004 Spark中的local模式的配置以及测试
一:介绍
1.Spark的模式
Local:本地运行模式,主要用于开发、测试
Standalone:使用Spark自带的资源管理框架运行Spark程序,30%左右
Yarn: 将spark应用程序运行在yarn上,绝大多数使用情况,60%左右,因为已经有了一个hadoop框架,就不再再搭建standalone框架了
Mesos:
二:Local模式安装
1.解压
使用自己编译产生的tgz压缩包。

2.建立软连接

3.复制配置文件

4.修改env.sh文件

三:运行测试
1.启动HDFS

2.准备测试路径

3.开始测试
./run-example SparkPi 10<----------------10代表迭代的次数

4.shell的测试

5.shell效果

四:问题(HDFS问啥要启动的问题)
1.HDFS启动的原因
如果不启动HDFS,在./spark-shell的时候会出现错误。

2.不启动HDFS会出现的问题

3.下面的配置是真正的spark local,不再需要考虑hadoop

4.启动./spark-shell
没有其他服务。

可以成功启动。

五:页面
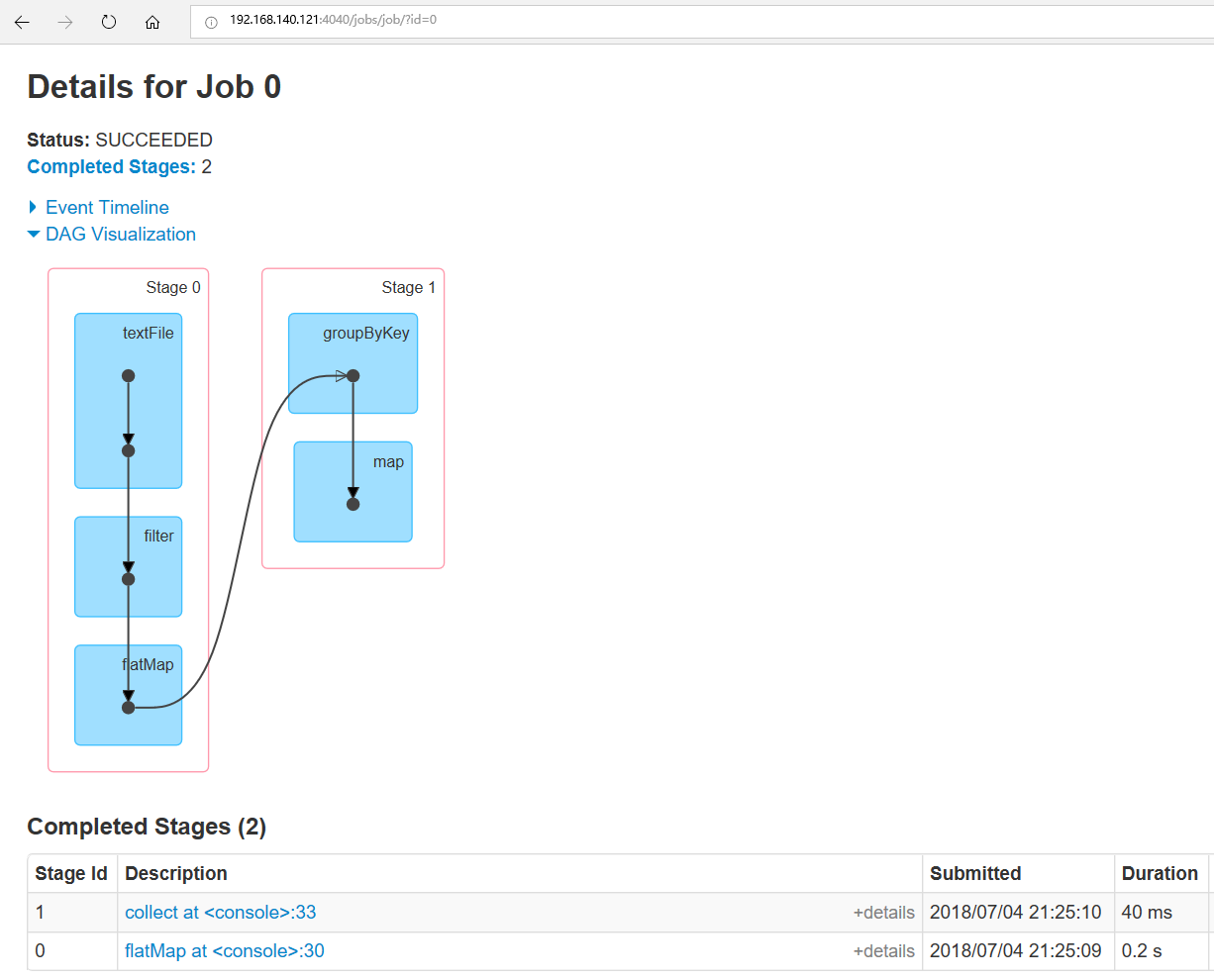
1.程序示例
这个是后来的补充。
sc.textFile("/user/beifeng/mapreduce/wordcount/input/wc.input").
filter(_.length>0).
flatMap(_.split(" ").map((_,1))).
groupByKey().
map(tuple=>(tuple._1,tuple._2.toList.sum)).
collect()
2.4040端口可以访问
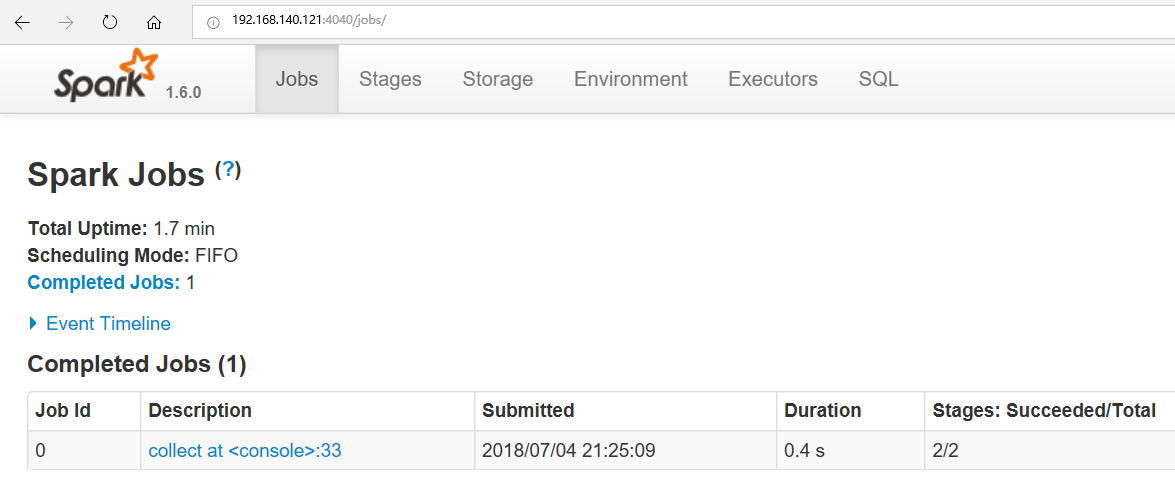 、
、
点进去:
004 Spark中的local模式的配置以及测试的更多相关文章
- Qt中的非模式窗口配置;
Test7_5A::Test7_5A(QWidget *parent) : QMainWindow(parent){ ui.setupUi(this); m_searchwin = new Searc ...
- 在idea中调试spark程序-配置windows上的 spark local模式
spark程序大致有如下运行模式: standalone模式:spark自带的模式 spark on yarn:利用hadoop yarn来做集群的资源管理 local模式:主要在测试的时候使用, 这 ...
