降维和PCA
- 数据在低维下更容易处理、更容易使用;
- 相关特征,特别是重要特征更能在数据中明确的显示出来;如果只有两维或者三维的话,更便于可视化展示;
- 去除数据噪声
- 降低算法开销
去除平均值计算协方差矩阵计算协方差矩阵的特征值和特征向量将特征值从大到小排序保留最上面的N个特征向量将数据转换到上述N个特征向量构建的新空间中
# 加载数据的函数def loadData(filename, delim = '\t'):fr = open(filename)stringArr = [line.strip().split(delim) for line in fr.readlines()]datArr = [map(float,line) for line in stringArr]return mat(datArr)# =================================# 输入:dataMat:数据集# topNfeat:可选参数,需要应用的N个特征,可以指定,不指定的话就会返回全部特征# 输出:降维之后的数据和重构之后的数据# =================================def pca(dataMat, topNfeat=9999999):meanVals = mean(dataMat, axis=0)# axis = 0表示计算纵轴meanRemoved = dataMat - meanVals #remove meancovMat = cov(meanRemoved, rowvar=0)# 计算协方差矩阵eigVals,eigVects = linalg.eig(mat(covMat))# 计算特征值(eigenvalue)和特征向量eigValInd = argsort(eigVals) #sort, sort goes smallest to largesteigValInd = eigValInd[:-(topNfeat+1):-1] #cut off unwanted dimensionsredEigVects = eigVects[:,eigValInd] #reorganize eig vects largest to smallestlowDDataMat = meanRemoved * redEigVects#transform data into new dimensionsreconMat = (lowDDataMat * redEigVects.T) + meanValsreturn lowDDataMat, reconMat
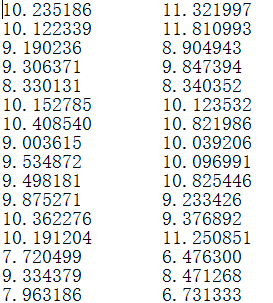
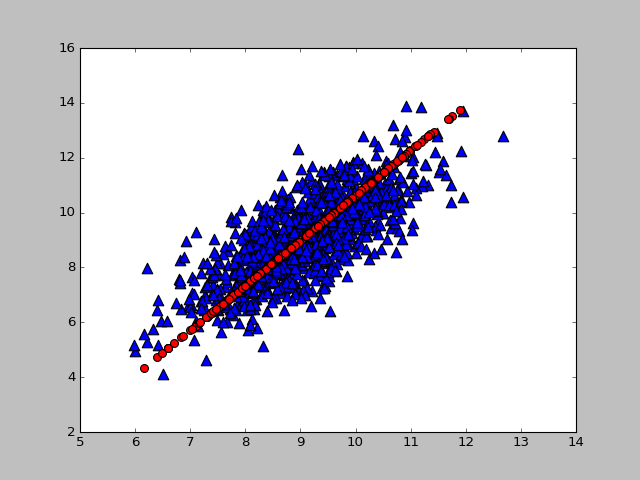
filename = r'E:\ml\machinelearninginaction\Ch13\testSet.txt'dataMat = loadData(filename)lowD, reconM = pca(dataMat, 1)
def plotData(dataMat,reconMat):fig = plt.figure()ax = fig.add_subplot(111)# 绘制原始数据ax.scatter(dataMat[:, 0].flatten().A[0], dataMat[:,1].flatten().A[0], marker='^', s = 90)# 绘制重构后的数据ax.scatter(reconMat[:,0].flatten().A[0], reconMat[:,1].flatten().A[0], marker='o', s = 10, c='red')plt.show()
lowD, reconM = pca(dataMat, 2)
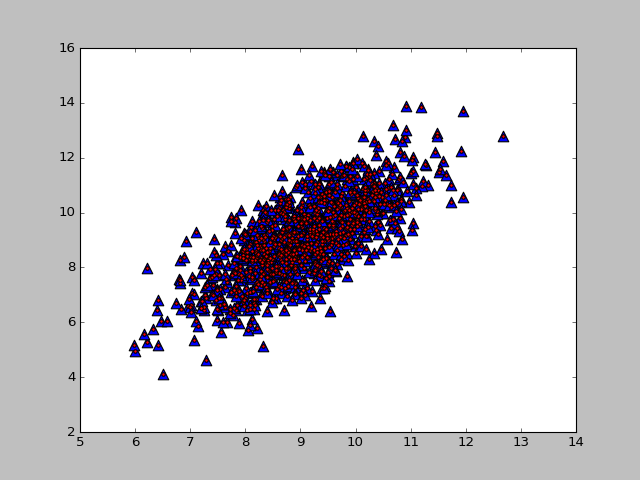
本文中只用了一个比较小的数据集来展示和验证PCA算法。
降维和PCA的更多相关文章
- 机器学习--PCA降维和Lasso算法
1.PCA降维 降维有什么作用呢?数据在低维下更容易处理.更容易使用:相关特征,特别是重要特征更能在数据中明确的显示出来:如果只有两维或者三维的话,更便于可视化展示:去除数据噪声降低算法开销 常见的降 ...
