初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:
requests.get 获取网页HTML
etree.HTML 使用lxml解析器解析网页
xpath 使用xpath获取网页标签信息、图片地址
request.urlretrieve 下载图片(注:该网站使用urlretrieve下载图片时,返回403错误。原因目前未知!)
改用 with as 下载图片:
with open('文件地址及名字', 'wb') as f:
f.write(res.content)
详细代码如下:
#!/user/bin env python
# author:Simple-Sir
# time:2019/7/17 10:14
# 爬取某网站的壁纸图片
import requests
from lxml import etree
from urllib import request
import urllib
import time # 伪装浏览器
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
}
# 获取壁纸首页网页信息并解析
def getUrlText(url):
respons = requests.get(url,headers=headers) # 获取网页信息
urlText = respons.text
html = etree.HTML(urlText) # 使用lxml解析网页
return html # 提取壁纸链接地址列表
def getWallUrl(url):
hrefUrl = getUrlText(url)
section = hrefUrl.xpath('//section[@class="thumb-listing-page"]')[0] # 获取section标签
hrefList = section.xpath('./ul//@href') # 获取首页图片对应链接地址
return hrefList # 获取当前时间
def getTime():
nowtime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
return nowtime # 解析壁纸下载地址
def downWall(url,page):
'''
:param url: 网页地址
:param page: 下载页数
:return: 下载结束提醒
'''
m = 0
page += 1
for i in range(1,page):
hrefList = getWallUrl(url+str(i))
n = 0
print('\033[36;1m*********** 开始下载第{}页壁纸 ************\033[0m'.format(i))
for href in hrefList:
n += 1
imgUrl = getUrlText(href) # 获取壁纸链接网页信息并解析
imgSrc = imgUrl.xpath('//img[@id="wallpaper"]/@src')[0]
# strUl = etree.tostring(imgSrc, encoding='utf-8').decode('utf-8') # 对获取到ul解码
# print(strUl)
imgType = imgSrc[-4:] # 壁纸格式
print('{}:\033[31;1m开始下载第{}页第{}张壁纸\033[0m'.format(getTime(),i,n))
# request.urlretrieve(imgSrc, './wall/' + str(n) + imgType) #403错误
res = requests.get(imgSrc)
with open('./wall/'+str(i)+'_'+str(n)+imgType, 'wb') as f:
f.write(res.content)
print('{}:\033[31;1m第{}页第{}张壁纸下载完成\033[0m'.format(getTime(),i,n))
m = m + n
return print('{}:\033[36;1m所有壁纸已下载完成,一共{}页{}张。\033[0m'.format(getTime(),i,m)) # url = 'https://wallhaven.cc/search?q=id%3A711&ref=fp&tdsourcetag=s_pcqq_aiomsg&page=' if __name__ == '__main__':
page =int(input('\033[36;1m请输入你想下载的页数:\033[0m'))
print('\033[36;1m程序执行中,请稍等。。。即将下载。\033[0m')
downWall('https://wall***&page=',page)
运行结果:


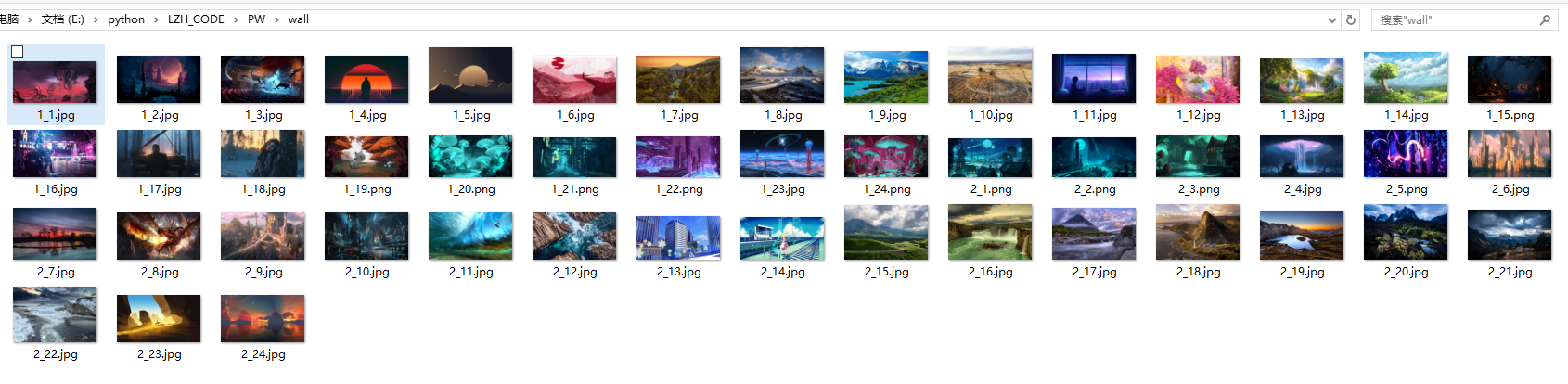
初识python 之 爬虫:爬取某网站的壁纸图片的更多相关文章
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现. 首先还是上代码: # -*- coding:utf-8 -*- import requests import re im ...
