数据分析入门——pandas之DataFrame基本概念
一、介绍
数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列。
可以看作是Series的二维拓展,但是df有行列索引:index、column
推荐参考:https://www.jianshu.com/p/c534e83d2f4b
二、快速入门
1.打开csv

发现报错,原因是路径中\User的\u和转义符号冲突了,我们使用字符串中的知识,添加r开头表示不转义即可:
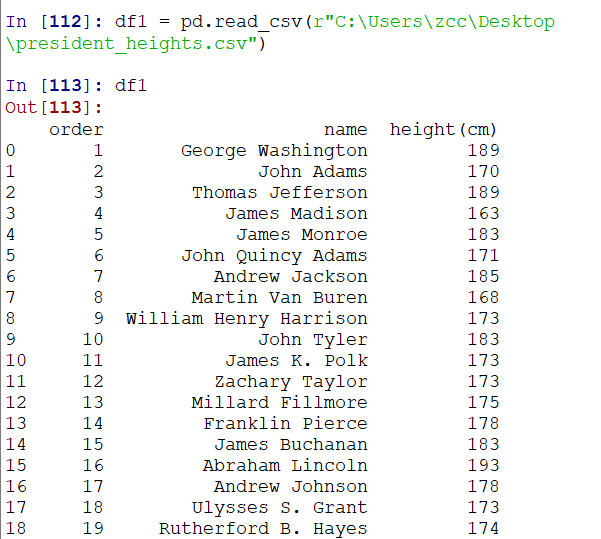
它包含的是行列索引和值values,value对应的就是二维的ndarray了
2.创建df
1.通过字典来创建df

可以通过index属性来控制索引,column同理:(在创建以后通过df.index = []的属性赋值也可以实现控制索引的)

2.可以通过列表来创建,给定ndarray,再给定Index和columns来构造df
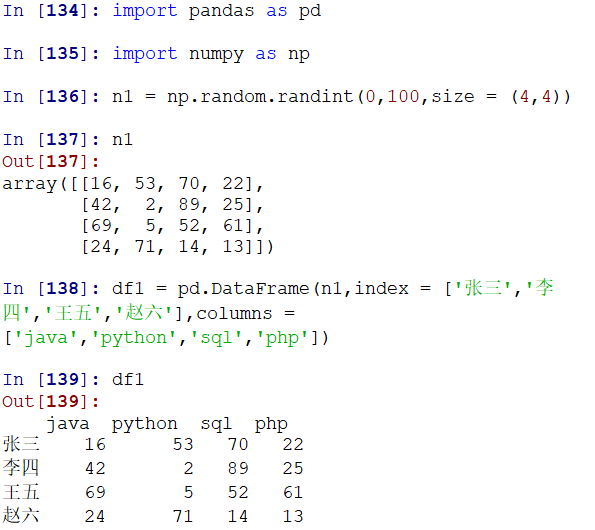
参考:https://www.yiibai.com/pandas/python_pandas_dataframe.html
3.df的索引
列索引:
通过列的索引检索,可以返回对应的列,也就是之前的Series

行索引:
使用loc或者iloc进行索引(其中,前者是显式索引,需要指定索引的值,后者是隐式索引,已过时的ix方法不再展开)
使用loc检索出一行,发现结果也是Series:

需要检索多行时,需要两个中括号(并且返回的也是DataFrame):

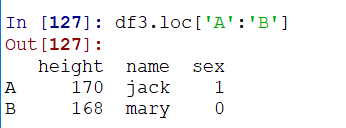
并且loc是支持切片(左右的闭区间)的:(支持的是行切片,如果切片范围不存在,则返回空数据,而不是报错)
隐式索引是类似的:(但是iloc的切片是左闭右开,与上面稍有不符合)

//存在部分bug:汉字索引有个别索引不生效,无法检索
元素索引:
可以通过线检索出某一列,再操作这个列Series(注意使用loc的推荐方法):

其他变通形式同理:

上面这个简写就变成:这就是行索引的变通形式

4)DataFrame的数据查看
1.通过head()、tail()查看头几行或者尾几行(默认n = 5):

2.通过a.index ; a.columns ; a.values 即可查看对应属性
3.a.sort_index(axis=1,ascending=False);
其中axis=1表示对所有的columns进行排序,下面的数也跟着发生移动。后面的ascending=False表示按降序排列,参数缺失时默认升序。
三、DataFrame的运算
1.DF之间的运算
构建的df1、df2如下:(用于后续计算)
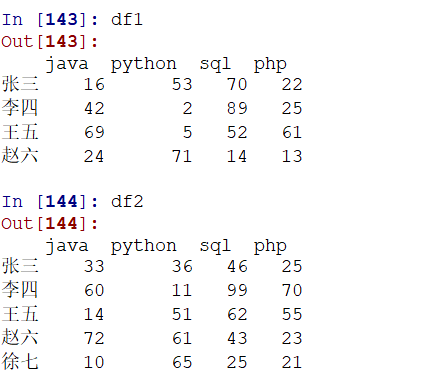
其实总结下来就是,行列索引相同的(也就是需要对齐再相加,无法对齐时使用NaN对齐,列会取并集,行值不对齐时使用默认NaN),进行计算,没有的全部用空进行计算(参考https://blog.csdn.net/weixin_34208283/article/details/86005233)
https://blog.csdn.net/weixin_33966095/article/details/88446784