- 【原】Storm Local模式和生产环境中Topology运行配置
Storm入门教程 1. Storm基础 Storm Storm主要特点 Storm基本概念 Storm调度器 Storm配置 Guaranteeing Message Processing(消息处理 ...
- IntelliJ IDEA在Local模式下Spark程序消除日志中INFO输出
在使用Intellij IDEA,local模式下运行Spark程序时,会在Run窗口打印出很多INFO信息,辅助信息太多可能会将有用的信息掩盖掉.如下所示 要解决这个问题,主要是要正确设置好log4 ...
- 012 Spark在IDEA中打jar包,并在集群上运行(包括local模式,standalone模式,yarn模式的集群运行)
一:打包成jar 1.修改代码 2.使用maven打包 但是目录中有中文,会出现打包错误 3.第二种方式 4.下一步 5.下一步 6.下一步 7.下一步 8.下一步 9.完成 二:在集群上运行(loc ...
- 010 Spark中的监控----日志聚合的配置,以及REST Api
一:History日志聚合的配置 1.介绍 Spark的日志聚合功能不是standalone模式独享的,是所有运行模式下都会存在的情况 默认情况下历史日志是保存到tmp文件夹中的 2.参考官网的知识点 ...
- spark on yarn模式下配置spark-sql访问hive元数据
spark on yarn模式下配置spark-sql访问hive元数据 目的:在spark on yarn模式下,执行spark-sql访问hive的元数据.并对比一下spark-sql 和hive ...
- spark运行模式之一:Spark的local模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- local模式运行spark-shell时报错 java.lang.IllegalArgumentException: Error while instantiating 'org.apache.spark.sql.hive.HiveSessionState':
先前在local模式下,什么都不做修改直接运行./spark-shell 运行什么问题都没有,然后配置过在HADOOP yarn上运行,之后再在local模式下运行出现以下错误: java.lang. ...
随机推荐
- 工控安全入门之Modbus(转载)
工控安全这个领域比较封闭,公开的资料很少.我在读<Hacking Exposed Industrial Control Systems>,一本16年的书,选了的部分章节进行翻译,以其抛砖引 ...
