AUC,ROC我看到的最透彻的讲解
面试的时候,一句话说明AUC的本质和计算规则:
AUC:一个正例,一个负例,预测为正的概率值比预测为负的概率值还要大的可能性。
所以根据定义:我们最直观的有两种计算AUC的方法
1:绘制ROC曲线,ROC曲线下面的面积就是AUC的值
2:假设总共有(m+n)个样本,其中正样本m个,负样本n个,总共有m*n个样本对,计数,正样本预测为正样本的概率值大于负样本预测为正样本的概率值记为1,累加计数,然后除以(m*n)就是AUC的值
PS:百度百科,随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。这里的score值就是预测为正的概率的值,排在前面表示的是正样本的预测为正的概率值大于负样本的预测为正的概率值
一、roc曲线
1、roc曲线:接收者操作特征(receiveroperating characteristic),roc曲线上每个点反映着对同一信号刺激的感受性。
横轴:负正类率(false postive rate FPR)特异度,划分实例中所有负例占所有负例的比例;(1-Specificity)
纵轴:真正类率(true postive rate TPR)灵敏度,Sensitivity(正类覆盖率)
2针对一个二分类问题,将实例分成正类(postive)或者负类(negative)。但是实际中分类时,会出现四种情况.
(1)若一个实例是正类并且被预测为正类,即为真正类(True Postive TP)
(2)若一个实例是正类,但是被预测成为负类,即为假负类(False Negative FN)
(3)若一个实例是负类,但是被预测成为正类,即为假正类(False Postive FP)
(4)若一个实例是负类,但是被预测成为负类,即为真负类(True Negative TN)
TP:正确的肯定数目
FN:漏报,没有找到正确匹配的数目
FP:误报,没有的匹配不正确
TN:正确拒绝的非匹配数目
列联表如下,1代表正类,0代表负类:
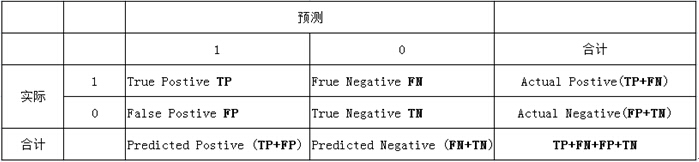
由上表可得出横,纵轴的计算公式:
(1)真正类率(True Postive Rate)TPR: TP/(TP+FN),代表分类器预测的正类中实际正实例占所有正实例的比例。Sensitivity
(2)负正类率(False Postive Rate)FPR: FP/(FP+TN),代表分类器预测的正类中实际负实例占所有负实例的比例。1-Specificity
(3)真负类率(True Negative Rate)TNR: TN/(FP+TN),代表分类器预测的负类中实际负实例占所有负实例的比例,TNR=1-FPR。Specificity
假设采用逻辑回归分类器,其给出针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组(FPR,TPR),在平面中得到对应坐标点。随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。
如下面这幅图,(a)图中实线为ROC曲线,线上每个点对应一个阈值。
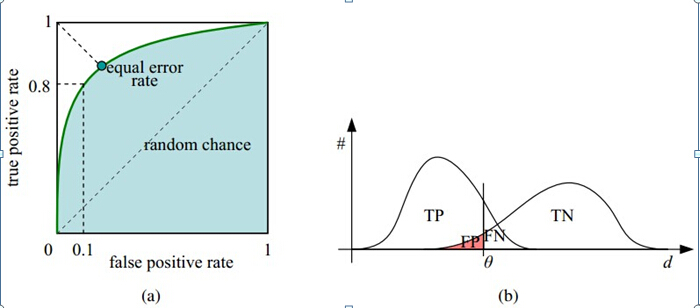
横轴FPR:1-TNR,1-Specificity,FPR越大,预测正类中实际负类越多。
纵轴TPR:Sensitivity(正类覆盖率),TPR越大,预测正类中实际正类越多。
理想目标:TPR=1,FPR=0,即图中(0,1)点,故ROC曲线越靠拢(0,1)点,越偏离45度对角线越好,Sensitivity、Specificity越大效果越好。
二 如何画roc曲线
假设已经得出一系列样本被划分为正类的概率,然后按照大小排序,下图是一个示例,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。
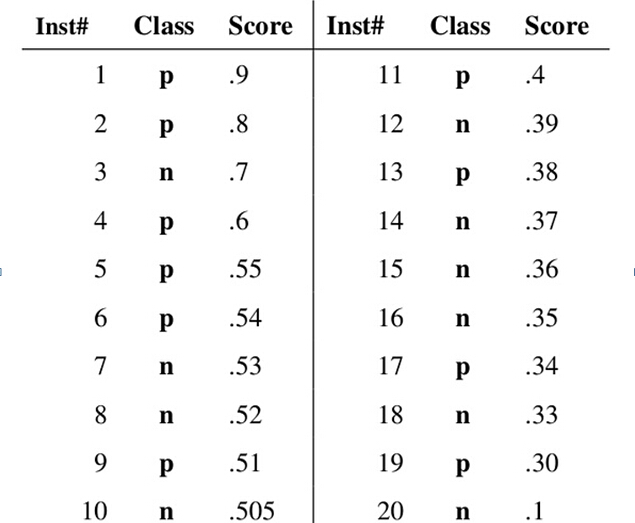
接下来,我们从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值,将它们画在ROC曲线的结果如下图:
