numpy-数据清洗
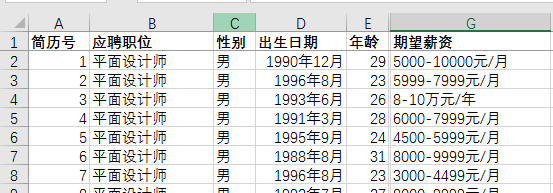
一、对G列数据进行清洗,根据['无','2000-3999','4000-5999','6000-7999','8000-9999','>10000']进行划分
去处重复值
# 删除重复值
# print('删除重复值前大小',data.shape)
# # 删除记录
# data = data.drop_duplicates()
# print('删除重复值后大小',data.shape)
删除缺失值
"""删除缺失值""" #df.dropna()# 删除出现缺失值得行 # df.dropna(axis=1) #df.dropna(how='any') # 只要出现缺失值就删除 #df.dropna(subset=['房价'])# 指定列出现缺失值才删除 #data.dropna(how='all') # 当整行数据都为nan 时才删除
删除或填充缺失值
"""一、删除或填充缺失值"""
data.iloc[1429:]
new_data = data.drop(index=range(1430,1780)).fillna({'期望薪资':'无'})
将不同单位的薪资形式,转化成统一形式
"""二、将不同单位的薪资形式,转化成统一形式""" print(new_data['期望薪资'].str[-6:].value_counts())

将不规则的薪资形式转化为统一形式
"""将不规则的薪资形式转化为统一形式""" new_data.loc[new_data['期望薪资'].str[-6:]=='万以下元/年','期望薪资']= '0-2万元/年' new_data.loc[new_data['期望薪资'].str[-5:]=='以下元/月','期望薪资']='0-1500元/月'
new_data['期望薪资'].str[-4:].value_counts()

"""将统一后的不同单位的薪资,统一转化成平均月薪(元/月)"""
def salary_proc(salary):
"""将传入的薪资转化成统一的平均月薪"""
if salary == '无':
return 0
elif re.search('元/月',salary):
s = re.findall('(\d+)-(\d+)元/月',salary)
# s=[('1000','10000')]
mi,ma = int(s[0][0]),int(s[0][1])
return (mi+ma)*0.5
elif re.search('万元/年',salary):
s = re.findall('(\d+)-(\d+)万元/年',salary)
mi,ma = int(s[0][0]),int(s[0][1])
return (mi+ma)*0.5*10000/12
elif re.search('元/年',salary):
s = re.findall('(\d+)-(\d+)元/年',salary)
mi,ma = int(s[0][0]),int(s[0][1])
return (mi+ma)*0.5/12
else:
return -1
"""新增列保存平均月薪"""
"""一、for 效率低"""
new_data['mean_salary']=0
for i in new_data['期望薪资'].index:
new_data.loc[i,'mean_salary']=salary_proc(new_data.loc[i,'期望薪资'])
"""二、apply(),矢量化字符串的方法,效率高""" new_data['mean_salary2'] = new_data['期望薪资'].apply(salary_proc)
# new_data.iloc[:,-2:] """三、进行切分""" bins = [0,2000,4000,6000,8000,10000,1000000] labels =['0-2000','2000-3999','4000-5999','6000-7999','8000-9999','>10000'] new_data['salary_class']=pd.cut(new_data['mean_salary'],bins,labels=labels,right=False)# right 改变区间的闭合方式
new_data['salary_class'].value_counts()
二、 对AA列进行清洗,要求分成三类全包含(PhotoShop,Corel DRAW,AI),三项,只包含其中一项或两项,全不包含
处理缺失值
"""处理缺失值"""
new_data['技能/语言'].fillna('无',inplace=True)
"""提取技能关键词"""
new_data['skill'] = new_data['技能/语言'].str.findall('[a-zA-Z0-9\s#.\+/]+')
"""处理技能词前后的空格,并统一转化成小写"""
new_data['skill2']=''
for i in new_data['skill'].index:
new_data.loc[i,'skill2']=",".join(map(lambda x:x.strip().lower(),new_data.loc[i,'skill']))
"""将每个人的技能和目标技能进行比较,统计技能数"""
new_data['skill_class']=0
s = ['photoshop','corel draw','ai']
for i in new_data['skill2'].index:
skill = new_data['skill2'].iloc[i]
b = 0
for j in s:
if j in skill:
b+=1
new_data.loc[i,'skill_class']=b
new_data['skill_class'].value_counts()

new_data['skill_class'].map({0:'全不包含',1:'包含其中一项',2:'包含其中的两项',3:'三项技能全包含'})