需要避免NaN值可以使用pandas的add方法的fill_value来控制:

2.DF与Series之间的运算
直接运算,发现结果并不如人意:

提取行发现可以计算:

这也就是Series中的广播规则,默认情况下是s的index和df的columns进行对齐的,第二个对齐后的操作,看数据知道是广播成了四行与df对齐,可以通过 axis来进行广播控制(0表示在列上广播,1表示在行上广播)
数据分析入门——pandas之DataFrame基本概念的更多相关文章
- 数据分析入门——pandas之DataFrame数据丢失
一.数据丢失分类 1)nd中分为两种:None和np.nan(NaN) 其中,None是python中的对象,是一个object:而nan是一个float类型 两种不同的类型,运算速度也是不同的 2) ...
- 数据分析入门——pandas之DataFrame多层/多级索引与聚合操作
一.行多层索引 1.隐式创建 在构造函数中给index.colunms等多个数组实现(datafarme与series都可以) df的多级索引创建方法类似: 2.显式创建pd.MultiIndex 其 ...
- 数据分析入门——pandas之Series
一.介绍 Pandas是一个开源的,BSD许可的库(基于numpy),为Python编程语言提供高性能,易于使用的数据结构和数据分析工具. 官方中文文档:https://www.pypandas.cn ...
- 数据分析入门——Pandas类库基础知识
使用python进行数据分析时,经常会用Pandas类库处理数据,将数据转换成我们需要的格式.Pandas中的有两个数据结构和处理数据相关,分别是Series和DataFrame. Series Se ...
- 数据分析入门——pandas数据处理
1,处理重复数据 使用duplicated检测重复的行,返回一个series,如果不是第一次出现,也就是有重复行的时候,则为True: 对应的,可以使用drop_duplicates来删除重复的行: ...
- 数据分析入门——pandas之数据合并
主要分为:级联:pd.concat.pd.append 合并:pd.merge 一.numpy级联的回顾 详细参考numpy章节 https://www.cnblogs.com/jiangbei/p/ ...
- 数据分析入门——pandas之合并函数merge
merge有点类似SQL中的join,可以将不同数据集按照某些字段进行合并,得到新的数据集 1.参数一览表: 2.一对一连接:默认情况下,会按照相同字段的进行连接 例如有相同字段emp的两个df,m ...
- Python数据分析入门之pandas基础总结
Pandas--"大熊猫"基础 Series Series: pandas的长枪(数据表中的一列或一行,观测向量,一维数组...) Series1 = pd.Series(np.r ...
- 利用python进行数据分析之pandas入门
转自https://zhuanlan.zhihu.com/p/26100976 目录: 5.1 pandas 的数据结构介绍5.1.1 Series5.1.2 DataFrame5.1.3索引对象5. ...
随机推荐
- 均分纸牌(Noip2002)
1320:[例6.2]均分纸牌(Noip2002) 时间限制: 1000 ms 内存限制: 65536 KB提交数: 3537 通过数: 1839 [题目描述] 有n堆纸牌,编 ...
- JOIN序列化过程中日期的处理
一.在后台进行处理: System.Web.Script.Serialization.JavaScriptSerializer js = new System.Web.Script.Serializa ...
- 2019-2020-1 20199312《Linux内核原理与分析》第七周作业
进程的描述 操作系统内核实现操作系统的三大管理功能 进程管理(内核中最核心的功能) 内存管理 文件系统 在操作系统中,我们通过进程控制块PCB描述进程. 为了管理进程,内核必须对每个进程进行清晰的描述 ...
- python中类的函数中的self
Python类中的self到底是干啥的 Python编写类的时候,每个函数参数第一个参数都是self,一开始我不管它到底是干嘛的,只知道必须要写上.后来对Python渐渐熟悉了一点,再回头看self的 ...
- JQuery购物车多物品数量的加减+总价计算
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 一文读懂后缀自动机 Suffix_Automata
原论文(俄文)地址:suffix_automata 原翻译(中文)地址:后缀自动机详解(DZYO的博客) Upd:强推浅显易懂(?)的SAM讲解 后缀自动机 后缀自动机(单词的有向无环图)--是一种强 ...
- 项目架构&架构部署&网站分析&网站优化
一.架构演变 一个项目至少由三层内容组成:web访问层.数据库层.存储层 初级阶段 单体阶段 常见场景:项目初期 部署特点:所有应用服务都在一台主机 应用特点:开发简单 应用/数据分离阶段 常见场景: ...
- html 摄像头画面水平翻转
<video onloadedmetadata="" id="inputVideo" autoplay muted playsinline>< ...
- Codeforces Round #557 题解【更完了】
Codeforces Round #557 题解 掉分快乐 CF1161A Hide and Seek Alice和Bob在玩捉♂迷♂藏,有\(n\)个格子,Bob会检查\(k\)次,第\(i\)次检 ...
- 36、将RDD转换为DataFrame
一.概述 为什么要将RDD转换为DataFrame? 因为这样的话,我们就可以直接针对HDFS等任何可以构建为RDD的数据,使用Spark SQL进行SQL查询了.这个功能是无比强大的. 想象一下,针 ...