(转)isolation forest进行异常点检测
原文链接:https://www.cnblogs.com/gczr/p/9156971.html
一、简介
孤立森林(Isolation Forest)是另外一种高效的异常检测算法,它和随机森林类似,但每次选择划分属性和划分点(值)时都是随机的,而不是根据信息增益或者基尼指数来选择。在建树过程中,如果一些样本很快就到达了叶子节点(即叶子到根的距离d很短),那么就被认为很有可能是异常点。
具体步骤:
Forest 由t个iTree(Isolation Tree)孤立树 组成,每个iTree是一个二叉树结构,其实现步骤如下:
1. 从训练数据中随机选择Ψ个点样本点作为subsample,放入树的根节点。
2. 随机指定一个维度(attribute),在当前节点数据中随机产生一个切割点p——切割点产生于当前节点数据中指定维度的最大值和最小值之间。
3. 以此切割点生成了一个超平面,然后将当前节点数据空间划分为2个子空间:把指定维度里小于p的数据放在当前节点的左孩子,把大于等于p的数据放在当前节点的右孩子。
4. 在孩子节点中递归步骤2和3,不断构造新的孩子节点,直到 孩子节点中只有一个数据(无法再继续切割) 或 孩子节点已到达限定高度 。
获得t个iTree之后,iForest 训练就结束,然后我们可以用生成的iForest来评估测试数据了。对于一个训练数据x,我们令其遍历每一棵iTree,然后计算x最终落在每个树第几层(x在树的高度)。就可以得出x在森林中的高度平均值,即 the average path length over t iTrees。*值得注意的是,如果x落在一个节点中含多个训练数据,可以使用一个公式来修正x的高度计算,详细公式推导见原论文。
获得每个测试数据的average path length后,我们可以设置一个阈值(边界值),average path length 低于此阈值的测试数据即为异常。也就是说 “iForest identifies anomalies as instances having the shortest average path lengths in a dataset ”(异常在这些树中只有很短的平均高度). *值得注意的是,论文中对树的高度做了归一化,并得出一个0到1的数值,即越短的高度越接近1(异常的可能性越高)。
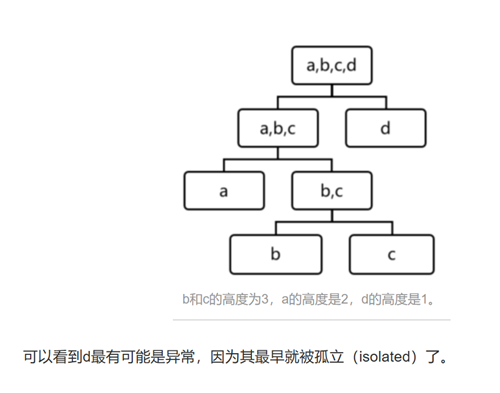
为什么距离d很短就认为是异常点呢?
比如一个维度里有1,2,3,4,5,100,从当前维度的最大值和最小值之间随机选择一个值作为切分点,假如是50,那么大于50的分在右子树,小于50的分在左子树,最终分成了两组,【1,2,3,4,5】和【100】,而在【100】这个样本组里,因为只有一个样本点了,所以不再划分了,高度就是1了,所以距离很短。
二、代码实现


import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
from scipy import stats
rng = np.random.RandomState(42)
n_samples=6 #样本总数
# fit the model
clf = IsolationForest(max_samples=n_samples, random_state=rng, contamination=0.33) #contamination为异常样本比例
clf.fit(df.values)
scores_pred = clf.decision_function(df.values)
print(scores_pred)
print(len(scores_pred))
threshold = stats.scoreatpercentile(scores_pred, 100 * outliers_fraction)
结果:[ 0.11573485 0.12433055 0.13780741 0.12351238 0.06556263 -0.05915569]
clf.predict(df.values)
array([ 1, 1, 1, 1, -1, -1])
三、测试
decision_function(X)
test=[[2,4,50,3,5,69,8]]
clf.decision_function(test)
输出:
array([0.08241789])
clf.predict(df.values)
输出:
array([ 1, 1, 1, 1, -1, -1]) 四、算法应用
Isolation Forest 算法主要有两个参数:一个是二叉树的个数;另一个是训练单棵 iTree 时候抽取样本的数目。实验表明,当设定为 100 棵树,每棵树高度不超过8,抽样样本数为 256 条时候,IF 在大多数情况下就已经可以取得不错的效果。这也体现了算法的简单、高效。
Isolation Forest 是无监督的异常检测算法,在实际应用时,并不需要黑白标签。需要注意的是:(1)如果训练样本中异常样本的比例比较高,违背了先前提到的异常检测的基本假设,可能最终的效果会受影响;(2)异常检测跟具体的应用场景紧密相关,算法检测出的“异常”不一定是我们实际想要的。比如,在识别虚假交易时,异常的交易未必就是虚假的交易。所以,在特征选择时,可能需要过滤不太相关的特征,以免识别出一些不太相关的“异常”。
五、IF特点
1. iForest具有线性时间复杂度。因为是ensemble的方法,所以可以用在含有海量数据的数据集上面。通常树的数量越多,算法越稳定。由于每棵树都是互相独立生成的,因此可以部署在大规模分布式系统上来加速运算。
2. iForest不适用于特别高维的数据。由于每次切数据空间都是随机选取一个维度,建完树后仍然有大量的维度信息没有被使用,导致算法可靠性降低。高维空间还可能存在大量噪音维度或无关维度(irrelevant attributes),影响树的构建。对这类数据,建议使用子空间异常检测(Subspace Anomaly Detection)技术。此外,切割平面默认是axis-parallel的,也可以随机生成各种角度的切割平面,详见“On Detecting Clustered Anomalies Using SCiForest”。
3. iForest仅对Global Anomaly 敏感,即全局稀疏点敏感,不擅长处理局部的相对稀疏点 (Local Anomaly)。目前已有改进方法发表于PAKDD,详见“Improving iForest with Relative Mass”。
4. iForest推动了重心估计(Mass Estimation)理论发展,目前在分类聚类和异常检测中都取得显著效果,发表于各大顶级数据挖掘会议和期刊(如SIGKDD,ICDM,ECML)。
参考链接:https://www.jianshu.com/p/5af3c66e0410
(转)isolation forest进行异常点检测的更多相关文章
- isolation forest进行异常点检测
一.简介 孤立森林(Isolation Forest)是另外一种高效的异常检测算法,它和随机森林类似,但每次选择划分属性和划分点(值)时都是随机的,而不是根据信息增益或者基尼指数来选择.在建树过程中, ...