- python之简单爬取一个网站信息
requests库是一个简介且简单的处理HTTP请求的第三方库 get()是获取网页最常用的方式,其基本使用方式如下 使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- 利用python实现爬虫爬取某招聘网站,北京地区岗位名称包含某关键字的所有岗位平均月薪
#通过输入的关键字,爬取北京地区某岗位的平均月薪 # -*- coding: utf-8 -*- import re import requests import time import lxml.h ...
- Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
随机推荐
- hash 模式与 history 模式小记
hash 模式 这里的 hash 就是指 url 后的 # 号以及后面的字符.比如说 "www.baidu.com/#hashhash" ,其中 "#hashhash&q ...
- 第43篇-JNI引用的管理(2)
之前我们已经介绍了JNIHandleBlock,但是没有具体介绍JNIHandleBlock中存储的句柄,这一篇我们将详细介绍对这些句柄的操作. JNI句柄分为两种,全局和局部对象引用: (1)大部分 ...
- Redis单点到集群迁移
目录 一.简介 一.简介 1.环境 源 192.168.1.185的6379 目标 192.168.1.91的7001,7002 192.168.1.92的7003,7004 192.168.1.94 ...
- 《转》谈谈基于Kerberos的Windows Network Authentication
http://www.cnblogs.com/artech/archive/2007/07/05/807492.html 基本原理引入Key Distribution: KServer-Client从 ...
- 【CF1591】【数组数组】【逆序对】#759(div2)D. Yet Another Sorting Problem
题目:Problem - D - Codeforces 题解 此题是给数组排序的题,操作是选取任意三个数,然后交换他们,确保他们的位置会发生改变. 可以交换无限次,最终可以形成一个不下降序列就输出&q ...
- 一文掌握 Python 的描述符协议
描述符介绍 描述符本质就是一个新式类,在这个新式类中,至少要实现了__get__(),__set__(),__delete__()中的一个.这也被称为描述符协议. class Myclass(obje ...
- [BUUCTF]PWN——picoctf_2018_rop chain
picoctf_2018_rop chain 附件 步骤: 例行检查,32位,开启了NX保护 试运行一下程序,看到输入太长数据会崩溃 32位ida载入,习惯性的检索程序里的字符串,看见了flag.tx ...
- JAVA微信公众号网页开发——获取公众号关注的所有用户(微信公众号粉丝)
package com.weixin.sendmessage; import org.apache.commons.lang.StringUtils; import org.apache.http.H ...
- JAVA获取html中的所有img链接
public static List<String> getImageSrc(String htmlCode) { List<String> imageSrcList = ne ...
- Miniconda入门教程
Miniconda 教程 介绍 Anaconda指的是一个开源的Python发行版本,其包含了conda.Python等180多个科学包及其依赖项.因为包含了大量的科学包,Anaconda 的下载文件 ...