个可选的媒体类型和零个或多个使用媒体功能的限制了样式表范围的表达式组成,允许内容的呈现针对一个特定范 ...
- Java EE编程思想
组件--容器 编程思想 组件:由程序员根据特定的业务需求编程实现. 容器:组件的运行环境,为组件提供必须的底层基础功能. 组件通过调用容器提供的标准服务来与外界交互,容器提供的标准服务有命名服务.数据 ...
- HTML--CSS样式表的基本概念
CSS(Cascading Style Sheet 叠层样式表) 作用:美化HTML网页 (一)样式表分类 一.内联样式表 和HTML联合显示,控制精准,但是可重用性差,冗余多. 例如:<p ...