Hadoop相关问题解决
Hadoop相关问题解决
Hive
1.查询hivemeta信息,查到的numRows为-1
| 集群厂商 | 集群版本 | 是否高可用 | 是否开启认证 |
|---|---|---|---|
| cdh | 不限 | 不限 | 不限 |
在hivemeta库中可以通过以下sql查询表的元数据信息
SELECT * FROM TABLE_PARAMS WHERE tbl_id = 45857
其中numRows会被用来统计为表的行数,但是发现有些表查出来行数为-1
可能原因
对于一个新创建的表,默认情况下,如果通过INSERT OVERWRITE的方式插入数据,那么Hive会自动将该表或分区的统计信息更新到元数据。
有一个参数来控制是否自动统计,hive.stats.autogather,默认为true.
可能是因为这个表新建后没有通过这种方式插入过数据,所以表没有进行过统计,默认信息即为numRows=-1
解决方案
使用命令 ANALYZE TABLE tableName COMPUTE STATISTICS; 统计元数据信息
再查询时,numRows变为0
2. bucketId out of range: -1 (state=,code=0)
| 集群厂商 | 集群版本 | 是否高可用 | 是否开启认证 |
|---|---|---|---|
| hdp | 3.1.1 | 是 | 是 |
执行一个普普通通的 SELECT * FROM student WHERE 1 = 1 LIMIT 5;报错
Error: java.io.IOException: java.lang.IllegalArgumentException: bucketId out of range: -1 (state=,code=0)
可能原因
初步怀疑和hadoop3支持事务有关

hadoop3.1建表默认创建acid表,acid表只支持ORC格式
解决方案
在建表语句最后加上STORED AS textfile;
3.集群客户端使用hive命令连接,报错认证失败
| 集群厂商 | 集群版本 | 是否高可用 | 是否开启认证 |
|---|---|---|---|
| hdp | 3.1.1 | 是 | 是 |
报错信息忘了拷贝了
可能原因
客户端java 的安全认证文件没有下发,kerberos加密解密有问题
需要jar包:
- local_policy.jar
- US_export_policy.jar
解决方案
拷贝安全认证文件到客户端
scp root@ip:/opt/third/jdk/jre/lib/security/*.jar /opt/third/jdk/jre/lib/security/
4.运行hive任务卡在Tez session hasn't been created yet. Opening session
| 集群厂商 | 集群版本 | 是否高可用 | 是否开启认证 |
|---|---|---|---|
| hdp | 3.1.1 | 是 | 是 |
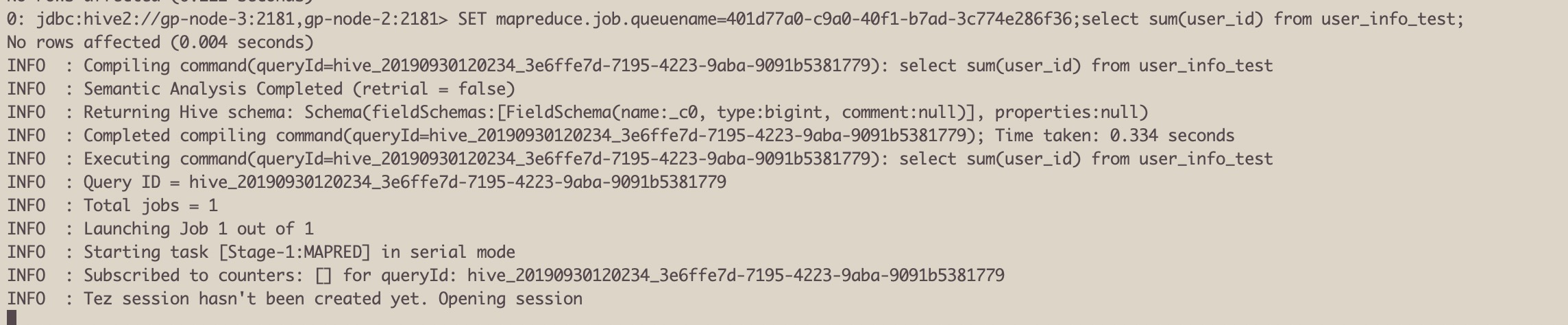
可能原因
没有指定tez队列,无法获取到足够的资源启动任务
解决方案
设置tez队列 set tez.queue.name =
问题拓展
hive 设置队列需要根据所使用的引擎进行对应的设置才会有效果,否则无效
# 设置引擎
set hive.execution.engine=mr;
set hive.execution.engine=spark;
set hive.execution.engine=tez;
# 如果使用的是mr(原生mapreduce)
SET mapreduce.job.queuename=etl;
# 如果使用的引擎是tez
set tez.queue.name=etl
# 设置队列(etl为队列名称,默认为default)
MapReduce:是一种离线计算框架,用于大规模数据集(大于1TB)的并行运算,将一个算法抽象成Map和Reduce两个阶段进行处理,非常适合数据密集型计算。
Spark:Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
Storm:MapReduce也不适合进行流式计算、实时分析,比如广告点击计算等。Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。Storm经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域
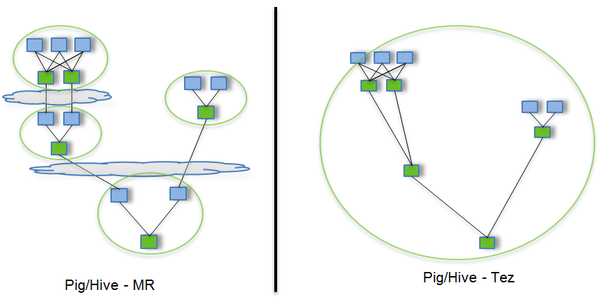
Tez: 是基于Hadoop Yarn之上的DAG(有向无环图,Directed Acyclic Graph)计算框架。它把Map/Reduce过程拆分成若干个子过程,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等。同时可以把多个Map/Reduce任务组合成一个较大的DAG任务,减少了Map/Reduce之间的文件存储。同时合理组合其子过程,也可以减少任务的运行时间
5.Unable to read HiveServer2 configs from ZooKeeper
| 集群厂商 | 集群版本 | 是否高可用 | 是否开启认证 |
|---|---|---|---|
| fi | 5.15.2 | 是 | 是 |
没有进行zk认证
HDFS
1.No common protection layer between client and server
| 集群厂商 | 集群版本 | 是否高可用 | 是否开启认证 |
