孤立森林(Isolation Forest)
前言
随着机器学习近年来的流行,尤其是深度学习的火热。机器学习算法在很多领域的应用越来越普遍。最近,我在一家广告公司做广告点击反作弊算法研究工作。想到了异常检测算法,并且上网调研发现有一个算法非常火爆,那就是本文要介绍的算法 Isolation Forest,简称 iForest 。
南大周志华老师的团队在2010年提出一个异常检测算法Isolation Forest,在工业界很实用,算法效果好,时间效率高,能有效处理高维数据和海量数据,这里对这个算法进行简要总结。
1. iTree的构造
提到森林,自然少不了树,毕竟森林都是由树构成的,看Isolation Forest(简称iForest)前,我们先来看看Isolation Tree(简称iTree)是怎么构成的。iTree是一种随机二叉树,每个节点要么有两个女儿,要么就是叶子节点,一个孩子都没有。给定一堆数据集D,这里D的所有属性都是连续型的变量,iTree的构成过程如下:
1、随机选择一个属性Attr。
2、随机选择该属性的一个值Value。
3、根据Attr对每条记录进行分类,把Attr小于Value的记录放在左女儿,把大于等于Value的记录放在右孩子。
4、然后递归的构造左女儿和右女儿,直到满足以下条件:
1、传入的数据集只有一条记录或者多条一样的记录。
2、树的高度达到了限定高度。

iTree构建好了后,就可以对数据进行预测啦。预测的过程就是把测试记录在iTree上走一下,看测试记录落在哪个叶子节点。iTree能有效检测异常的假设是:异常点一般都是非常稀有的,在iTree中会很快被划分到叶子节点。
批注:异常点一般来说是稀疏的,因此可以用较少次划分把它归结到单独的区域中。或者说只包含它的空间的面积较大。
因此可以用叶子节点到根节点的路径h(x)长度来判断一条记录x是否是异常点。对于一个包含n条记录的数据集,其构造的树的高度最小值为log(n),最大值为n-1,论文提到说用log(n)和n-1归一化不能保证有界和不方便比较,用一个稍微复杂一点的归一化公式: 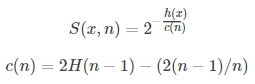
其中 为欧拉常数。
为欧拉常数。
S(x,n)就是记录x在由n个样本的训练数据构成的iTree的异常指数,S(x,n)取值范围为[0,1]异常情况的判断分以下几种情况:
1、越接近1表示是异常点的可能性高;
2、越接近0表示是正常点的可能性比较高;
3、如果大部分的训练样本的S(x,n)都接近于0.5,说明整个数据集都没有明显的异常值。
由于是随机选属性,随机选属性值,一棵树这么随便搞肯定是不靠谱,但是把多棵树结合起来就变强大了。
2. iForest的构造
iTree搞明白了,我们现在来看看iForest是怎么构造的,给定一个包含n条记录的数据集D,如何构造一个iForest。iForest和Random Forest的方法有些类似,都是随机采样一部分数据集去构造每一棵树,保证不同树之间的差异性,不过iForest与RF不同,采样的数据量Psi不需要等于n,可以远远小于n,论文中提到采样大小超过256效果就提升不大了,并且越大还会造成计算时间的上的浪费,为什么不像其他算法一样,数据越多效果越好呢,可以看看下面这两个个图:
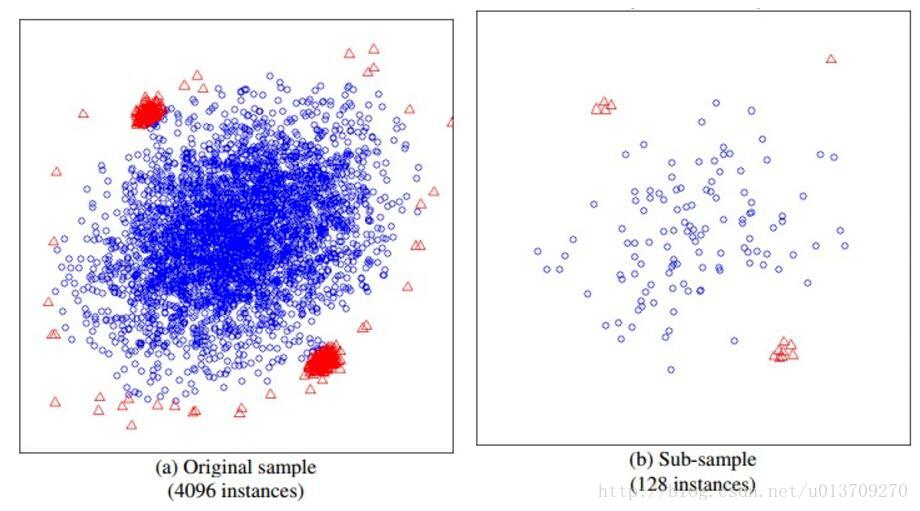