- [置顶]
Isolation Forest算法原理详解
本文只介绍原论文中的 Isolation Forest 孤立点检测算法的原理,实际的代码实现详解请参照我的另一篇博客:Isolation Forest算法实现详解. 或者读者可以到我的GitHub上去 ...
- Python机器学习笔记 异常点检测算法——Isolation Forest
Isolation,意为孤立/隔离,是名词,其动词为isolate,forest是森林,合起来就是“孤立森林”了,也有叫“独异森林”,好像并没有统一的中文叫法.可能大家都习惯用其英文的名字isolat ...
- [转]Python机器学习笔记 异常点检测算法——Isolation Forest
Isolation,意为孤立/隔离,是名词,其动词为isolate,forest是森林,合起来就是“孤立森林”了,也有叫“独异森林”,好像并没有统一的中文叫法.可能大家都习惯用其英文的名字isolat ...
- 异常检测算法--Isolation Forest
南大周志华老师在2010年提出一个异常检测算法Isolation Forest,在工业界很实用,算法效果好,时间效率高,能有效处理高维数据和海量数据,这里对这个算法进行简要总结. iTree 提到森林 ...
- 异常检测算法:Isolation Forest
iForest (Isolation Forest)是由Liu et al. [1] 提出来的基于二叉树的ensemble异常检测算法,具有效果好.训练快(线性复杂度)等特点. 1. 前言 iFore ...
- 【异常检测】孤立森林(Isolation Forest)算法简介
简介 工作的过程中经常会遇到这样一个问题,在构建模型训练数据时,我们很难保证训练数据的纯净度,数据中往往会参杂很多被错误标记噪声数据,而数据的质量决定了最终模型性能的好坏.如果进行人工二次标记,成本会 ...
- 【异常检测】Isolation forest 的spark 分布式实现
1.算法简介 算法的原始论文 http://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf .python的sklearn中已经实现 ...
- 孤立森林(Isolation Forest)
前言随着机器学习近年来的流行,尤其是深度学习的火热.机器学习算法在很多领域的应用越来越普遍.最近,我在一家广告公司做广告点击反作弊算法研究工作.想到了异常检测算法,并且上网调研发现有一个算法非常火爆, ...
随机推荐
- 《Java基础知识》动态代理(InvocationHandler)详解
1. 什么是动态代理 对象的执行方法,交给代理来负责.比如user.get() 方法,是User对象亲自去执行.而使用代理则是由proxy去执行get方法. 举例:投资商找明星拍广告,投资商是通过经纪 ...
- Linux下shell通用脚本启动jar(微服务)
Linux下shell通用脚本启动jar(微服务) vim app_jar.sh #!/bin/bash #source /etc/profile # Auth:Liucx # Please chan ...
- d3.js 教程 模仿echarts折线图
今天我们来仿echarts折线图,这个图在echarts是折线图堆叠,但是我用d3改造成了普通的折线图,只为了大家学习(其实在简单的写一个布局就可以).废话不多说商行代码. 1 制作 Line 类 c ...
- 【转载】Opening Robot Framework log failed
问题: 两种方法可以解决: 1.临时解决方案 jenkins系统管理—>运行命令行,在文本里输入 System.setProperty("hudson.model.DirectoryB ...
- python同步IO编程——StringIO、BytesIO和stream position
主要介绍python两个内存读写IO:StringIO和BytesIO,使得读写文件具有一致的接口 StringIO 内存中读写str.需要导入StringIO >>> from i ...
- C#线程学习笔记七:Task详细用法
一.Task类简介: Task类是在.NET Framework 4.0中提供的新功能,主要用于异步操作的控制.它比Thread和ThreadPool提供了更为强大的功能,并且更方便使用. Task和 ...
- idea创建Maven版的ssm项目
要使用idea创建一个maven项目,首先电脑安装maven,maven下载地址:http://maven.apache.org/download.cgi 1.打开idea,选择创建一个新项目,选择m ...
- JS---DOM---part4 课程介绍 & part3 复习
part4 课程介绍 事件 1. 绑定事件的区别 2. 移除绑定事件的方式及区别和兼容代码 3. 事件的三个阶段 4. 事件冒泡 5. 为同一个元素绑定多个不同的事件,指向的是同一个事件处理函数 6. ...
- Dynamics 365中使用计算字段自动编号字段实时工作流自动生成分组编码加流水号的自动编号字段值
我是微软Dynamics 365 & Power Platform方面的工程师罗勇,也是2015年7月到2018年6月连续三年Dynamics CRM/Business Solutions方面 ...
- 面试连环炮系列(十二):说说Atomiclnteger的使用场景
说说Atomiclnteger的使用场景 AtomicInteger提供原子操作来进行Integer的使用,适合并发情况下的使用,比如两个线程对同一个整数累加. 为什么Atomiclnteger是线程 ...