|---|---|---|---|
| cdh | 5.15.2 | 是 | 是 |
javax.security.sasl.SaslException: No common protection layer between client and server
at com.sun.security.sasl.gsskerb.GssKrb5Client.doFinalHandshake(GssKrb5Client.java:251)
at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:186)
at org.apache.hadoop.security.SaslRpcClient.saslEvaluateToken(SaslRpcClient.java:483)
at org.apache.hadoop.security.SaslRpcClient.saslConnect(SaslRpcClient.java:427)
at org.apache.hadoop.ipc.Client$Connection.setupSaslConnection(Client.java:594)
at org.apache.hadoop.ipc.Client$Connection.access$2000(Client.java:396)
at org.apache.hadoop.ipc.Client$Connection$2.run(Client.java:761)
at org.apache.hadoop.ipc.Client$Connection$2.run(Client.java:757)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1920)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:756)
at org.apache.hadoop.ipc.Client$Connection.access$3000(Client.java:396)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1557)
at org.apache.hadoop.ipc.Client.call(Client.java:1480)
at org.apache.hadoop.ipc.Client.call(Client.java:1441)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:230)
可能原因
该异常由服务端与客户端配置项hadoop.rpc.protection不一致导致。
解决方案
修正服务端hadoop.rpc.protection配置,确保两端一致,重启服务。
问题拓展
可选值(需要和集群配置保持同步):authentication,integrity,privacy
在hadoop服务和客户端之间传输的数据可以在线上加密。在core-site.xml中将hadoop.rpc.protection设置为privacy会激活数据加密。以上三项分别为
- authentication【认证:仅认证(默认)】
- integrity 【完整性:除了认证之外的完整性检查】
- Privacy 【隐私:除了完整性检查之外的数据加密】
2.Can't get Master Kerberos principal for use as renewer
| 集群厂商 | 集群版本 | 是否高可用 | 是否开启认证 |
|---|---|---|---|
| cdh | 5.15.2 | 是 | 是 |

可能原因
获取fileReader的时候没有传入yarn.resourcemanager.principal参数。
解决方案
传入yarn.resourcemanager.principal参数。
3.Does not contain a valid host:port authority: hdp-2.6-node1.dtwave.com
可能原因
解决方案
HBase
1.KeeperErrorCode = NoNode for /hbase/meta-region-server
| 集群厂商 | 集群版本 | 是否高可用 | 是否开启认证 |
|---|---|---|---|
| hdp | 3.1.1 | 是 | 是 |
可能原因
hbase.znode.parent 没有配置正确,客户端需要与集群使用的一致。
解决方案
修正配置
Ranger
1.User doesn't have necessary permission to grant access
调用rangerApi授权出现以上返回,但是我的用户是admin用户,照理说是有所有权限的。
问题原因
可能是因为没有把用户添加到具体的规则中
Delegate Admin
kerberos
1.Fail to create credential. (63) - No service creds
| 集群厂商 | 集群版本 | 是否高可用 | 是否开启认证 |
|---|---|---|---|
| hdp | 2.6 | 是 | 是 |
可能原因
该异常由服务端与客户端配置项hadoop.rpc.protection不一致导致。
解决方案
Hadoop相关问题解决的更多相关文章
- [Linux] 安装JDK和Maven及hadoop相关环境
紧接上一篇,继续安装hadoop相关环境 JDK安装: 1. 下载,下面这两个地址在网上找的,可以直接下载: http://download.oracle.com/otn-pu ...
