一个大数据方案:基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项。由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎,用来对网络爬虫抓取到的网络资源进行实时的索引和搜索。
搜 索引擎架构在ElasticSearch之上,是一个典型的分布式在线实时交互查询架构,无单点故障,高伸缩、高可用。对大量信息的索引与搜索都可以在近 乎实时的情况下完成,能够快速实时搜索数十亿的文件以及PB级的数据,同时提供了全方面的选项,可以对该引擎的几乎每个方面进行定制。支持RESTful 的API,可以使用JSON通过HTTP调用它的各种功能,包括搜索、分析与监控。此外,还为Java、PHP、Perl、Python以及Ruby等各
种语言提供了原生的客户端类库。
网络爬虫通过将抓取到的数据进行结构化提取之后提交给搜索引擎进行索引,以供查询分析使用。由于搜索引擎的设计目标在于近乎实时的复杂的交互式查询,所以搜索引擎并不保存索引网页的原始内容,因此,需要一个近乎实时的分布式数据库来存储网页的原始内容。
分布式数据库架构在Hbase+Hadoop之上,是一个典型的分布式在线实时随机读写架构。极强的水平伸缩性,支持数十亿的行和数百万的列,能够对网络爬虫提交的数据进行实时写入,并能配合搜索引擎,根据搜索结果实时获取数据。
网 络爬虫、分布式数据库、搜索引擎均运行在普通商业硬件构成的集群上。集群采用分布式架构,能扩展到成千上万台机器,具有容错机制,部分机器节点发生故障不 会造成数据丢失也不会导致计算任务失败。不但高可用,当节点发生故障时能迅速进行故障转移,而且高伸缩,只需要简单地增加机器就能水平线性伸缩、提升数据 存储容量和计算速度。
网络爬虫、分布式数据库、搜索引擎之间的关系:
1、网络爬虫将抓取到的HTML页面解析完成之后,把解析出的数据加入缓冲区队列,由其他两个线程负责处理数据,一个线程负责将数据保存到分布式数据库,一个线程负责将数据提交到搜索引擎进行索引。
2、搜索引擎处理用户的搜索条件,并将搜索结果返回给用户,如果用户查看网页快照,则从分布式数据库中获取网页的原始内容。
整体架构如下图所示:
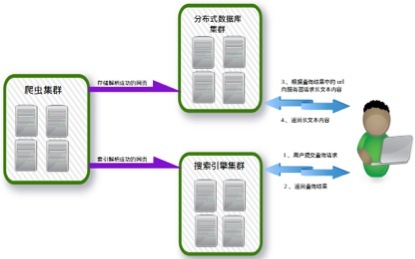
爬虫集群、分布式数据库集群、搜索引擎集群在物理部署上,可以部署到同一个硬件集群上,也可以分开部署,形成1-3个硬件集群。
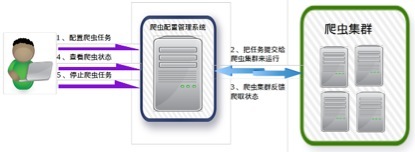
网络爬虫集群有一个专门的网络爬虫配置管理系统来负责爬虫的配置和管理,如下图所示:
搜 索引擎通过分片(shard)和副本(replica)实现了高性能、高伸缩和高可用。分片技术为大规模并行索引和搜索提供了支持,极大地提高了索引和搜 索的性能,极大地提高了水平扩展能力;副本技术为数据提供冗余,部分机器故障不影响系统的正常使用,保证了系统的持续高可用。
有2个分片和3份副本的索引结构如下所示:
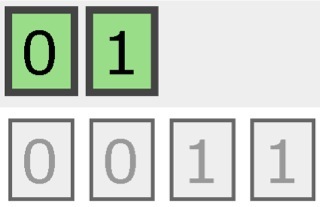
一个完整的索引被切分为0和1两个独立部分,每一部分都有2个副本,即下面的灰色部分。
在 生产环境中,随着数据规模的增大,只需简单地增加硬件机器节点即可,搜索引擎会自动地调整分片数以适应硬件的增加,当部分节点退役的时候,搜索引擎也会自 动调整分片数以适应硬件的减少,同时可以根据硬件的可靠性水平及存储容量的变化随时更改副本数,这一切都是动态的,不需要重启集群,这也是高可用的重要保 障。
一个大数据方案:基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎的更多相关文章
- 基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎 网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并 ...