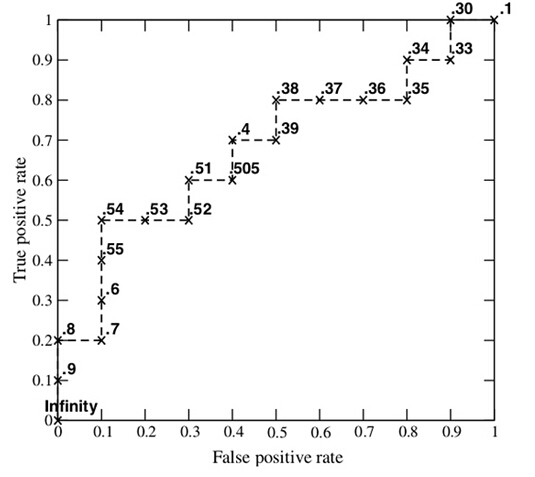
AUC(Area under Curve):Roc曲线下的面积,介于0.1和1之间。Auc作为数值可以直观的评价分类器的好坏,值越大越好。
首先AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
二、AUC计算
1. 最直观的,根据AUC这个名称,我们知道,计算出ROC曲线下面的面积,就是AUC的值。事实上,这也是在早期 Machine Learning文献中常见的AUC计算方法。由于我们的测试样本是有限的。我们得到的AUC曲线必然是一个阶梯状的。因此,计算的AUC也就是这些阶梯 下面的面积之和。这样,我们先把score排序(假设score越大,此样本属于正类的概率越大),然后一边扫描就可以得到我们想要的AUC。但是,这么 做有个缺点,就是当多个测试样本的score相等的时候,我们调整一下阈值,得到的不是曲线一个阶梯往上或者往右的延展,而是斜着向上形成一个梯形。此 时,我们就需要计算这个梯形的面积。由此,我们可以看到,用这种方法计算AUC实际上是比较麻烦的。
2. 一个关于AUC的很有趣的性质是,它和Wilcoxon-Mann-Witney Test是等价的。这个等价关系的证明留在下篇帖子中给出。而Wilcoxon-Mann-Witney Test就是测试任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score。有了这个定义,我们就得到了另外一中计 算AUC的办法:得到这个概率。我们知道,在有限样本中我们常用的得到概率的办法就是通过频率来估计之。这种估计随着样本规模的扩大而逐渐逼近真实值。这 和上面的方法中,样本数越多,计算的AUC越准确类似,也和计算积分的时候,小区间划分的越细,计算的越准确是同样的道理。具体来说就是统计一下所有的 M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score相等的时候,按照0.5计算。然后除以MN。实现这个方法的复杂度为O(n^2)。n为样本数(即n=M+N)
3. 第三种方法实际上和上述第二种方法是一样的,但是复杂度减小了。它也是首先对score从大到小排序,然后令最大score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推。然后把所有的正类样本的rank相加,再减去M-1种两个正样本组合的情况。得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。然后再除以M×N。即
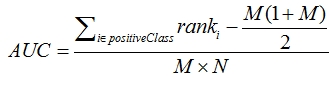
公式解释:
1、为了求的组合中正样本的score值大于负样本,如果所有的正样本score值都是大于负样本的,那么第一位与任意的进行组合score值都要大,我们取它的rank值为n,但是n-1中有M-1是正样例和正样例的组合这种是不在统计范围内的(为计算方便我们取n组,相应的不符合的有M个),所以要减掉,那么同理排在第二位的n-1,会有M-1个是不满足的,依次类推,故得到后面的公式M*(M+1)/2,我们可以验证在正样本score都大于负样本的假设下,AUC的值为1
2、根据上面的解释,不难得出,rank的值代表的是能够产生score前大后小的这样的组合数,但是这里包含了(正,正)的情况,所以要减去这样的组(即排在它后面正例的个数),即可得到上面的公式
另外,特别需要注意的是,再存在score相等的情况时,对相等score的样本,需要 赋予相同的rank(无论这个相等的score是出现在同类样本还是不同类的样本之间,都需要这样处理)。具体操作就是再把所有这些score相等的样本 的rank取平均。然后再使用上述公式。
AUC,ROC我看到的最透彻的讲解的更多相关文章
- AUC ROC PR曲线
ROC曲线: 横轴:假阳性率 代表将负例错分为正例的概率 纵轴:真阳性率 代表能将正例分对的概率 AUC是ROC曲线下面区域得面积. 与召回率对比: AUC意义: 任取一对(正.负)样本,把正样本预测 ...
