Python 爬取高清桌面壁纸
今天写了一个脚本用来爬取ZOL桌面壁纸网站的高清图片;
链接:http://desk.zol.com.cn/1920x1080/
本程序只爬了美女板块的图片,若要下载其他板块,只需修改程序中的”meinv“即可
代码如下:
#coding=utf-8
import urllib
import re
import time
class Spider:
baseUrl='http://desk.zol.com.cn/'
pic_index=0
itemGroupPic=[]
def __init__(self,page_count):
time.sleep(1)
url=self.baseUrl+"meinv/1920x1080/"
for i in range(10, page_count):
time.sleep(5)
html=self.getHtml(url,i)
getbi=self.getPageImageGroup(html)
bizhi_url=self.getbizhiurlList(getbi)
def getHtml(self,url,page_index):
url=url+str(page_index)+".html"
page = urllib.urlopen(url)
html = page.read()
return html
def getPageImageGroup(self,html):
reg=r'<a class="pic" href="/bizhi/.*?.html'
imgre=re.compile(reg)
imagelist=re.findall(imgre,html)
return imagelist
def getbizhiurlList(self,imagelist):
for iurl in imagelist:
reg=r'bizhi/.*?.html'
imgre=re.compile(reg)
itmeimageurl=re.findall(imgre,iurl)
self.itemGroupPic.append(itmeimageurl)
def GetCurrentUrlAndDownload(self,url):
page = urllib.urlopen(url)
html = page.read() #read()出来的文本和网页右键源代码有点出入,这里需要优化
reg=r'<img id="bigImg" src="http://.*.jpg"'
imgre=re.compile(reg)
urllist=re.findall(imgre,html)
for _u in urllist:
reg1=r'http://.*.jpg'
imgre1=re.compile(reg1)
itmeimageurl=re.findall(imgre1,_u)
print u'正在下载'+str(self.pic_index)+u'图片'
#D:\PictureAvi目录要事先创建好
urllib.urlretrieve(itmeimageurl[0],'D:\PictureAvi\%s.jpg' % self.pic_index)
self.pic_index+=1
#获取当前页面的url,next_html
next_reg=r'<a id="pageNext" class="next" href=".*.html"'
next_imgre=re.compile(next_reg)
next_urllist=re.findall(next_imgre,html)
if(len(next_urllist)==0):
return ""
#获取真正的next_html
next_reg_child=r'bizhi.*?.html'
next_imgre_child=re.compile(next_reg_child)
real_url=re.findall(next_imgre_child,next_urllist[0])
return real_url[0]
def MatchUrl(self,imagelist):
for imgurl in imagelist:
url=self.baseUrl+imgurl[0]
next_url=self.GetCurrentUrlAndDownload(url)
#递归获取下一个url
while(next_url != ''):
_itme_next_url=self.baseUrl+next_url
next_url=self.GetCurrentUrlAndDownload(_itme_next_url)
if __name__ == '__main__':
spider = Spider(15)
spider.MatchUrl(spider.itemGroupPic)
print u'结束下载'运行结果如下:
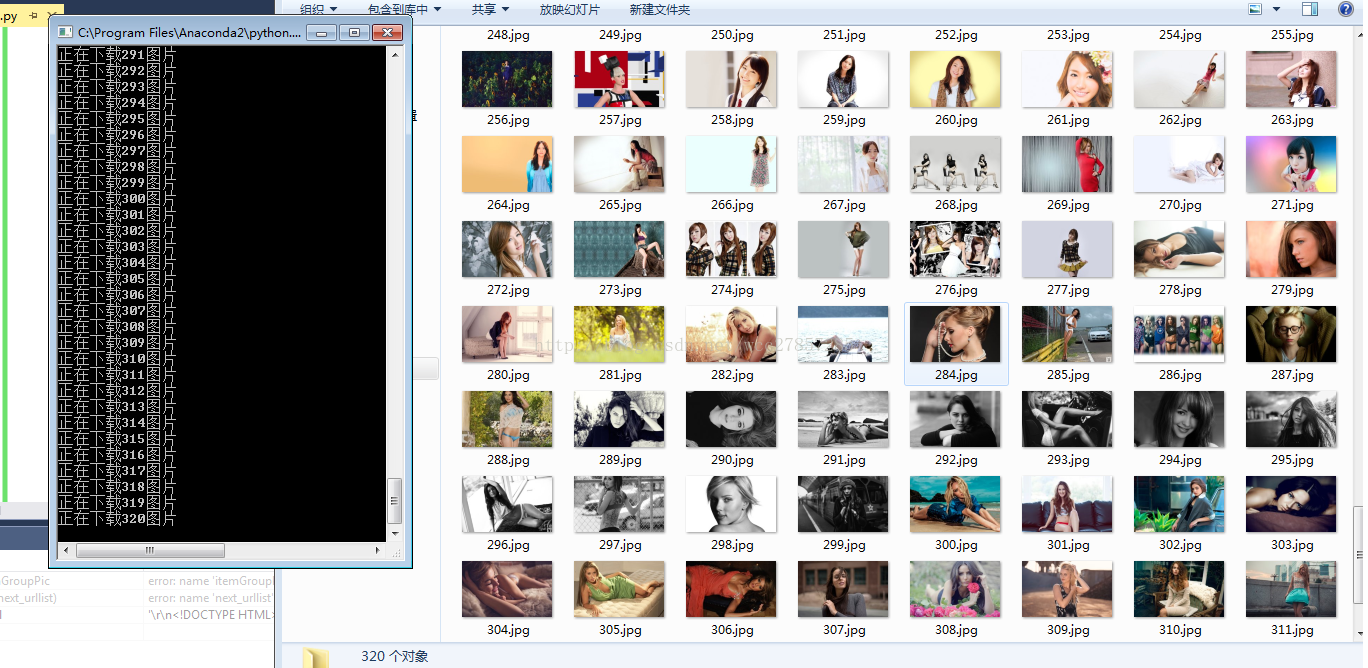
运行环境是py2.7,原理很简单,并没有用到类似scrapy这样的框架,也没用什么动态获取
1.通过urllib获取网页源代码
2.找到规律,通过正则表达式找到url
3.用urllib下载到本地文件
未完待续。。。。。
Python 爬取高清桌面壁纸的更多相关文章
- Python 爬取 "王者荣耀.英雄壁纸" 过程中的矛和盾
1. 前言 学习爬虫,最好的方式就是自己编写爬虫程序. 爬取目标网站上的数据,理论上讲是简单的,无非就是分析页面中的资源链接.然后下载.最后保存. 但是在实施过程却会遇到一些阻碍. 很多网站为了阻止爬 ...
