基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项。由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎,用来对网络爬虫抓取到的网络资源进行实时的索引和搜索。
搜
索引擎架构在ElasticSearch之上,是一个典型的分布式在线实时交互查询架构,无单点故障,高伸缩、高可用。对大量信息的索引与搜索都可以在近
乎实时的情况下完成,能够快速实时搜索数十亿的文件以及PB级的数据,同时提供了全方面的选项,可以对该引擎的几乎每个方面进行定制。支持RESTful
的API,可以使用JSON通过HTTP调用它的各种功能,包括搜索、分析与监控。此外,还为Java、PHP、Perl、Python以及Ruby等各
种语言提供了原生的客户端类库。
网络爬虫通过将抓取到的数据进行结构化提取之后提交给搜索引擎进行索引,以供查询分析使用。由于搜索引擎的设计目标在于近乎实时的复杂的交互式查询,所以搜索引擎并不保存索引网页的原始内容,因此,需要一个近乎实时的分布式数据库来存储网页的原始内容。
分布式数据库架构在Hbase+Hadoop之上,是一个典型的分布式在线实时随机读写架构。极强的水平伸缩性,支持数十亿的行和数百万的列,能够对网络爬虫提交的数据进行实时写入,并能配合搜索引擎,根据搜索结果实时获取数据。
网
络爬虫、分布式数据库、搜索引擎均运行在普通商业硬件构成的集群上。集群采用分布式架构,能扩展到成千上万台机器,具有容错机制,部分机器节点发生故障不
会造成数据丢失也不会导致计算任务失败。不但高可用,当节点发生故障时能迅速进行故障转移,而且高伸缩,只需要简单地增加机器就能水平线性伸缩、提升数据
存储容量和计算速度。
网络爬虫、分布式数据库、搜索引擎之间的关系:
1、网络爬虫将抓取到的HTML页面解析完成之后,把解析出的数据加入缓冲区队列,由其他两个线程负责处理数据,一个线程负责将数据保存到分布式数据库,一个线程负责将数据提交到搜索引擎进行索引。
2、搜索引擎处理用户的搜索条件,并将搜索结果返回给用户,如果用户查看网页快照,则从分布式数据库中获取网页的原始内容。
整体架构如下图所示:
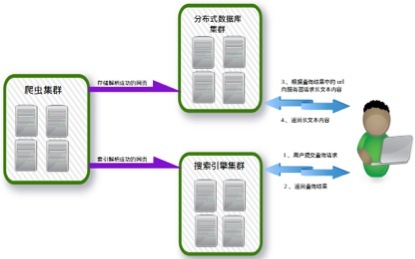
爬虫集群、分布式数据库集群、搜索引擎集群在物理部署上,可以部署到同一个硬件集群上,也可以分开部署,形成1-3个硬件集群。
网络爬虫集群有一个专门的网络爬虫配置管理系统来负责爬虫的配置和管理,如下图所示:
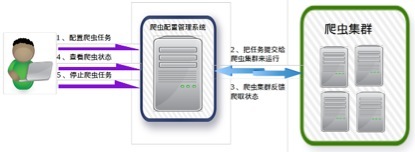
搜
索引擎通过分片(shard)和副本(replica)实现了高性能、高伸缩和高可用。分片技术为大规模并行索引和搜索提供了支持,极大地提高了索引和搜
索的性能,极大地提高了水平扩展能力;副本技术为数据提供冗余,部分机器故障不影响系统的正常使用,保证了系统的持续高可用。
有2个分片和3份副本的索引结构如下所示:
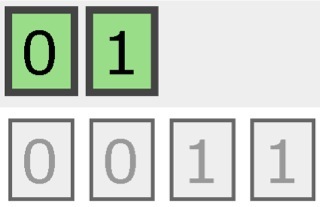
一个完整的索引被切分为0和1两个独立部分,每一部分都有2个副本,即下面的灰色部分。
在
生产环境中,随着数据规模的增大,只需简单地增加硬件机器节点即可,搜索引擎会自动地调整分片数以适应硬件的增加,当部分节点退役的时候,搜索引擎也会自
动调整分片数以适应硬件的减少,同时可以根据硬件的可靠性水平及存储容量的变化随时更改副本数,这一切都是动态的,不需要重启集群,这也是高可用的重要保
障。
基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎的更多相关文章
- 一个大数据方案:基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项.由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎, ...
