python爬取昵称并保存为csv
代码:
import sys
import io
import re
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
import requests
from bs4 import BeautifulSoup def html_save(s):
with open('Name.csv','a')as f:
f.write(s+'\n')
# soup = BeautifulSoup(html,'index')
def getName_link():
lst=[]
soup = BeautifulSoup(open('Girl.html'))
for div in soup.find_all('div',{'class':'babynology_textevidence babynology_bg_grey babynology_shadow babynology_radius left overflow_scroll'}):
for strong in div.find_all('strong'):
print(strong.find_all('a')[0].text.replace(' ','').replace(' ','').replace('\n',''))
# print(strong.find_all('a')[0].get('href').replace('\n',''))
i=strong.find_all('a')[0].text.replace(' ','').replace(' ','').replace('\n','')
# j=strong.find_all('a')[0].get('href').replace('\n','')
# lst.append(j)
html_save(i)
# html_save(j)
# print(lst)
# return lst
getName_link()
运行结果:
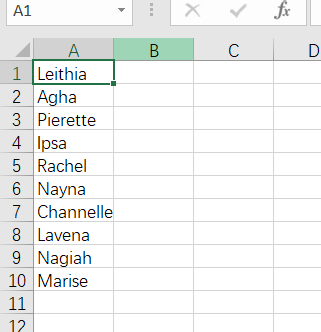
python爬取昵称并保存为csv的更多相关文章
- python爬取信息并保存至csv
import csv import requests from bs4 import BeautifulSoup res=requests.get('http://books.toscrape.com ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- python爬取网站视频保存到本地
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Woo_home PS:如有需要Python学习资料的小伙伴可以加点 ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- python爬取某个网站的图片并保存到本地
python爬取某个网站的图片并保存到本地 #coding:utf- import urllib import re import sys reload(sys) sys.setdefaultenco ...
- 票房和口碑称霸国庆档,用 Python 爬取猫眼评论区看看电影《我和我的家乡》到底有多牛
今年的国庆档电影市场的表现还是比较强势的,两名主力<我和我的家乡>和<姜子牙>起到了很好的带头作用. <姜子牙>首日破 2 亿,一举刷新由<哪吒之魔童降世&g ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
随机推荐
- 学java可以做些什么
学java可以做些什么 对于很多新手来说,刚开始接触Java会很迷惘,不知道Java可以做什么.其实Java 可以做的东西太多了,手机游戏.中间件.软件.网站,电脑游戏,以及现在流行的安卓手机app等 ...
- LeetCode 第70题动态规划算法
导言 看了 动态规划(https://www.cnblogs.com/fivestudy/p/11855853.html)的帖子,觉得写的很好,记录下来. 动态规划问题一直是算法面试当中的重点和难点, ...
- maven配置阿里云仓库镜像
全局配置 修改settting文件 在mirrors标签下添加子节点. <mirror> <id>nexus-aliyun</id> <mirrorOf> ...
- Spring Boot Redis 解析
redis使用示例 本示例主要内容 使用lettuce操作redis redis字符串存储(RedisStringController.java) redis对象存储(RedisObjectContr ...
- SpringCloud的入门学习之概念理解、Feign负载均衡入门
1.Feign是SpringCloud的一个负载均衡组件. Feign是一个声明式WebService客户端.使用Feign能让编写Web Service客户端更加简单, 它的使用方法是定义一个接口, ...
- 随机的标识符GUID
Guid guid = Guid.NewGuid();Console.WriteLine(guid.ToString());
- python 使用tesseract进行图片识别
from PIL import Image import pytesseract text = pytesseract.image_to_string(Image.open(r'E:\guo\2432 ...
- 前端JS实现一键导入excel表格
前面的文章中已经讲过关于js表格的导出,此文章主要说到的是excel文件如何导入到网页中,并在网页端显示. 代码部分: <!DOCTYPE html> <html> <h ...
- 如何开发优质的 Flutter App:Flutter App 软件调试指南
本次博主带来的是<深入 Flutter 系列课程>第三讲,主要聊聊如何进行 Flutter App 代码的调试.本次课程将在GitChat平台上免费进行,通过本场 Chat,您将获得以下技 ...
- Checklist for an RMAN Restore (Doc ID 1554636.1)
Checklist for an RMAN Restore (Doc ID 1554636.1) APPLIES TO: Oracle Database - Enterprise Edition - ...