- python3爬取高清壁纸(1)
这次爬取的目标是:美桌网首页 > 桌面壁纸 > 卡通动漫 类别下的壁纸. 我们先随机选取一个专辑来爬(http://www.win4000.com/wallpaper_detail_545 ...
- python3爬取高清壁纸(2)
上次只是爬取一个专辑的图片,这次要爬取一整个页面的所有专辑的图片. 在上次的代码的基础上进行修改就行了,从专辑的索引页面开始,爬取该页面上所有的专辑的链接,再套用上次的代码就行了. 若要爬取多个页面只 ...
- python爬取高匿代理IP(再也不用担心会进小黑屋了)
为什么要用代理IP 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这三类人 ...
- python 爬取王者荣耀高清壁纸
代码地址如下:http://www.demodashi.com/demo/13104.html 一.前言 打过王者的童鞋一般都会喜欢里边设计出来的英雄吧,特别想把王者荣耀的英雄的高清图片当成电脑桌面 ...
- 初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:requests.get 获取网页HTMLetree.HTML 使用lxml解析器解析网页xpath 使用xpath获取网页标签信息.图片地址request.urlretrieve ...
- Python爬取视频指南
摘自:https://www.jianshu.com/p/9ca86becd86d 前言 前两天尔羽说让我爬一下菜鸟窝的教程视频,这次就跟大家来说说Python爬取视频的经验 正文 https://w ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
随机推荐
- HTML - head标签相关
<html> <!-- head标签中主要配置浏览器的配置信息 --> <head> <!-- 网页标题标签, 用来指定网页的标题 --> <ti ...
- 移动端,fixed bottom问题
//不显示 .bar { position:fixed; bottom:0; z-index:99; } //显示 .bar{ position:fixed; bottom:calc(90vh); / ...
- CF1158F Density of subarrays
CF1158F Density of subarrays 首先可以发现,有值的p最大是n/c 对于密度为p,每个数至少出现c次,且其实是每出现c个数,就分成一段,这样贪心就得到了p %ywy n/c ...
- 扩展IEnumerable<T> ForEach()方法
相信很多人,在用Linq时,都会困惑为什么IEnumerabel<T>没有ForEach,虽然 我们一样可以这样写,很快读写 foreach(item in items) { Cons ...
- Error:【SLF4J: Class path contains multiple SLF4J bindings.】
ylbtech-Error:[SLF4J: Class path contains multiple SLF4J bindings.] 1.返回顶部 1. SLF4J: Class path cont ...
- iOS开发之IMP和SEL(方法和类的反射)
1.SEL:类方法的指针,相当于一种编号,区别与IMP! IMP:函数指针,保存了方法的地址! SEL是通过表取对应关系的IMP,进行方法的调用! 2.获取SEL和IMP方法和调用: SEL meth ...
- Docker系列(十六):搭建Openshift环境
目的: 搭建Linux下的Openshift环境. 参考资料: 开源容器云OpenShift 构建基于Kubernetes的企业应用云平台 ,陈耿 ,P253 ,2017.06 .pdf 下载地址:h ...
- 11_数据降维PCA
1.sklearn降维API:sklearn. decomposition 2.PCA是什么:主成分分析 本质:PCA是一种分析.简化数据集的技术. 目的:是数据维数压缩,尽可能降低原数据的维数(复杂 ...
- jsp 页面跳转后修改数据,返回时不更新
项目jsp页面上用隐藏input框接收获取数据,在跳转入另一页面前,js操作修改数据,但返回时发现无效. 需求是点击抽奖后机会减少一次,但是当做跳转操作后返回时,次数有缓存问题 jsp: <in ...
- AlexNet模型
AlexNet模型 <ImageNet Classification with Deep Convolutional Neural Networks>阅读笔记 一直在使用AlexNet,本 ...