基于keras中IMDB的文本分类 demo
本次demo主题是使用keras对IMDB影评进行文本分类:
import tensorflow as tf
from tensorflow import keras
import numpy as np print(tf.__version__) imdb = keras.datasets.imdb (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
print("Training entries: {}, labels: {}".format(len(train_data), len(train_labels)))
print(train_data[0])
len(train_data[0]), len(train_data[1]) # A dictionary mapping words to an integer index
word_index = imdb.get_word_index() # The first indices are reserved
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # unknown
word_index["<UNUSED>"] = 3 reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) #把数字序列转化为相应的字符串
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text]) #显示其中一个评价
decode_review(train_data[0]) #pad填充使其长度一样
train_data = keras.preprocessing.sequence.pad_sequences(train_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256) test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256) len(train_data[0]), len(train_data[1])
print(train_data[0]) # input shape is the vocabulary count used for the movie reviews (10,000 words)
vocab_size = 10000
#建立模型
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, 16))
model.add(keras.layers.GlobalAveragePooling1D()) #对序列维度求平均,为每个示例返回固定长度的输出向量
model.add(keras.layers.Dense(16, activation=tf.nn.relu))
model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid)) #显示模型的概况
model.summary() model.compile(optimizer=tf.train.AdamOptimizer(),
loss='binary_crossentropy',
metrics=['accuracy']) #创建验证集
x_val = train_data[:10000]
partial_x_train = train_data[10000:] y_val = train_labels[:10000]
partial_y_train = train_labels[10000:] #训练
history = model.fit(partial_x_train,
partial_y_train,
epochs=40,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1) results = model.evaluate(test_data, test_labels)
print(results) history_dict = history.history
history_dict.keys()
##out:dict_keys(['val_loss', 'val_acc', 'loss', 'acc']) ##显示loss下降的图
import matplotlib.pyplot as plt acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss'] epochs = range(1, len(acc) + 1) # "bo" is for "blue dot"
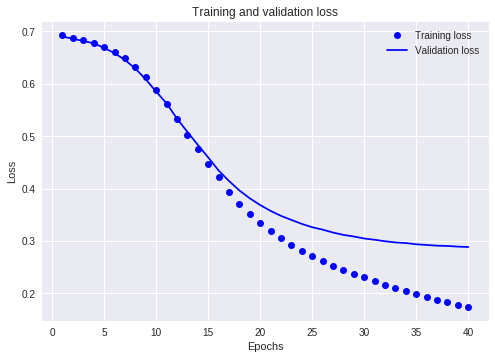
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend() plt.show() ##显示accuracy上升的图
plt.clf() # clear figure
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc'] plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend() plt.show()
layers的概况
_________________________________________________________________
Layer (type) Output Shape Param
# =================================================================
embedding (Embedding) (None, None, 16) 160000
_________________________________________________________________
global_average_pooling1d (Gl (None, 16) 0
_________________________________________________________________
dense (Dense) (None, 16) 272
_________________________________________________________________
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
基于keras中IMDB的文本分类 demo的更多相关文章
- 基于Text-CNN模型的中文文本分类实战 流川枫 发表于AI星球订阅
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 基于Text-CNN模型的中文文本分类实战
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- Chinese-Text-Classification,用卷积神经网络基于 Tensorflow 实现的中文文本分类。
用卷积神经网络基于 Tensorflow 实现的中文文本分类 项目地址: https://github.com/fendouai/Chinese-Text-Classification 欢迎提问:ht ...
- 基于Keras的imdb数据集电影评论情感二分类
IMDB数据集下载速度慢,可以在我的repo库中找到下载,下载后放到~/.keras/datasets/目录下,即可正常运行.)中找到下载,下载后放到~/.keras/datasets/目录下,即可正 ...
- 用keras实现基本的文本分类任务
数据集介绍 包含来自互联网电影数据库的50000条影评文本,对半拆分为训练集和测试集.训练集和测试集之间达成了平衡,意味着它们包含相同数量的正面和负面影评,每个样本都是一个整数数组,表示影评中的字词. ...
- 基于Naive Bayes算法的文本分类
理论 什么是朴素贝叶斯算法? 朴素贝叶斯分类器是一种基于贝叶斯定理的弱分类器,所有朴素贝叶斯分类器都假定样本每个特征与其他特征都不相关.举个例子,如果一种水果其具有红,圆,直径大概3英寸等特征,该水果 ...
- 学界 | Yann LeCun新作,中日韩文本分类到底要用哪种编码?
https://www.wxwenku.com/d/102093756 AI科技评论按:前几天,Yann LeCun与其学生 张翔在arXiv上发表了一篇新作「Which Encoding is th ...
- 基于Huggingface使用BERT进行文本分类的fine-tuning
随着BERT大火之后,很多BERT的变种,这里借用Huggingface工具来简单实现一个文本分类,从而进一步通过Huggingface来认识BERT的工程上的实现方法. 1.load data tr ...
随机推荐
- sshfs实践记录
sshfs是一款利器,可以将远程linux服务器的路径通过ssh协议挂载到本地指定路径.本地的文件一改动,就自动同步到远程服务器中. 本次的实验在centos 6.9中进行. 1.下载.安装所有的依赖 ...
- 表单控件绑定v-model
<!DOCTYPE html> <html lang="zh"> <head> <title></title> < ...
- Ubuntu 安装gnome桌面及vnc远程连接
安装gnome桌面 sudo apt-get install gnome-core 安装vnc sudo apt-get install vnc4server 启动vnc vncserver 设置一下 ...
- tiler--python实现的有趣的自定义马赛克图像拼接工具
最近在github中发现了一个有趣的小工具,tiler github链接https://github.com/nuno-faria/tiler 具体介绍请直接去github,这里只分享一下它的使用方法 ...
- java笔试之求int型正整数在内存中存储时1的个数
输入一个int型的正整数,计算出该int型数据在内存中存储时1的个数. 关键点:n与二进制的1相与:判断最末位是否为1:向右移位. 类似题目是查找输入整数二进制中1的个数. package test; ...
- C++面向对象高级编程(下)-Geekband
11, 组合和继承 一, Composition 复合 has-a的关系 简单来讲, 就是: class A{ classB b1; }; 这里讲到Adapter设计模式: templa ...
- 新增的Java MapReduce API
http://book.51cto.com/art/201106/269647.htm Hadoop的版本0.20.0包含有一个新的 Java MapReduce API,有时也称为"上下文 ...
- Drupal创建Omega 4.x 子主题layout笔记
Adding a new region to your Omega 4.0 subtheme (Drupal) Drupal: Creating a custom layout with Omega ...
- HTML5移动开发中的input输入框类型 (转)
公司的项目开发过程中的,的用户体验忽略了.登录tel就用tel属性.新来的小伙伴提醒的.谢谢他 数字类型number 定义input类型为type="number"时,iOS显示数 ...
- CGLayer和CALayer区别
CGLayer是一种很好的缓存常绘内容的方法.注意,不要与CALayer混淆.CALayer是Core Animation中更加强大.复杂的图层对象,而CGLayer是Core Graphics中优化 ...