B站自动爬取器并制作词云
效果
词云展示

弹幕展示
爬取弹幕过程
基本步骤
1.寻找视频url
2.构造请求头
3.寻找弹幕地址
4.根据弹幕地址运用正则或xpath爬取
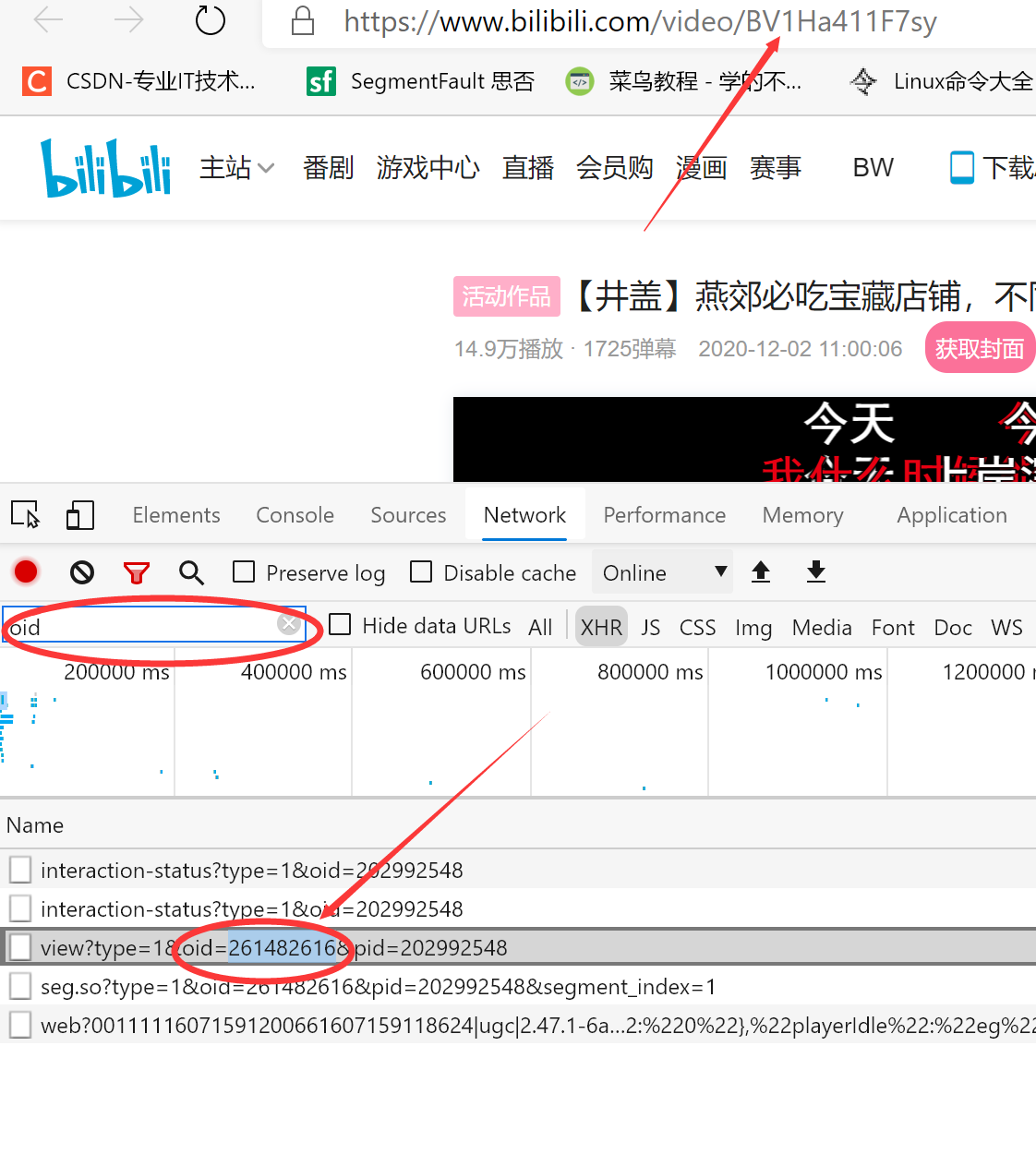
寻找B站视频的url
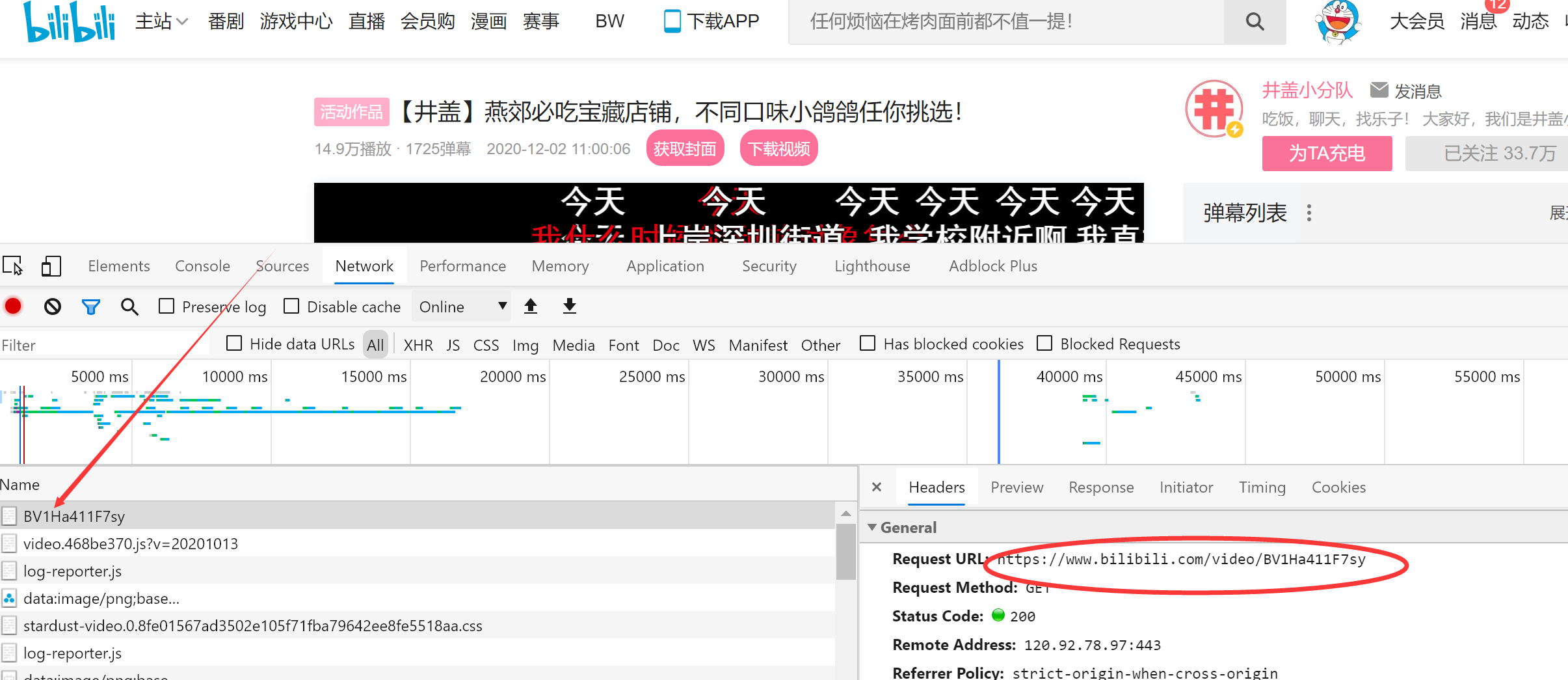
制作请求头
headers = {"User-Agent": "浏览器中的User-Agent"}
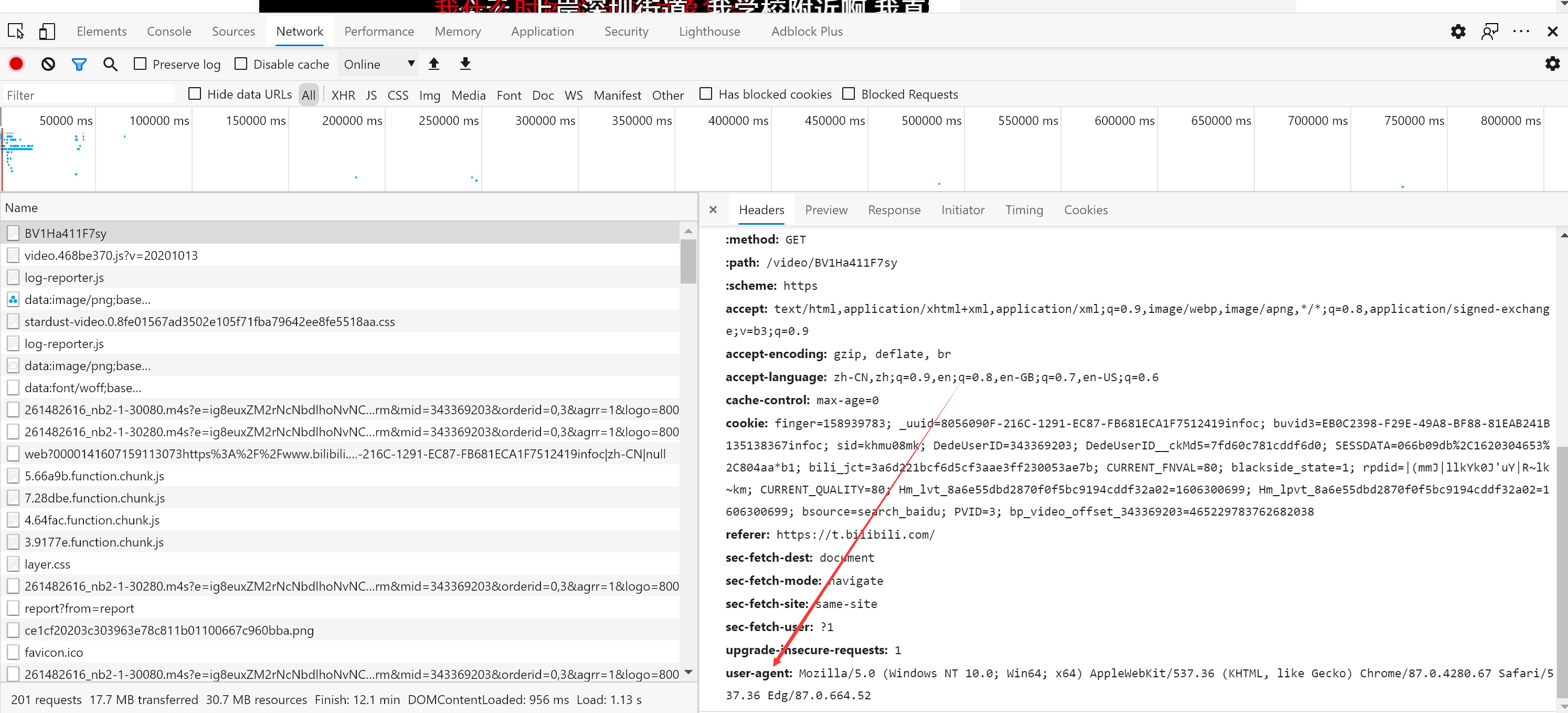
弹幕地址
1.代码通过这位博主改进的(https://www.cnblogs.com/wuren-best/p/12566297.html)
2.由于B站弹幕地址改变变得越来越难寻找到 但通过原来的弹幕地址改变下oid还是可以爬取到的
运用xpath爬取弹幕
弹幕包含在xml中的中,运用xpath取出即可

html = etree.HTML(response.content)
word_list = html.xpath("//d/text()")
词云制作
fp = open("%s弹幕.text" % self.get_tile(), 'r', encoding='utf-8')
text = fp.read()
# 字体为.TTF格式的
wd = WordCloud(background_color='white', width=300, height=316, margin=2,
font_path='钟齐段宁行书.TTF').generate(text)
plt.figure(dpi=500)
# 显示词云
plt.imshow(wd)
# 去除x,y 轴
plt.axis('off')
plt.show()
# 保存词云
wd.to_file("%s弹幕.jpg" % self.get_tile())
完整代码
# coding=utf-8
import requests
from lxml import etree
import re
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