- PCA 降维算法详解 以及代码示例
转载地址:http://blog.csdn.net/watkinsong/article/details/38536463 1. 前言 PCA : principal component analys ...
- 从矩阵(matrix)角度讨论PCA(Principal Component Analysis 主成分分析)、SVD(Singular Value Decomposition 奇异值分解)相关原理
0. 引言 本文主要的目的在于讨论PAC降维和SVD特征提取原理,围绕这一主题,在文章的开头从涉及的相关矩阵原理切入,逐步深入讨论,希望能够学习这一领域问题的读者朋友有帮助. 这里推荐Mit的Gilb ...
- kaggle 实战 (1): PCA + KNN 手写数字识别
文章目录 加载package read data PCA 降维探索 选择50维度, 拆分数据为训练集,测试机 KNN PCA降维和K值筛选 分析k & 维度 vs 精度 预测 生成提交文件 本 ...
- [OpenCV] Face Detection
即将进入涉及大量数学知识的阶段,先读下“别人家”的博文放松一下. 读罢该文,基本能了解面部识别领域的整体状况. 后生可畏. 结尾的Google Facenet中的2亿数据集,仿佛隐约听到:“你们都玩儿 ...
- paper 50 :人脸识别简史与近期进展
自动人脸识别的经典流程分为三个步骤:人脸检测.面部特征点定位(又称Face Alignment人脸对齐).特征提取与分类器设计.一般而言,狭义的人脸识别指的是"特征提取+分类器"两 ...
- 【学习笔记】非监督学习-k-means
目录 k-means k-means API k-means对Instacart Market用户聚类 Kmeans性能评估指标 Kmeans性能评估指标API Kmeans总结 无监督学习,顾名思义 ...
- GoogLeNet 改进之 Inception-v2/v3 解读
博主在前一篇博客中介绍了GoogLeNet 之 Inception-v1 解读中的结构和思想.Inception的计算成本也远低于VGGNet.然而,Inception架构的复杂性使得更难以对网络进行 ...
- [CNN] Face Detection
即将进入涉及大量数学知识的阶段,先读下“别人家”的博文放松一下. 读罢该文,基本能了解面部识别领域的整体状况. 后生可畏. 结尾的Google Facenet中的2亿数据集,仿佛隐约听到:“你们都玩儿 ...
随机推荐
- 夯实Java基础(二)——面向对象之封装
1.封装介绍 封装封装,见名知意,就是把东西包装隐藏起来,不被外界所看见, 而Java特性封装:是指利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体,数据被保护在抽象数 ...
- RocketMQ中Broker的HA策略源码分析
Broker的HA策略分为两部分①同步元数据②同步消息数据 同步元数据 在Slave启动时,会启动一个定时任务用来从master同步元数据 if (role == BrokerRole.SLAVE) ...
- Unity经典游戏编程之:球球大作战
版权声明: 本文原创发布于博客园"优梦创客"的博客空间(网址:http://www.cnblogs.com/raymondking123/)以及微信公众号"优梦创客&qu ...
- Struts1.x 跨站脚本(XSS)漏洞的解决
一. 演示XSS 当访问一个不存在的网址时,例如[url]http://localhost:8080/demo/noAction.do[/url],那么Struts处理后都会跳到提示“Invali ...
- Python项目中的单元测试
引入 单元测试负责对最小的软件设计单元(模块)进行验证,unittest是Python自带的单元测试框架. 单元测试与功能测试都是日常开发中必不可少的部分,本文演示了Python中unittest单元 ...
- (17)ASP.NET Core EF基于数据模型创建数据库
1.简介 使用Entity Framework Core构建执行基本数据访问的ASP.NET Core MVC应用程序.使用迁移(Migrations)基于数据模型创建数据库,你可以在Windows上 ...
- HTTP2.0的多路复用和HTTP1.X中的长连接复用区别
HTTP/2 多路复用 (Multiplexing) 多路复用允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息 HTTP1.1 在HTTP/1.1协议中,浏览器客户端在同一时间,针 ...
- sparksession创建DataFrame方式
spark创建dataFrame方式有很多种,官方API也比较多 公司业务上的个别场景使用了下面两种方式 1.通过List创建dataFrame /** * Applies a schema to a ...
- docker An error occurred 虚拟化错误解决
问题: 本人电脑上装了VMware和docker,系统是win10专业版,然后今天想用下docker,打开报错,Hyper-V未开启,开启之后再次报错 An error occurred Hardwa ...
- EF-运行原理
一.什么是EF? 实体架构(Entity Framework)是微软以来ADO.Net为基础开发出来的对象关系映射(ORM)解决方案,它解决了对象持久化问题,将程序员从编写麻烦的SQL语句中解放出来. ...