numpy-数据清洗的更多相关文章
- 如何用Python中自带的Pandas和NumPy库进行数据清洗
一.概况 1.数据清洗到底是在清洗些什么? 通常来说,你所获取到的原始数据不能直接用来分析,因为它们会有各种各样的问题,如包含无效信息,列名不规范.格式不一致,存在重复值,缺失值,异常值等..... ...
- 【转载】使用pandas进行数据清洗
使用pandas进行数据清洗 本文转载自:蓝鲸的网站分析笔记 原文链接:使用python进行数据清洗 目录: 数据表中的重复值 duplicated() drop_duplicated() 数据表中的 ...
- python 数据清洗之数据合并、转换、过滤、排序
前面我们用pandas做了一些基本的操作,接下来进一步了解数据的操作, 数据清洗一直是数据分析中极为重要的一个环节. 数据合并 在pandas中可以通过merge对数据进行合并操作. import n ...
- [数据清洗]-使用 Pandas 清洗“脏”数据
概要 准备工作 检查数据 处理缺失数据 添加默认值 删除不完整的行 删除不完整的列 规范化数据类型 必要的转换 重命名列名 保存结果 更多资源 Pandas 是 Python 中很流行的类库,使用它可 ...
- 机器学习中数据清洗&预处理
数据预处理是建立机器学习模型的第一步,对最终结果有决定性的作用:如果你的数据集没有完成数据清洗和预处理,那么你的模型很可能也不会有效 第一步,导入数据 进行学习的第一步,我们需要将数据导入程序以进行下 ...
- 数据分析---用pandas进行数据清洗(Data Analysis Pandas Data Munging/Wrangling)
这里利用ben的项目(https://github.com/ben519/DataWrangling/blob/master/Python/README.md),在此基础上增添了一些内容,来演示数据清 ...
- 2.pandas数据清洗
pandas是用于数据清洗的库,安装配置pandas需要配置许多依赖的库,而且安装十分麻烦. 解决方法:可以用Anaconda为开发环境,Anaconda内置了许多有关数据清洗和算法的库. 1.安装p ...
- [数据清洗]-Pandas 清洗“脏”数据(一)
概要 准备工作 检查数据 处理缺失数据 添加默认值 删除不完整的行 删除不完整的列 规范化数据类型 必要的转换 重命名列名 保存结果 更多资源 Pandas 是 Python 中很流行的类库,使用它可 ...
- Python数据清洗基本流程
# -*- coding: utf-8 -*-"""Created on Wed Jul 4 18:40:55 2018 @author: zhen"" ...
- 1.理解Numpy、pandas
之前一直做得只是采集数据,而没有再做后期对数据的处理分析工作,自己也是有意愿去往这些方向学习的,最近就在慢慢的接触. 首先简单理解一下numpy和pandas:一.NumPy:1.NumPy是高性能计 ...
随机推荐
- 第05组 Alpha冲刺(2/4)
第05组 Alpha冲刺(2/4) 队名:天码行空 组长博客连接 作业博客连接 团队燃尽图(共享): GitHub当日代码/文档签入记录展示(共享): 组员情况: 组员1:卢欢(组长) 过去两天完成了 ...
- 《细说PHP》第四版 样章 第18章 数据库抽象层PDO 5
18.5 使用PDO对象 PDO扩展类库为PHP访问数据库定义了一个轻量级.一致性的接口,它提供了一个数据访问抽象层,这样,无论使用什么数据库,都可以通过一致的函数执行查询和获取数据,大大简化了数据 ...
- javascript split() 把一个字符串分割成字符串数组,类似于PHP的 explode()函数
用法类似于框里的 例子:
- vue发送ajx请求 axios
一. 简介 1.vue本身不支持发送AJAX请求,需要使用vue-resource(vue1.0版本).axios(vue2.0版本)等插件实现 2.axios是一个基于Promise的HTTP请求客 ...
- Python远程linux执行命令
1.远程登录到linux上,使用到的模块paramiko #远程登陆操作系统 def ssh(sys_ip,username,password,cmds): try #创建ssh客户端 client ...
- PHP面试题2019年小米工程师面试题及答案解析
一.单选题(共29题,每题5分) 1.PHP面向对象方法重写描述错误的是? A.子类必须继承父类 B.子类可以重写父类已有方法 C.重写之后子类会调用父类方法 D.子类也可以具有与父类同名的属性,进行 ...
- Zuul 1.x 的工作原理
Zuul简介 Zuul在微服务架构中,可以作为提供动态路由,监控,弹性,安全等边缘服务的框架.在Netflix,被用作所有请求到达streaming application的前门.Zuul使用一系列不 ...
- Zipkin客户端链路追踪源码解析
我们知道,Zipkin这个工具可以帮助我们收集分布式系统中各个系统之间的调用连关系,而且除了Servlet之外还能收集:MQ.线程池.WebSocket.Feign.Hystrix.RxJava.We ...
- Django 全局log process_exception中间件
class BaseResp: # 基础的返回值类 def __init__(self, code, msg, data): self.code = code self.msg = msg self. ...
- elasticsearch ik同义词
由于elasticsearch 更新实在太快,配置同义词的资料层次不齐,费尽千辛万苦终于找到了.本文通过一个同义词搜索的简单实例来说明ik同义词的配置. 环境介绍 这点很重要,本文是基于elastic ...