class BiliSpider:
def __init__(self, BV, oid):
# 构造要爬取的视频url地址
self.BVurlBV = BV
self.BVurloid = oid
self.BVurl = "https://m.bilibili.com/video/" + BV
self.headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Mobile Safari/537.36"}
# 弹幕都是在一个url请求中,该url请求在视频url的js脚本中构造
def getXml_url(self):
# 获取该视频网页的内容
response = requests.get(self.BVurl, headers=self.headers)
html_str = response.content.decode()
# 使用正则找出该弹幕地址
# 弹幕地址为https://comment.bilibili.com/oid.xml
# 格式为:https://comment.bilibili.com/168087953.xml
# 我们分隔出的是地址中的弹幕文件名,即 168087953
getWord_url = self.BVurloid
# 组装成要请求的xml地址
xml_url = "https://comment.bilibili.com/{}.xml".format(getWord_url)
return xml_url
# Xpath不能解析指明编码格式的字符串,所以此处我们不解码,还是二进制文本
def parse_url(self, url):
response = requests.get(url, headers=self.headers)
# print(response.content)
return response.content
# 弹幕包含在xml中的<d></d>中,取出即可
def get_word_list(self, str):
html = etree.HTML(str)
word_list = html.xpath("//d/text()")
return word_list
# 标题及up主名
def get_tile(self):
response = requests.get(self.BVurl, headers=self.headers)
# print(response.text)
html_str = response.content.decode()
html = etree.HTML(html_str)
up_name = html.xpath('//span/text()')[1]
up_tile = html.xpath('//h1/text()')[0]
tile = []
for i in up_name, up_tile:
tile.append(i)
# print(up_name)
# print(up_tile)
# print(tile)
return tile[0]+tile[1]
# BV1ZV411a7vy 261482616
# 保存弹幕为文本格式
def save_file(self, data):
"""
保存弹幕
:param data: 弹幕信息
:return:
"""
with open("%s弹幕.text" % self.get_tile(), 'w', encoding='utf8') as f:
for line in data:
f.write(line)
f.write('\n')
# 词云
def wardcloud_(self):
fp = open("%s弹幕.text" % self.get_tile(), 'r', encoding='utf-8')
text = fp.read()
wd = WordCloud(background_color='white', width=300, height=316, margin=2,
font_path='钟齐段宁行书.TTF').generate(text)
plt.figure(dpi=500)
# 显示词云
plt.imshow(wd)
# 去除x,y 轴
plt.axis('off')
plt.show()
# 保存词云
wd.to_file("%s弹幕.jpg" % self.get_tile())