- Hadoop相关项目Hive-Pig-Spark-Storm-HBase-Sqoop
Hadoop相关项目Hive-Pig-Spark-Storm-HBase-Sqoop的相关介绍. Hive Pig和Hive的对比 摘要: Pig Pig是一种编程语言,它简化了Hadoop常见的工作 ...
- 一 hadoop 相关介绍
hadoop 相关介绍 hadoop的首页有下面这样一段介绍.对hadoop是什么这个问题,做了简要的回答. The Apache™ Hadoop® project develops open-sou ...
- Hadoop自学笔记(一)常见Hadoop相关项目一览
本自学笔记来自于Yutube上的视频Hadoop系列.网址: https://www.youtube.com/watch?v=-TaAVaAwZTs(当中一个) 以后不再赘述 自学笔记,难免有各类错误 ...
- 线下AWD平台搭建以及一些相关问题解决
线下AWD平台搭建以及一些相关问题解决 一.前言 文章首发于tools,因为发现了一些新问题但是没法改,所以在博客进行补充. 因为很多人可能没有机会参加线下的AWD比赛,导致缺乏这方面经验,比如我参加 ...
- CTFd平台搭建以及一些相关问题解决
CTFd平台搭建以及一些相关问题解决 一.序言 因为想给学校工作室提高一下学习氛围,随便带学弟学妹入门,所以做了一个ctf平台,开源的平台有CTFd和FBCTF,因为学生租不起高端云主机所以只能选择占 ...
- Ubuntu 17.10安装VirtualBox 5.2.2 及相关问题解决
link:https://www.linuxidc.com/Linux/2017-11/148870.htm sudo apt update && sudo apt upgrade s ...
- Hadoop本地库介绍及相关问题解决方法汇总
1.hadoop本地库的作用是什么?2.哪两个压缩编码器必须使用hadoop本地库才能运行?3.hadoop的使用方法?4.hadoop本地库与系统版本不一致会引起什么错误?5.$ export HA ...
- Hadoop相关日常操作
1.Hive相关 脚本导数据,并设置运行队列 bin/beeline -u 'url' --outputformat=tsv -e "set mapreduce.job.queuename= ...
随机推荐
- nyoj 122-Triangular Sums (数学之读懂求和公式的迭代)
122-Triangular Sums 内存限制:64MB 时间限制:3000ms 特判: No 通过数:5 提交数:7 难度:2 题目描述: The nth Triangular number, T ...
- ThreadLocal深度解析和应用示例
开篇明意 ThreadLocal是JDK包提供的线程本地变量,如果创建了ThreadLocal<T>变量,那么访问这个变量的每个线程都会有这个变量的一个副本,在实际多线程操作的时候,操作的 ...
- 力扣(LeetCode)删除排序链表中的重复元素II 个人题解
给定一个排序链表,删除所有含有重复数字的节点,只保留原始链表中 没有重复出现 的数字. 思路和上一题类似(参考 力扣(LeetCode)删除排序链表中的重复元素 个人题解)) 只不过这里需要用到一个前 ...
- python day 1 homework 2
多级菜单 1 三级菜单 2 可依次选择进入各子菜单 3 所需新知识点,列表,字典 province_info = {":{"name":"黑龙江", ...
- 原创|我是如何从零学习开发一款跨平台桌面软件的(Markdown编辑器)
原始冲动 最近一直在学习 Electron 开发桌面应用程序,目的是想做一个桌面编辑器,虽然一直在使用Typore这款神器,但无奈Typore太过国际化,在国内水土不服,无法满足我的一些需求. 比如实 ...
- HotSpot虚拟机对象的创建过程
1.文中讨论的对象限于普通Java对象,不包括数组和class对象. 2.内存的分配方式由Java堆是否规整来决定,而Java堆是否规整取决于垃圾收集器是否有压缩整理的功能. 3.还需要考虑:对象的创 ...
- Openlayers Overlay使用心得
Overlay在Openlayers里是浮动层的概念,区别于vector这样的图层,通常用于弹窗.撒点.以及解决加载icon样式不支持的gif等格式图片. 此次用overlay的过程中遇到很多问题,在 ...
- 设计模式之美学习(九):业务开发常用的基于贫血模型的MVC架构违背OOP吗?
我们都知道,很多业务系统都是基于 MVC 三层架构来开发的.实际上,更确切点讲,这是一种基于贫血模型的 MVC 三层架构开发模式. 虽然这种开发模式已经成为标准的 Web 项目的开发模式,但它却违反了 ...
- python与redis交互及redis基本使用
Redis简介 Redis是一使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日个开源的志型.Key-Value数据库,并提供多种语言的API. 从2010年3月15日起,Redis的开发工 ...
- YoungLots Team - Record a software installation
一.写在最前 本文记录安装或配置以下软件或环境的过程:VScode,Xampp,navicat,PHP,html,CSS,SQL,JavaScript. 作者使用的环境:浏览器:Google Chro ...