左边是原始数据,右边是采样了数据,蓝色是正常样本,红色是异常样本。可以看到,在采样之前,正常样本和异常样本出现重叠,因此很难分开,但我们采样之和,异常样本和正常样本可以明显的分开。
除了限制采样大小Ψ以外,还要给每棵iTree设置最大高度l=ceiling(log2Ψ),这是因为异常数据记录都比较少,其路径长度也比较低,而我们也只需要把正常记录和异常记录区分开来,因此只需要关心低于平均高度的部分就好,这样算法效率更高,不过这样调整了后,后面可以看到计算h(x)需要一点点改进,先看iForest的伪代码:

IForest构造好后,对测试进行预测时,需要进行综合每棵树的结果,于是 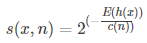
E(h(x))表示记录x在每棵树的高度均值,另外h(x)计算需要改进,在生成叶节点时,算法记录了叶节点包含的记录数量,这时候要用这个数量Size估计一下平均高度,h(x)的计算方法如下:

3. 对高维数据的处理
在处理高维数据时,可以对算法进行改进,采样之后并不是把所有的属性都用上,而是用峰度系数Kurtosis挑选一些有价值的属性,再进行iTree的构造,这跟随机森林就更像了,随机选记录,再随机选属性。
4. 只使用正常样本
这个算法本质上是一个无监督学习,不需要数据的类标,有时候异常数据太少了,少到我们只舍得拿这几个异常样本进行测试,不能进行训练,论文提到只用正常样本构建IForest也是可行的,效果有降低,但也还不错,并可以通过适当调整采样大小来提高效果。
5. 总结
(1) iForest具有线性时间复杂度。因为是ensemble的方法,所以可以用在含有海量数据的数据集上面。通常树的数量越多,算法越稳定。由于每棵树都是互相独立生成的,因此可以部署在大规模分布式系统上来加速运算。
(2) iForest不适用于特别高维的数据。由于每次切数据空间都是随机选取一个维度,建完树后仍然有大量的维度信息没有被使用,导致算法可靠性降低。高维空间还可能存在大量噪音维度或无关维度(irrelevant attributes),影响树的构建。对这类数据,建议使用子空间异常检测(Subspace Anomaly Detection)技术。此外,切割平面默认是axis-parallel的,也可以随机生成各种角度的切割平面,详见“On Detecting Clustered Anomalies Using SCiForest”。
(3) iForest仅对Global Anomaly 敏感,即全局稀疏点敏感,不擅长处理局部的相对稀疏点 (Local Anomaly)。目前已有改进方法发表于PAKDD,详见“Improving iForest with Relative Mass”。
(4) iForest推动了重心估计(Mass Estimation)理论发展,目前在分类聚类和异常检测中都取得显著效果,发表于各大顶级数据挖掘会议和期刊(如SIGKDD,ICDM,ECML)。
转自:https://blog.csdn.net/u013709270/article/details/73436588/
孤立森林(Isolation Forest)的更多相关文章
- 【异常检测】孤立森林(Isolation Forest)算法简介
简介 工作的过程中经常会遇到这样一个问题,在构建模型训练数据时,我们很难保证训练数据的纯净度,数据中往往会参杂很多被错误标记噪声数据,而数据的质量决定了最终模型性能的好坏.如果进行人工二次标记,成本会 ...
