数据挖掘--K-means
K-Means方法是MacQueen1967年提出的。给定一个数据集合X和一个整数K(n),K-Means方法是将X分成K个聚类并使得在每个聚类中所有值与该聚类中心距离的总和最小。
K-Means聚类方法分为以下几步:
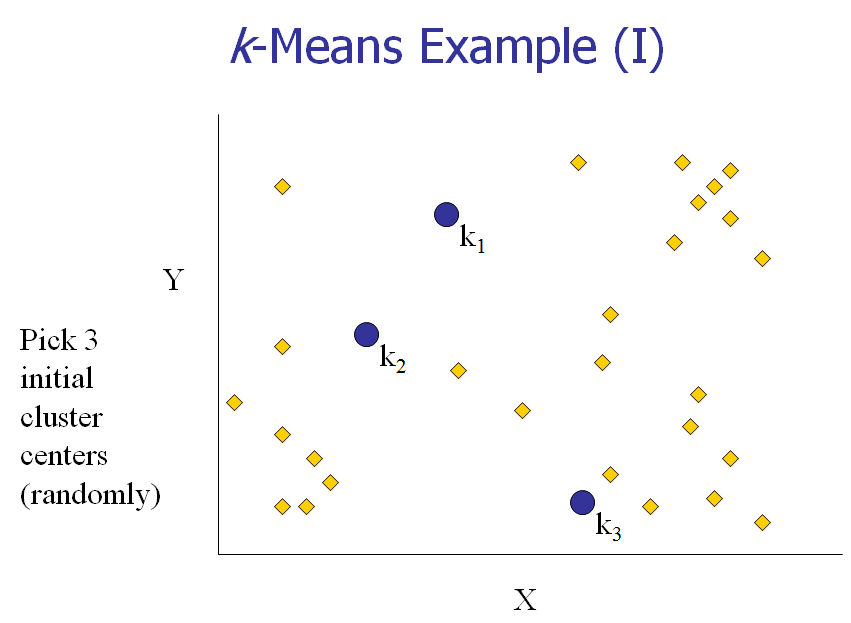
[1] 给K个cluster选择最初的中心点,称为K个Means。
[2] 计算每个对象和每个中心点之间的距离。
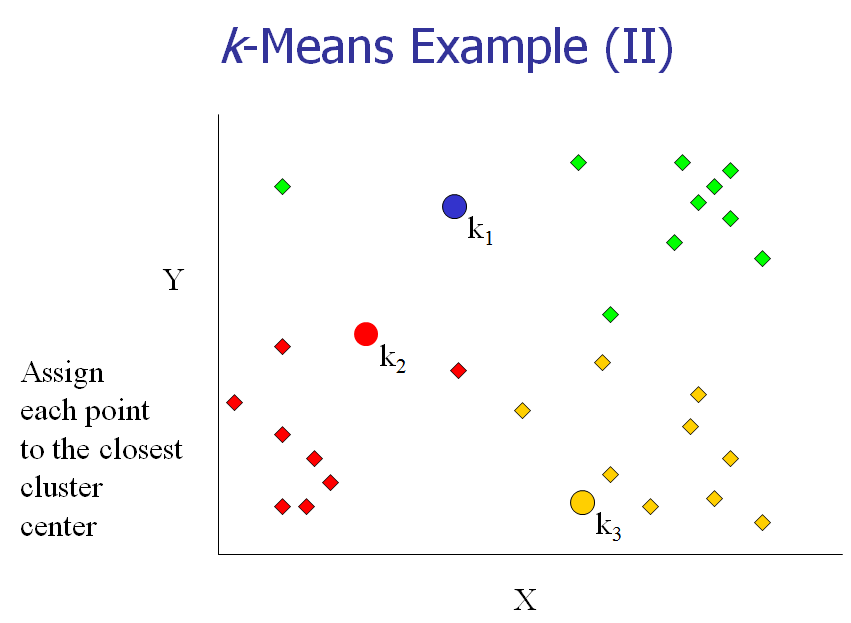
[3] 把每个对象分配给距它最近的中心点做属的cluster。
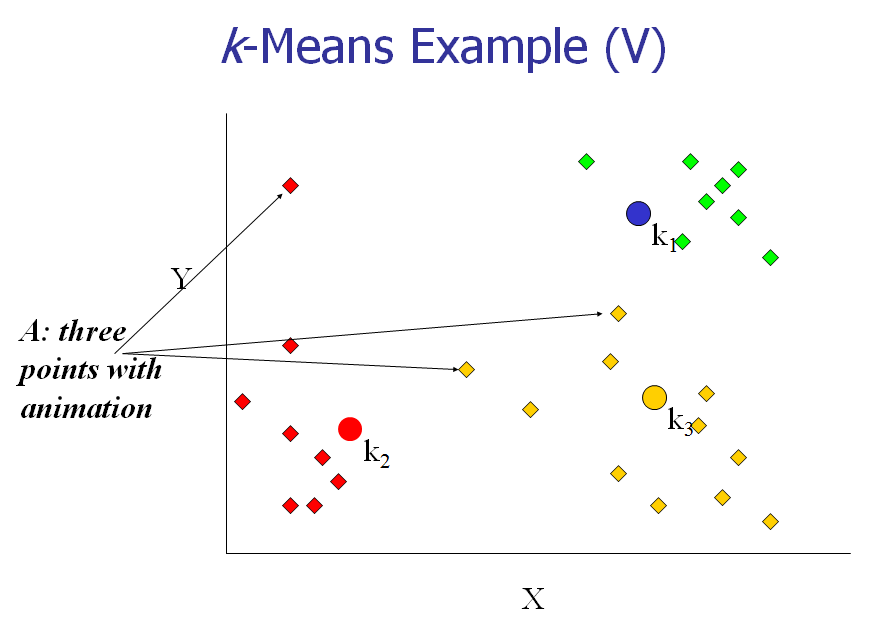
[4] 重新计算每个cluster的中心点。
[5] 重复2,3,4步,直到算法收敛。
以下几张图动态展示了这几个步骤:




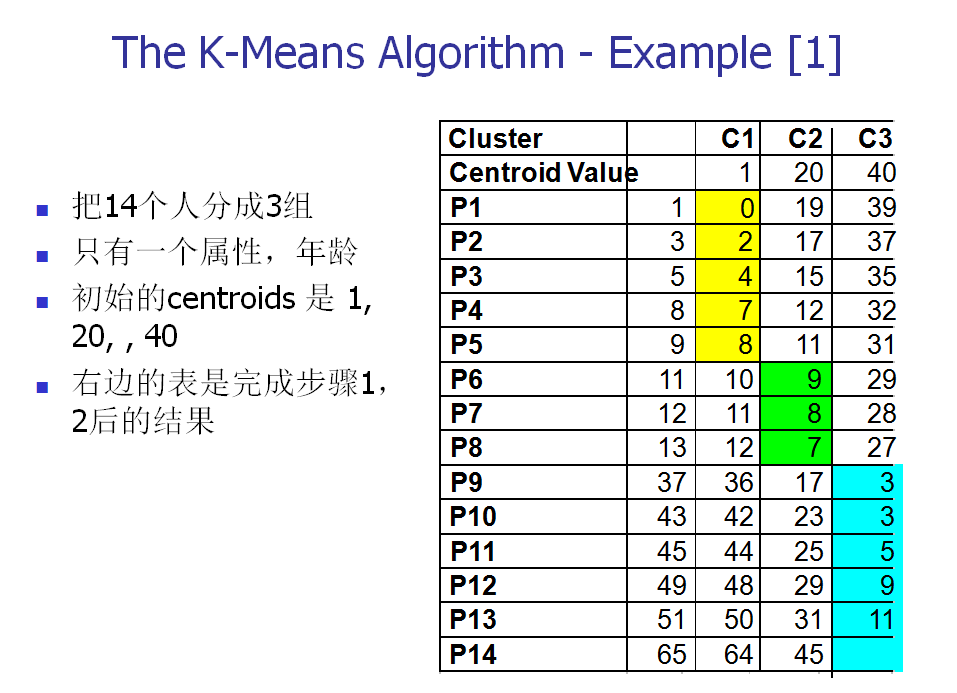
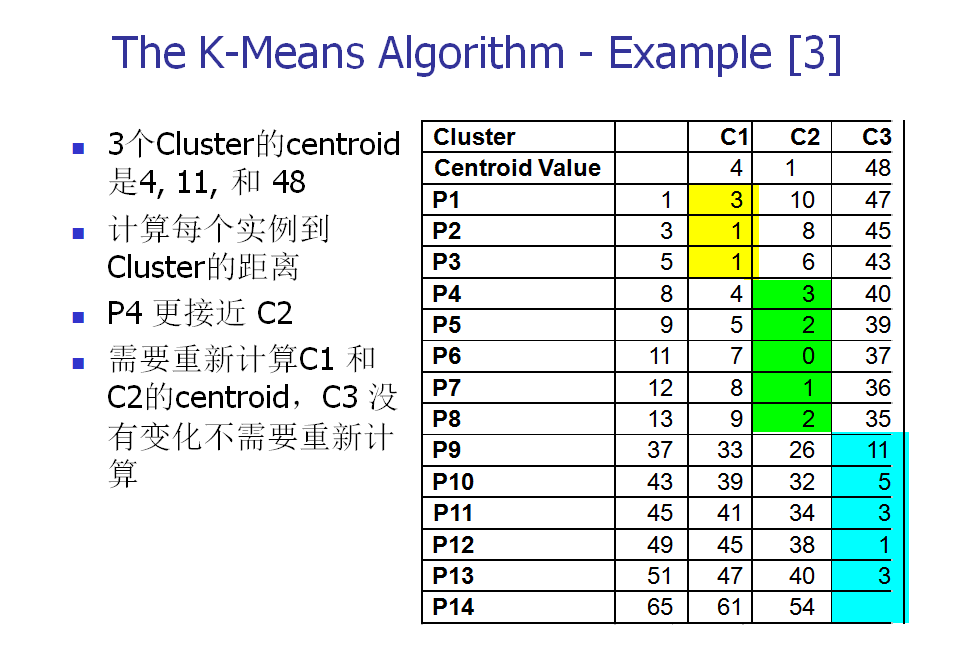
下面,我们以一个具体的例子来说明一下K-means算法的实现。


K-means算法的优缺点:
优点:
(1)对于处理大数据量具有可扩充性和高效率。算法的复杂度是O(tkn),其中n是对象的个数,k是cluster的个数,t是循环的次数,通常k,t<<n。
(2)可以实现局部最优化,如果要找全局最优,可以用退火算法或者遗传算法
缺点:
(1)Cluster的个数必须事先确定,在有些应用中,事先并不知道cluster的个数。
(2)K个中心点必须事先预定,而对于有些字符属性,很难确定中心点。
(3)不能处理噪音数据。
(4)不能处理有些分布的数据(例如凹形)
K-Means方法的变种
(1) K-Modes :处理分类属性
(2) K-Prototypes:处理分类和数值属性
(3) K-Medoids
它们与K-Means方法的主要区别在于:
(1)最初的K个中心点的选择不同。
(2)距离的计算方式不同。
(3)计算cluster的中心点的策略不同。
数据挖掘--K-means的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- 快速查找无序数组中的第K大数?
