数据分析入门——pandas之Series
一、介绍
Pandas是一个开源的,BSD许可的库(基于numpy),为Python编程语言提供高性能,易于使用的数据结构和数据分析工具。
官方中文文档:https://www.pypandas.cn/docs/
本次演示使用数据来自github:https://github.com/jakevdp/PythonDataScienceHandbook/tree/master/notebooks/data
二、快速入门
1.导入

2.重点数据结构
主要是series和dataframe
所以一般情况下我们导入的是数据分析的三剑客:
numpy Series DataFrame:(如果只导入pd,那就正常使用pd.Series即可了)
from pandas import Series,DataFrame
三、Series
Series是Pandas中的一维数据结构,类似于Python中的列表和Numpy中的Ndarray,不同之处在于:Series是一维的,能存储不同类型的数据,有一组索引与元素对应。也就是加了索引的一维数据结构(索引不一定是0 1 2 3的数字)

1.创建
1)通过列表或者numpy数组进行创建,默认索引是0 1 2 3这样的整数索引。示例如上图
想要指定索引,可以设置index参数:(创建的时候指定也是可以的)
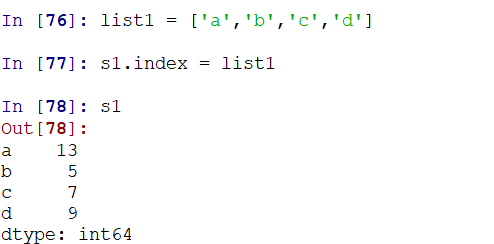
特别地,使用ndarray创建的series是引用,对series的改变会影响ndarray
2)由字典创建
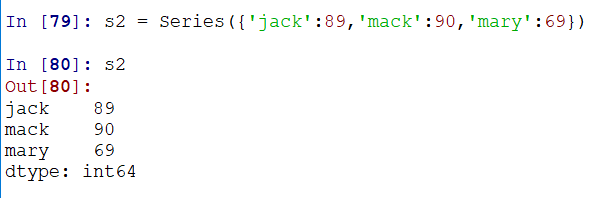
Series主要分为index、values两块
2.索引和切片
1).使用index作为索引值(不推荐)

2)使用升级为Series之后的loc()函数(推荐)
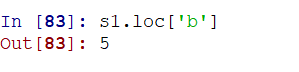
3)使用隐式索引(不显式指定索引的内容值,通过类似ndarray的索引风格取数据)

4)切片,可以直接[]或者loc形式

3.Series基本概念
1)常用属性:index、values、shape(一维的,所以只能是一个元素的元组)、size
2)可以通过head()、tail()等查看头部和尾部数据(类似linux的命令),只看前5个或者后5个
3)索引没有对应的值时,值会出现NaN,也就是数据缺失的情况,在np中使用np.nan表示这个空值,python中就是None表示了
4)可以使用 isnull()、notnull()来检测空值:
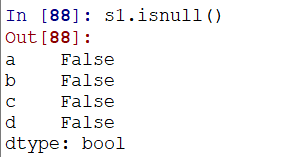
可以通过notnull()等进行空数据过滤:
s2 = s.notnull()
# 以下取出的便是为True的非空数据
s[s2]
5)每个Series都有一个name属性,可以在DataFrame中进行区分,在df中,也就相当于列名
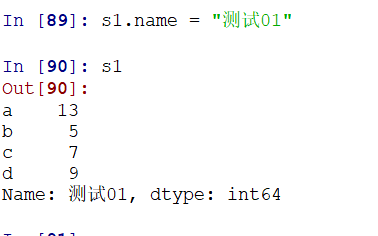
6)Series运算
可以正常的进行加减运算,其中None值不会参与计算,而ndarray值为None时为报错,为np.nan时计算结果为nan


或者通过s1.add(10,fill_value= 0)等形式来控制NaN的默认值
两个Series之间也可以运算,不对齐的部分(也就是索引不相等的部分),补充NaN