- Postfix 邮件服务 - dovecot 服务
dovecot 是一个开源的IMAP和POP3邮件服务器 收件协议 (SMTP 传输发件)POP/IMAP 是MUA从邮件服务器中读取邮件时使用的协议.其中,与POP3是从邮件服务器中下载邮件存起来, ...
- mysql 查询优化 ~explain解读之type的解读
一 简介:今天咱们来聊聊explain中type的相关解读 二 类型: system: 表中只有一条数据. 这个类型是特殊的 const 类型. const: 针对主键或唯一索引的等值查询扫描, 最 ...
- 不断更新的 ToDo-List
有些事情要明着写出来才会去干. 这里是一个不断更新的 ToDo-List,大致按照重要度和列出时间排序,已经完成的会画上删除线. 主要着眼短期计划,其中的大部分事务应该在一周内解决,争取不做一只鸽子. ...
- 网络常用的linux系统调用
网络之常用的Linux系统调用 下面一些函数已经过时,被新的更好的函数所代替了(gcc在链接这些函数时会发出警告),但因为兼容的原因还保留着,这些函数将在前面标上“*”号以示区别. 一.进程控制 fo ...
- 【sky第二期--PID算法】--【智能车论坛】
[sky第二期--PID算法] 想学PID的可以来[智能车论坛]这里有我发布的资料http://bbs.tekbots.eefocus.com/forum.php?mod=viewthread& ...
- MySQL占用IO过高解决方案【转】
1.日志产生的性能影响: 由于日志的记录带来的直接性能损耗就是数据库系统中最为昂贵的IO资源.MySQL的日志包括错误日志(ErrorLog),更新日志(UpdateLog),二进制日志(Binlog ...
- 移动端中遇到的坑(bug)!!!
1.模拟单选点击的时候,在ios手机下,点击下面的内容选择,会出现页面闪一闪!! 解决方案:样式重置html的时候加上这句 -webkit-tap-highlight-color: rgba(0, ...
- HTML学习笔记06-连接
HTML超链接 HTML使用标签<a>来设置文本超链接. 超链接可以是文字,也可以是图片,点击这些内容跳转到新的文档或当前文档的某个部分 代码类似这样: <a href=" ...
- MVC 带扩展名的路由无法访问
在MVC中,路由是必不可少的,而且MVC对Url的重写非常方便,只需要在路由中配置相应的规则即可.假如我们需要给信息详情页配置路由,代码如下: routes.MapRoute( name: " ...