B站弹幕爬取 / jieba分词 - 全站第一的视频弹幕都在说什么?
前言
本次爬取的视频av号为75993929(11月21的b站榜首),讲的是关于动漫革命机,这是一部超魔幻现实主义动漫(滑稽),有兴趣的可以亲身去感受一下这部魔幻大作。
准备工作
- B站弹幕的爬取的接口
https://api.bilibili.com/x/v1/dm/list.so?oid=
打开开发者模式,其中的oid的值
- 获取视频发出以来的所有弹幕,构造URL
https://api.bilibili.com/x/v2/dm/history?type=1&oid=129995312&date=2019-11-17
- 访问一下弹幕页面,发现弹幕都放在标签中。
代码
import requests
from pyquery import PyQuery as pq
import jieba
import pandas as pd
# 通过时间来获取弹幕信息需要登陆才行,所以带上登陆后的cookie。否则只能获取当日的一千条弹幕
headers={
"放入cookie"
}
word = []
def getInfo(date):
response = requests.get("https://api.bilibili.com/x/v2/dm/history?type=1&oid=129995312&date=2019-11-"+str(date), headers=headers)
# 解决中文乱码问题
response.encoding = response.apparent_encoding
doc = pq(response.content)
# 获取所有的d标签
result = doc("d")
for line in result:
word.append(line.text)
# 将弹幕信息保存到csv文件中去
def savaFile():
sr = pd.Series(word)
sr.to_csv("评革命机B站弹幕.csv", encoding='utf-8', index=None)
# 利用jieba库对弹幕内容进行分词
def seperate():
data = pd.read_csv(open("评革命机B站弹幕.csv", encoding='utf-8'))
# 传入自定义的字典,毕竟b站玩梗玩到飞起
jieba.load_userdict('dict.txt')
strs = ""
for i in data.values:
strs += "".join(i[0])
l = jieba.cut(strs, cut_all=True)
res = '/'.join(l)
# 保存到文件中去
with open("word.txt", 'w', encoding='utf-8') as f:
f.write(res)
# 分析词语出现的频率
def analyse():
res = set()
def dropNa(s):
return s and s.strip()
data = open("word.txt", encoding='utf-8').read()
data = data.split('/')
newdata = []
for i in data:
# 去除掉一些无用的
if '哈' in i or len(i) == 1 or '嘿' in i:
continue
newdata.append(i)
data = newdata
# 去除空串
data = list(filter(dropNa, data))
df = pd.Series(data)
# 统计出现频率同时写入文件中
df.value_counts().to_csv("弹幕TOP.csv")
for i in range(18, 22):
getInfo(i)
savaFile()
seperate()
analyse()
结果展示
大河内老师不愧是早稻田大学人类科学系的毕业的
这些弹幕突然就有内味了
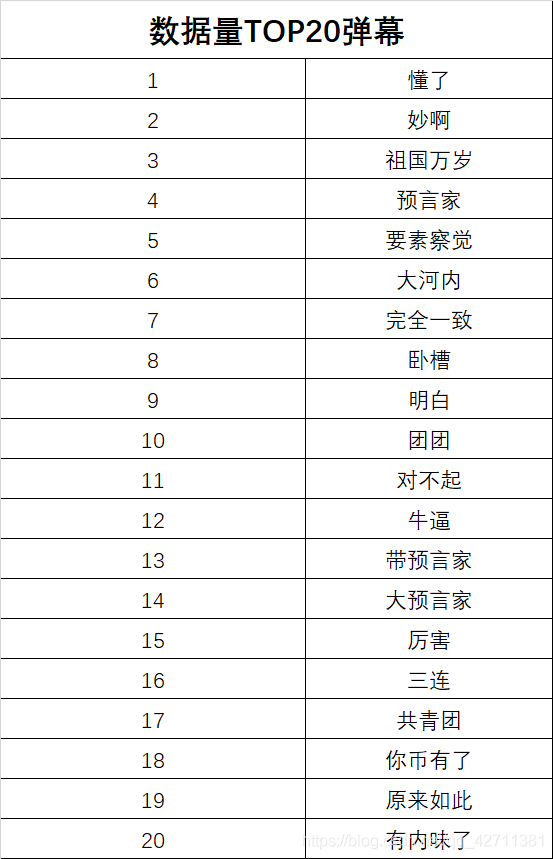
预知为何弹幕会呈现这种情况,详情请见这部动画曾因不切实际被人嘲讽,但6年后现实却打了所有人的脸! 【革命机】
存在的问题
- jieba分词的效果其实不太理想,希望未来能够找到改进方法。
- 本来想做成词云的,但是效果也不佳,待改进。
B站弹幕爬取 / jieba分词 - 全站第一的视频弹幕都在说什么?的更多相关文章
- python预课05 爬虫初步学习+jieba分词+词云库+哔哩哔哩弹幕爬取示例(数据分析pandas)
结巴分词 import jieba """ pip install jieba 1.精确模式 2.全模式 3.搜索引擎模式 """ txt ...