def run(self):
# 1.根据BV号获取弹幕的地址
start_url = self.getXml_url()
# 2.请求并解析数据
xml_str = self.parse_url(start_url)
# print(start_url)
word_list = self.get_word_list(xml_str)
# 3.打印
for word in word_list:
print(word)
# 4.保存
self.save_file(word_list)
# 5.词云
self.wardcloud_()
if __name__ == '__main__':
BVName = input("请输入要爬取的视频的BV号:")
oid = input("请输入要爬取的视频的oid(F12中找oid)号:")
spider = BiliSpider(BVName, oid)
spider.run()
注:BV号和oid
B站自动爬取器并制作词云的更多相关文章
- python爬取B站视频弹幕分析并制作词云
1.分析网页 视频地址: www.bilibili.com/video/BV19E… 本身博主同时也是一名up主,虽然已经断更好久了,但是不妨碍我爬取弹幕信息来分析呀. 这次我选取的是自己 唯一的爆款 ...
- 爬取B站弹幕并且制作词云
目录 爬取弹幕 1. 从手机端口进入网页爬取找到接口 2.代码 制作词云 1.文件读取 2.代码 爬取弹幕 1. 从手机端口进入网页爬取找到接口 2.代码 import requests from l ...
- 如何手动写一个Python脚本自动爬取Bilibili小视频
如何手动写一个Python脚本自动爬取Bilibili小视频 国庆结束之余,某个不务正业的码农不好好干活,在B站瞎逛着,毕竟国庆嘛,还让不让人休息了诶-- 我身边的很多小伙伴们在朋友圈里面晒着出去游玩 ...
- quotes 整站数据爬取存mongo
安装完成scrapy后爬取部分信息已经不能满足躁动的心了,那么试试http://quotes.toscrape.com/整站数据爬取 第一部分 项目创建 1.进入到存储项目的文件夹,执行指令 scra ...