- 【架构】基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项.由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎, ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 如何基于Go搭建一个大数据平台
如何基于Go搭建一个大数据平台 - Go中国 - CSDN博客 https://blog.csdn.net/ra681t58cjxsgckj31/article/details/78333775 01 ...
- 阿里巴巴飞天大数据架构体系与Hadoop生态系统
很多人问阿里的飞天大数据平台.云梯2.MaxCompute.实时计算到底是什么,和自建Hadoop平台有什么区别. 先说Hadoop 什么是Hadoop? Hadoop是一个开源.高可靠.可扩展的分布 ...
- 大数据的前世今生【Hadoop、Spark】
一.大数据简介 大数据是一个很热门的话题,但它是什么时候开始兴起的呢? 大数据[big data]这个词最早在UNIX用户协会的会议上被使用,来自SGI公司的科学家在其文章“大数据与下一代基础架构 ...
- 大数据学习笔记之Hadoop(一):Hadoop入门
文章目录 大数据概论 一.大数据概念 二.大数据的特点 三.大数据能干啥? 四.大数据发展前景 五.企业数据部的业务流程分析 六.企业数据部的一般组织结构 Hadoop(入门) 一 从Hadoop框架 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 大数据应用之Windows平台Hbase客户端Eclipse开发环境搭建
大数据应用之Windows平台Hbase客户端Eclipse开发环境搭建 大数据应用之Windows平台Hbase客户端Eclipse环境搭建-Java版 作者:张子良 版权所有,转载请注明出处 引子 ...
随机推荐
- Git/GitHub SSH配置
生成 SSH 公钥 如前所述,许多 Git 服务器都使用 SSH 公钥进行认证. 为了向 Git 服务器提供 SSH 公钥,如果某系统用户尚未拥有密钥,必须事先为其生成一份. 这个过程在所有操作系统上 ...
- centos 7.X & centos6.X 防火墙基本命令
Centos 7 firewall 命令:查看已经开放的端口: firewall-cmd --list-ports 开启端口 firewall-cmd --zone=public --add-port ...
- python笔记九(迭代)
一.迭代 通过for循环来遍历一个列表,我们称这种遍历的方式为迭代.只要是可迭代对象都可以进行迭代操作. 以下代码可以用来判断一个对象是否是可迭代的. 一类是集合数据类型,如list.tuple.di ...
- Docker内核能力机制
能力机制(Capability)是 Linux 内核一个强大的特性,可以提供细粒度的权限访问控制. Linux 内核自 2.2 版本起就支持能力机制,它将权限划分为更加细粒度的操作能力,既可以作用在进 ...
- Oracle数据库常用命令记录
1.Sql建表 CREATE TABLE AAABBBCCCDDD( ID ) primary key, AAAAAAAA ) not NULL, BBBBBBBB ), CCCCCCCC ), DD ...
- Linux系统网络性能实例分析
由于TCP/IP是使用最普遍的Internet协议,下面只集中讨论TCP/IP 栈和以太网(Ethernet).术语 LinuxTCP/IP栈和 Linux网络栈可互换使用,因为 TCP/IP栈是 L ...
- Swift基础之CoreData的使用
以前使用过OC版本的CoreData应该很好理解Swift方式,所以这里简单的展示一下,增删改查的方法使用,同时给大家说一下创建步骤,方便大家的使用,转载请注明出处,谢谢~ 步骤一:创建一个Swift ...
- 安卓高级4 第三方库SlidingMenu的使用
源码位于github上(本人fork地址):点击进入地址 效果图: 使用方法:下载源码后 解压其中的文件夹library 到任意地方 修改library中gragle 其方法参考另一个博客(建议先修改 ...
- 【SSH系列】-- Hibernate持久化对象的三种状态
在上一篇博文中,小编主要简单的介绍了[SSH系列]--hibernate基本原理&&入门demo,今天小编来继续介绍hibernate的相关知识, 大家知道,Java对象的生命周期,是 ...
- [python]mysql数据缓存到redis中 取出时候编码问题
描述: 一个web服务,原先的业务逻辑是把mysql查询的结果缓存在redis中一个小时,加快请求的响应. 现在有个问题就是根据请求的指定的编码返回对应编码的response. 首先是要修改响应的bo ...