- B站弹幕爬取
B站弹幕爬取 单个视频弹幕的爬取 B站弹幕都是以xml文件的形式存在的,而xml文件的请求地址是如下形式: http://comment.bilibili.com/233182992.xml ...
- Java爬虫——B站弹幕爬取
如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号,cid=14295428 弹幕存放位置为 h ...
- quotes 整站数据爬取存mongo
安装完成scrapy后爬取部分信息已经不能满足躁动的心了,那么试试http://quotes.toscrape.com/整站数据爬取 第一部分 项目创建 1.进入到存储项目的文件夹,执行指令 scra ...
- Scrapy+selenium爬取简书全站
Scrapy+selenium爬取简书全站 环境 Ubuntu 18.04 Python 3.8 Scrapy 2.1 爬取内容 文字标题 作者 作者头像 发布日期 内容 文章连接 文章ID 思路 分 ...
- Python爬取B站耗子尾汁、不讲武德出处的视频弹幕
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 前言 耗子喂汁是什么意思什么梗呢?可能很多人不知道,这个梗是出自马保国,经常上网的人可能听说过这个 ...
- bilibili弹幕爬取与比对分析
最近受人之托研究了下b站的数据爬取做个小工具,最后朋友说不需要了,本着开源共享的原则,将研究成果与大家分享一波,话不多说直接上干货 需求分析 给定up主uid和用户uid,爬取用户在该up主所有视频中 ...
- B站自动爬取器并制作词云
效果 词云展示 弹幕展示 爬取弹幕过程 基本步骤 1.寻找视频url 2.构造请求头 3.寻找弹幕地址 4.根据弹幕地址运用正则或xpath爬取 寻找B站视频的url 制作请求头 headers = ...
- Scrapy:腾讯招聘整站数据爬取
项目地址:https://hr.tencent.com/ 步骤一.分析网站结构和待爬取内容 以下省略一万字 步骤二.上代码(不能略了) 1.配置items.py import scrapy class ...
随机推荐
- 【Mock MVC】使用学习
[Mock MVC]使用学习 转载:https://www.cnblogs.com/yangchongxing/p/10658311.html
- mysql外连接
一,起因 在学习一个新知识之前,最好先了解一下你为何要学习这个知识,这个知识或技术能帮你做什么,可以给你带来哪些帮助.因此我先交代一下写这篇随笔的起因. 我在做项目的时候遇到了一个比较有意思的情况, ...
- 一个非常美的FlutterUI组件扩展集:FLUI
项目地址 FLUI 官网 下载 Demo APK 体验 这是一个群内的网友写的,感觉里面的组件风格非常美,封装的挺到位的,在此推荐给大家,具体可以参考学习. 可以学到的知识还是挺多的,组件UI封装可以 ...
- jQuery模仿ToDoList实现简单的待办事项列表
功能:在文本框中输入待办事项按下回车后,事项会出现在未完成列表中:点击未完成事项前边的复选框后,该事项会出现在已完成列表中,反之亦然:点击删除按钮会删除该事项:双击事项可以修改事项的内容.待办事项的数 ...
- JavaScrip 之 DOM
DOM 树 HTML 文档的骨干是标签. 根据文档对象模型(DOM),每个HTML标签都是一个对象,同样标签内的文本也是一个对象.因此这些对象都可通过 JavaScript 操作 如果文档中有空格(就 ...
- SAP 基础知识
SAP R/3系统的应用层由应用服务器及消息服务器(Message Server)组成. 应用服务器组件如下: 工作进程(Work Process) 调度机(Dispatcher) 网关服务器(Gat ...
- Autofac 泛型依赖注入
using Autofac;using Autofac.Extensions.DependencyInjection;using Hangfire;using Microsoft.AspNetCore ...
- LINUX OS EXERCISE 08
1 配置crontab计划任务时,记录的格式是什么? 分钟 小时 日期 月份 星期 可执行语句 2 配置crontab计划任务实例. 以root用户身份添加计划任务,每天早上7:30启动sshd服务, ...
- .NET Core 使用HMAC算法
一. HMAC 简介 通过哈希算法,我们可以验证一段数据是否有效,方法就是对比该数据的哈希值,例如,判断用户口令是否正确,我们用保存在数据库中的password_md5对比计算md5(password ...
- 精通awk系列(3):铺垫知识:读取文件的几种方式
回到: Linux系列文章 Shell系列文章 Awk系列文章 读取文件的几种方式 读取文件有如下几种常见的方式: 下面使用Shell的read命令来演示前4种读取文件的方式(第五种按字节数读取的方式 ...