- Python爬虫入门教程 25-100 知乎文章图片爬取器之一
1. 知乎文章图片写在前面 今天开始尝试爬取一下知乎,看一下这个网站都有什么好玩的内容可以爬取到,可能断断续续会写几篇文章,今天首先爬取最简单的,单一文章的所有回答,爬取这个没有什么难度. 找到我们要 ...
- Crawlspider的自动爬取
引子 : 如果想要爬取 糗事百科 的全栈数据的方法 ? 方法一 : 基于scrapy框架中的scrapy的递归爬取进行实现(requests模块递归回调parse方法) . 方法二 : 基于Crawl ...
- scrapy框架之CrawlSpider全站自动爬取
全站数据爬取的方式 1.通过递归的方式进行深度和广度爬取全站数据,可参考相关博文(全站图片爬取),手动借助scrapy.Request模块发起请求. 2.对于一定规则网站的全站数据爬取,可以使用Cra ...
- B站弹幕爬取
B站弹幕爬取 单个视频弹幕的爬取 B站弹幕都是以xml文件的形式存在的,而xml文件的请求地址是如下形式: http://comment.bilibili.com/233182992.xml ...
- python网络爬虫之使用scrapy自动爬取多个网页
前面介绍的scrapy爬虫只能爬取单个网页.如果我们想爬取多个网页.比如网上的小说该如何如何操作呢.比如下面的这样的结构.是小说的第一篇.可以点击返回目录还是下一页 对应的网页代码: 我们再看进入后面 ...
随机推荐
- 获取tp3.2 public所在的路径
//返回服务器真实路径 $Absolute_Path=$_SERVER['SCRIPT_FILENAME']; //截取index.php $Absolute_Path=substr($Absolut ...
- ESP32的Linux开发环境搭建
1. 官网教程地址 https://docs.espressif.com/projects/esp-idf/zh_CN/v4.0.1/get-started/linux-setup.html 2.官网 ...
- tcp 保活定时器分析 & Fin_WAIT_2 定时器
tcp keepalive定时器 http server 和client端需要防止"僵死"链接过多!也就是建立了tcp链接,但是没有报文交互, 或者client 由于主机突然掉电! ...
- python 之路 《三》列表与元组
我也试着把我写的东西给我的一些同学看,其实这只是我的经验还是比较建议先看书,或者在网上找相关的教学视频有了一定的基础之后再来看我写的文章,将我的经验与自己所学的知识相结合这样才会有所提高.有的同学建议 ...
- 2种方式(线程间通信/互斥锁)实现两个线程,一个线程打印1-52,另一个线程打印字母A-Z,打印顺序为12A34B56C......5152Z
//2019/06/13 本周HT面试遇到的问题,答得不是很好,自己重新做一下.面试只需要写出线程间通信的方式,//我当时大致知道思路,因为之前看过马士兵老师的多线程视频,但是代码写出来估计编译都是报 ...
- debian修改crontab默认编辑器为vim
debian终端下默认编辑器为nano,比如crontab -e就会打开nano,这个编辑器用起来很不习惯,想修改为vim,当然,你的debian系统必须先安装vim.如果已经安装vim,请输入如下命 ...
- 解决NUC972使用800*480屏幕时,tslib触摸屏校准时,坐标不对称问题
1.ADC_CONF寄存器中的ADCSAMPCNT的值,设置计数器值以延长ADC起始信号周期以获得更多采样精确转换的时间 2.内核驱动配置好触摸屏ADC的驱动后,调整autoconfig.h中的CON ...
- 为什么说线程太多,cpu切换线程会浪费很多时间?
问题1: 假如有一个计算任务,计算1-100的和,每10个数相加,需要占用一个cpu时间片(1s).如果起一个线程(模拟没有线程切换),完成任务需要多长时间?如果起5个线程,完成任务需要消耗多久时间? ...
- python程序基础
高级程序设计语言包括Python.C/C++.Java等 低级程序设计语言包括汇编语言和机器语言 Python是一种解释型语言,但为了提高运行效率,Python程序在 执行一次之后会自动生成扩展名 ...
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...