- sqlite的事务和锁,很透彻的讲解 【转】
原文:sqlite的事务和锁 http://3y.uu456.com/bp-877d38906bec097sf46se240-1.html 事务 事务定义了一组SQL命令的边界,这组命令或者作为一个整 ...
- ROC AUC
1.什么是性能度量? 我们都知道机器学习要建模,但是对于模型性能的好坏(即模型的泛化能力),我们并不知道是怎样的,很可能这个模型就是一个差的模型,泛化能力弱,对测试集不能很好的预测或分类.那么如何知道 ...
- 机器学习性能指标(ROC、AUC、召回率)
混淆矩阵 构造一个高正确率或高召回率的分类器比较容易,但很难保证二者同时成立 ROC 横轴:FPR(假正样本率)=FP/(FP+TN) 即,所有负样本中被分错的比例 纵轴:TPR(真正样本率)=TP/ ...
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
原文地址:http://blog.csdn.net/pkueecser/article/details/8229166 在信息检索.分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常 ...
- 评估分类器性能的度量,像混淆矩阵、ROC、AUC等
评估分类器性能的度量,像混淆矩阵.ROC.AUC等 内容概要¶ 模型评估的目的及一般评估流程 分类准确率的用处及其限制 混淆矩阵(confusion matrix)是如何表示一个分类器的性能 混淆矩阵 ...
- ROC与AUC原理
来自:https://blog.csdn.net/shenxiaoming77/article/details/72627882 来自:https://blog.csdn.net/u010705209 ...
- ROC,AUC,Precision,Recall,F1的介绍与计算(转)
1. 基本概念 1.1 ROC与AUC ROC曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣,ROC曲线称为受试者工作特征曲线 (receiver operatin ...
- ROC,AUC,Precision,Recall,F1的介绍与计算
1. 基本概念 1.1 ROC与AUC ROC曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣,ROC曲线称为受试者工作特征曲线 (receiver operatin ...
随机推荐
- flutter入门开发的一些坑
flutter入门开发的一些坑 很久没写博客了,最近在准备物联网比赛,顺便抽出时间学习了一下flutter,花了近2周完成了一个查看博客博文的一个小的APPdemo,随便截了两张图,如下: 首页 博客 ...
- IDEA实用教程(十)—— 配置Maven的全局设置
使用之前需要提前安装好Maven 第一步 第二步
- 乔布斯在位时,库克实质上已经在做CEO的工作了:3星|《蒂姆·库克传》
“ 一些人认为艾夫是接替乔布斯的热门人选,他对苹果的原晃和产品来说至关重要,但他本人对管理企业却毫无兴趣.艾夫想继统做设计.在苹果,他拥有所有设计师都梦寐以求的工作环境——无限的资源和自由创作的空间. ...
- LGOJP1941 飞扬的小鸟
题目链接 题目链接 题解 \(f[i][j]\)表示位置\((i,j)\)到达需要的最小点击数. \(f[i][j]=\min\{{f[i-1][j-kx]+k},f[i-1][j+y]\}\) \( ...
- xss获取cookie源码附利用代码
保存为cookie.asp <% testfile=Server.MapPath("cookies.txt") msg=Request("msg") se ...
- Python爬取微信公众号素材库
这是我的之前写的代码,今天发布到博客园上,说不定以后需要用. 开始: #coding:utf-8 import werobot import pymongo class Gongzhonghao( ...
- CH6803 导弹防御塔
6803 导弹防御塔 0x60「图论」例题 背景 Freda的城堡-- "Freda,城堡外发现了一些入侵者!" "喵...刚刚探究完了城堡建设的方案数,我要歇一会儿嘛l ...
- Oracle中修改某个字段可以为空
待修改字段假定为:shuifen 1.当该字段为空时,可直接修改: alter table reportqymx modify shuifen null; 2.当待修改字段不为空时:新增一列把要改变的 ...
- 基于 Redis 实现简单的分布式锁
摘要 分布式锁在很多应用场景下是非常有效的手段,比如当运行在多个机器上的不同进程需要访问同一个竞争资源的时候,那么就会涉及到进程对资源的加锁和释放,这样才能保证数据的安全访问.分布式锁实现的方案有很多 ...
- Homebrew 更新慢问题
cd "$(brew --repo)" git remote set-url origin https://mirrors.tuna.tsinghua.edu.cn/git/hom ...