- 异常值检测方法(Z-score,DBSCAN,孤立森林)
机器学习_深度学习_入门经典(博主永久免费教学视频系列) https://study.163.com/course/courseMain.htm?courseId=1006390023&sh ...
- 孤立森林(isolation forest)
1.简介 孤立森林(Isolation Forest)是另外一种高效的异常检测算法,它和随机森林类似,但每次选择划分属性和划分点(值)时都是随机的,而不是根据信息增益或者基尼指数来选择. 在建树过程中 ...
- Python机器学习笔记 异常点检测算法——Isolation Forest
Isolation,意为孤立/隔离,是名词,其动词为isolate,forest是森林,合起来就是“孤立森林”了,也有叫“独异森林”,好像并没有统一的中文叫法.可能大家都习惯用其英文的名字isolat ...
- [转]Python机器学习笔记 异常点检测算法——Isolation Forest
Isolation,意为孤立/隔离,是名词,其动词为isolate,forest是森林,合起来就是“孤立森林”了,也有叫“独异森林”,好像并没有统一的中文叫法.可能大家都习惯用其英文的名字isolat ...
- isolation forest进行异常点检测
一.简介 孤立森林(Isolation Forest)是另外一种高效的异常检测算法,它和随机森林类似,但每次选择划分属性和划分点(值)时都是随机的,而不是根据信息增益或者基尼指数来选择.在建树过程中, ...
- [置顶]
Isolation Forest算法原理详解
本文只介绍原论文中的 Isolation Forest 孤立点检测算法的原理,实际的代码实现详解请参照我的另一篇博客:Isolation Forest算法实现详解. 或者读者可以到我的GitHub上去 ...
- 26.异常检测---孤立森林 | one-class SVM
novelty detection:当训练数据中没有离群点,我们的目标是用训练好的模型去检测另外发现的新样本 outlier dection:当训练数据中包含离群点,模型训练时要匹配训练数据的中心样 ...
- (转)isolation forest进行异常点检测
原文链接:https://www.cnblogs.com/gczr/p/9156971.html 一.简介 孤立森林(Isolation Forest)是另外一种高效的异常检测算法,它和随机森林类似, ...
随机推荐
- JavaScript学习笔记--语言工具的了解
基础学习,快速入门资料:网站 https://www.liaoxuefeng.com ,http://www.runoob.com/js/js-tutorial.html 笔记: 编程工具:SubLi ...
- RN animated缩放动画
效果图: 代码: import React, {Component} from 'react'; import { AppRegistry, StyleSheet, Text, Animated, T ...
- SUDO安全委派和安全模块
sudo更换身份 su 切换身份 使用su 切换身份必须首先直到被切换成用户的密码 如: su root 就必须要知道root的密码 这种机制安全性不高,容易泄露管理员密码 1. sudo ...
- PS游戏摸拟器ePSXe加速游戏速度方法
1.启动ePSXe游戏摸拟器. 2.菜单栏上的设置->视频->在视频设置窗口 设置主视频插件->设置. 3.在设置插件的窗口帧速率选择框中 勾上使用帧速率限制 点选帧速率限制为(10 ...
- Scala常用变量生命周期
val words = *** //在words被定义时取值 lazy val words = *** //在words被首次使用时取值 def words = *** //在每一次words被使用时 ...
- Android使得Fragment 切换时不重新实例化
以前实现Fragment的切换都是用replace方法实现 public void startFragmentAdd(Fragment fragment) { FragmentManager frag ...
- 【RPC】综述
RPC定义 RPC(Remote Procedure Call)全称远程过程调用,它指的是通过网络,我们可以实现客户端调用远程服务端的函数并得到返回结果.这个过程就像在本地电脑上运行该函数一样,只不过 ...
- vue2.0--请求数据
vue中用vue-reouse请求来的数据,会被封装一层,如下图res:
- python regularexpress1
//test.py 1 import re 2 3 print (re.search('www', 'www.myweb.com').span()) 4 print (re.search('com', ...
- 阿里云服务器用smtp发送邮件返失败
阿里云使用SMTP发送邮件失败,因为阿里云服务器屏蔽了25端口,所以发送不成功,解决办法改用587发送QQ邮件,且必须使用SSL,否则不成功. 经测试QQ的465,995不能使用. https://b ...