要保留index不对齐的部分,可以使用add()方法:,通过fill_value

数据分析入门——pandas之Series的更多相关文章
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 数据分析入门——Pandas类库基础知识
使用python进行数据分析时,经常会用Pandas类库处理数据,将数据转换成我们需要的格式.Pandas中的有两个数据结构和处理数据相关,分别是Series和DataFrame. Series Se ...
- 数据分析入门——pandas之DataFrame基本概念
一.介绍 数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列. 可以看作是Series的二维拓展,但是df有行列索引:index.column 推荐参考:https://www. ...
- 数据分析入门——pandas数据处理
1,处理重复数据 使用duplicated检测重复的行,返回一个series,如果不是第一次出现,也就是有重复行的时候,则为True: 对应的,可以使用drop_duplicates来删除重复的行: ...
- 数据分析入门——pandas之DataFrame多层/多级索引与聚合操作
一.行多层索引 1.隐式创建 在构造函数中给index.colunms等多个数组实现(datafarme与series都可以) df的多级索引创建方法类似: 2.显式创建pd.MultiIndex 其 ...
- 数据分析入门——pandas之DataFrame数据丢失
一.数据丢失分类 1)nd中分为两种:None和np.nan(NaN) 其中,None是python中的对象,是一个object:而nan是一个float类型 两种不同的类型,运算速度也是不同的 2) ...
- 数据分析之pandas库--series对象
1.Series属性及方法 Series是Pandas中最基本的对象,Series类似一种一维数组. 1.生成对象.创建索引并赋值. s1=pd.Series() 2.查看索引和值. s1=Serie ...
- 数据分析入门——pandas之数据合并
主要分为:级联:pd.concat.pd.append 合并:pd.merge 一.numpy级联的回顾 详细参考numpy章节 https://www.cnblogs.com/jiangbei/p/ ...
随机推荐
- Easy sssp(spfa判负环与求最短路)
#include<bits/stdc++.h> using namespace std; int n,m,s; struct node{ int to,next,w; }e[]; bool ...
- Laravel下载地址合集
laravel官网直接下载地址都没了. 都要用composer装? 在此记录一下直接下载地址 master https://github.com/laravel/laravel/archiv ...
- ORM框架三种映射在Springboot上的使用
ORM(对象/关系映射)是数据库层非常重要的一部分,有三种常用的映射关系 1.多对一 tbl_clazz clazz{ id name description grade_id charge_id } ...
- Yum 安装memcached 与缓存清空
1.安装 root@pts/0 # yum -y install memcached 2.启动服务 root@pts/0 # /etc/init.d/memcached start 3 ...
- Tiny C Compiler简介-wiki
Tiny C Compiler(缩写为TCC.tCc或TinyCC)是一个用于x86(16/32位)或x86-64(64位)系统的C编译器,开发者为Fabrice Bellard.软件是设计用于低级计 ...
- Kafka 通过python简单的生产消费实现
使用CentOS6.5.python3.6.kafkaScala 2.10 - kafka_2.10-0.8.2.2.tgz (asc, md5) 一.下载kafka 下载地址 https://ka ...
- learning java AWT 常见组件
import javax.swing.*; import java.awt.*; public class CommonComponent { Frame f = new Frame("te ...
- 1-STM32+W5500+GPRS物联网开发基础篇-工控板简介
最近这些日子都在忙活STM+W5500+GPRS的板子,所以前面的那块板子的教程耽搁了些时间. 这次的板子和上一版相比更贴近了使用,是因为有朋友督促我要做一块直接可以在工厂使用的板子,所以设计了这一块 ...
- 布鲁克斯法则 (Brooks's Law)
软件开发后期,添加人力只会使项目开发得更慢. 这个定律表明,在许多情况下,试图通过增加人力来加速延期项目的交付,将会使项目交付得更晚.布鲁克斯也明白,这是一种过度简化.但一般的推理是,新资源的增加时间 ...
- Ubuntu下面删除和卸载软件
1.卸载nginx 1)首先执行第一条命令查出想关的软件包: dpkg --get-selections | grep nginx 2)开始执行卸载列出的common 和core 这个2个安装包 一个 ...