1.题目分析: 查找无序数组中的第K大数,直观感觉便是先排好序再找到下标为K-1的元素,时间复杂度O(NlgN).在此,我们想探索是否存在时间复杂度 < O(NlgN),而且近似等于O(N)的高 ...
- 数据挖掘十大算法--K-均值聚类算法
一.相异度计算 在正式讨论聚类前,我们要先弄清楚一个问题:怎样定量计算两个可比較元素间的相异度.用通俗的话说.相异度就是两个东西区别有多大.比如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能 ...
- 网络费用流-最小k路径覆盖
多校联赛第一场(hdu4862) Jump Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- numpy.ones_like(a, dtype=None, order='K', subok=True)返回和原矩阵一样形状的1矩阵
Return an array of ones with the same shape and type as a given array. Parameters: a : array_like Th ...
- K-MEANS算法总结
K-MEANS算法 摘要:在数据挖掘中,K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. 在数据挖掘中,K-M ...
- 关于K-Means算法
在数据挖掘中,K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. 问题 K-Means算法主要解决的问题如下图所示. ...
- 当我们在谈论kmeans(3)
本系列意在长期连载分享,内容上可能也会有所删改: 因此如果转载,请务必保留源地址,非常感谢! 博客园:http://www.cnblogs.com/data-miner/(暂时公式显示有问题) ...
- K-Means 算法(转载)
K-Means 算法 在数据挖掘中, k-Means 算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. 问题 K-Means ...
随机推荐
- Python—函数的参数传递
形参和实参 形参即形式参数,函数完成其工作时所需的信息.形参不占用内存空间,只有在被调用时才会占用内存空间,调用完了即被释放. 实参即实际参数,调用函数时传给函数的信息. # -*- coding: ...
- Asp.Net Core 开发之旅之NLog日志
NLog已是日志库的一员大佬,使用也简单方便,本文介绍的环境是居于.NET CORE 3.0 1.安装 Install-Package NLog.Web.AspNetCore 2.创建配置文件 在we ...
- 5G浪潮来袭,程序员在风口中有何机遇
导读:本文共2894字,预计阅读时间为9分钟.通过阅读本文,你将了解到5G的优势.即将燃爆的领域以及程序员在快速发展的5G产业中所需关注的技术. 5G时代已经来临 随着中美5G主导权之战的持续发酵,5 ...
- July 13th, 2018. Friday, Week 28th.
Don't let the mistakes and disappointments of the past control and direct your future. 不要让你的未来被过去的错误 ...
- 一,java框架学习
一,java框架学习 Hibernate概述Hibernate是一个开放源代码的ORM(对象关系映射)框架,对jdbc进行了轻量级的封装,是的java开发人员可以使用面向对象编程思想操作数据库,简化操 ...
- jQuery中的属性(四)
1. attr(name|properties|key,value|fn), 设置或返回被选元素的属性值 参数说明: name:属性名称 properties:作为属性的“名/值对”对象 key,va ...
- numpy-数据清洗
一.对G列数据进行清洗,根据['无','2000-3999','4000-5999','6000-7999','8000-9999','>10000']进行划分 去处重复值 # 删除重复值 # ...
- oracle存储过程中循环游标,变量的引用
创建出错时使用: show errors查看具体的错误提示 一. 存储过程中的一个循环及变量引用示例: create or replace procedure my_proiscursor cur i ...
- JavaScript查找两个数组的相同元素和相差元素
let intersection = a.filter(v => b.includes(v)) 返回交集数组 let difference = a.concat(b).filter(v => ...
- vue使用--环境搭建与基本项目创建说明
桃之夭夭,思绪纷飞. 一.环境搭建 1.安装node.js(包含包管理工具npm) 安装包可以到node官网进行下载,穿梭>>> 根据自己的操作系统下载相应版本的安装包,运行后按照操 ...