- 【架构】基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项.由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎, ...
- 网络爬虫与搜索引擎优化(SEO)
爬虫及爬行方式 爬虫有很多名字,比如web机器人.spider等,它是一种可以在无需人类干预的情况下自动进行一系列web事务处理的软件程序.web爬虫是一种机器人,它们会递归地对各种信息性的web站点 ...
- 网络爬虫与搜索引擎优化(SEO)
一.网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引. ...
- 基于Heritrix的特定主题的网络爬虫配置与实现
建议在了解了一定网络爬虫的基本原理和Heritrix的架构知识后进行配置和扩展.相关博文:http://www.cnblogs.com/hustfly/p/3441747.html 摘要 随着网络时代 ...
- hadoop中实现java网络爬虫
这一篇网络爬虫的实现就要联系上大数据了.在前两篇java实现网络爬虫和heritrix实现网络爬虫的基础上,这一次是要完整的做一次数据的收集.数据上传.数据分析.数据结果读取.数据可视化. 需要用到 ...
- [原创]一款基于Reactor线程模型的java网络爬虫框架
AJSprider 概述 AJSprider是笔者基于Reactor线程模式+Jsoup+HttpClient封装的一款轻量级java多线程网络爬虫框架,简单上手,小白也能玩爬虫, 使用本框架,只需要 ...
- 【Nutch2.3基础教程】集成Nutch/Hadoop/Hbase/Solr构建搜索引擎:安装及运行【集群环境】
1.下载相关软件,并解压 版本号如下: (1)apache-nutch-2.3 (2) hadoop-1.2.1 (3)hbase-0.92.1 (4)solr-4.9.0 并解压至/opt/jedi ...
- Android网络爬虫程序(基于Jsoup)
摘要:基于 Jsoup 实现一个 Android 的网络爬虫程序,抓取网页的内容并显示出来.写这个程序的主要目的是抓取海投网的宣讲会信息(公司.时间.地点)并在移动端显示,这样就可以随时随地的浏览在学 ...
随机推荐
- 为什么printf()用%f输出double型,而scanf却用%lf呢?
之前没有注意过这个问题, 转自: http://book.51cto.com/art/200901/106880.htm 问:有人告诉我不能在printf中使用%lf.为什么printf()用%f输 ...
- 【JZOJ4840】【NOIP2016提高A组集训第4场11.1】小W砍大树
题目描述 数据范围 解法 模拟. 代码 #include<stdio.h> #include<algorithm> #include<string.h> #incl ...
- Chef 安装
http://www.tuicool.com/articles/RnAVn2 三个角色: chef server, chef workstation, chef nodes(chef clients) ...
- js错误处理Try-catch和throw
1.try-catch语句 Try{ //可能会导致错误的代码 }catch(error){ //在错误发生时怎么处理 } 例如: try{ window.someNonexistentFunct ...
- GIAC2019 演讲精选 | 面向未来的黑科技——UI2CODE闲鱼基于图片生成跨端代码
一直以来, 如何从‘视觉稿’精确的还原出 对应的UI侧代码 一直是端侧开发同学工作里消耗比较大的部分,一方面这部分的工作 比较确定缺少技术深度,另一方面视觉设计师也需要投入大量的走查时间,有大量无谓的 ...
- docker查看运行容器详细信息
使用docker ps命令可以查看所有正在运行中的容器列表, 使用docker inspect命令我们可以查看更详细的关于某一个容器的信息. $ docker inspect 容器id/image
- & 和 | 和 ~
O(∩_∩)O~~浅理解,不足之处请多指正,谢谢. 1) & & :二目运算符,把运算符两侧的数换成 二进制 再依次求与. 例如:a = 2,b = 3; c = a & b; ...
- oralce函数 count(*|[distinct|all]x)
[功能]统计数据表选中行x列的合计值. [参数] *表示对满足条件的所有行统计,不管其是否重复或有空值(NULL) all表示对所有的值统计,默认为all distinct只对不同的值统计, 如果有参 ...
- Alternating Direction Method of Multipliers -- ADMM
前言: Alternating Direction Method of Multipliers(ADMM)算法并不是一个很新的算法,他只是整合许多不少经典优化思路,然后结合现代统计学习所遇到的问题,提 ...
- HDU 4417 Super Mario 主席树查询区间小于某个值的个数
#include<iostream> #include<string.h> #include<algorithm> #include<stdio.h> ...