基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项。由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎,用来对网络爬虫抓取到的网络资源进行实时的索引和搜索。
搜
索引擎架构在ElasticSearch之上,是一个典型的分布式在线实时交互查询架构,无单点故障,高伸缩、高可用。对大量信息的索引与搜索都可以在近
乎实时的情况下完成,能够快速实时搜索数十亿的文件以及PB级的数据,同时提供了全方面的选项,可以对该引擎的几乎每个方面进行定制。支持RESTful
的API,可以使用JSON通过HTTP调用它的各种功能,包括搜索、分析与监控。此外,还为Java、PHP、Perl、Python以及Ruby等各
种语言提供了原生的客户端类库。
网络爬虫通过将抓取到的数据进行结构化提取之后提交给搜索引擎进行索引,以供查询分析使用。由于搜索引擎的设计目标在于近乎实时的复杂的交互式查询,所以搜索引擎并不保存索引网页的原始内容,因此,需要一个近乎实时的分布式数据库来存储网页的原始内容。
分布式数据库架构在Hbase+Hadoop之上,是一个典型的分布式在线实时随机读写架构。极强的水平伸缩性,支持数十亿的行和数百万的列,能够对网络爬虫提交的数据进行实时写入,并能配合搜索引擎,根据搜索结果实时获取数据。
网
络爬虫、分布式数据库、搜索引擎均运行在普通商业硬件构成的集群上。集群采用分布式架构,能扩展到成千上万台机器,具有容错机制,部分机器节点发生故障不
会造成数据丢失也不会导致计算任务失败。不但高可用,当节点发生故障时能迅速进行故障转移,而且高伸缩,只需要简单地增加机器就能水平线性伸缩、提升数据
存储容量和计算速度。
网络爬虫、分布式数据库、搜索引擎之间的关系:
1、网络爬虫将抓取到的HTML页面解析完成之后,把解析出的数据加入缓冲区队列,由其他两个线程负责处理数据,一个线程负责将数据保存到分布式数据库,一个线程负责将数据提交到搜索引擎进行索引。
2、搜索引擎处理用户的搜索条件,并将搜索结果返回给用户,如果用户查看网页快照,则从分布式数据库中获取网页的原始内容。
整体架构如下图所示:
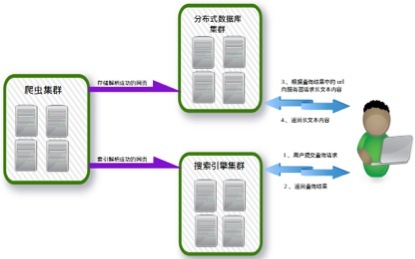
爬虫集群、分布式数据库集群、搜索引擎集群在物理部署上,可以部署到同一个硬件集群上,也可以分开部署,形成1-3个硬件集群。
网络爬虫集群有一个专门的网络爬虫配置管理系统来负责爬虫的配置和管理,如下图所示:
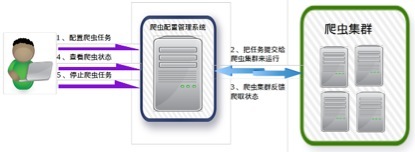
搜
索引擎通过分片(shard)和副本(replica)实现了高性能、高伸缩和高可用。分片技术为大规模并行索引和搜索提供了支持,极大地提高了索引和搜
索的性能,极大地提高了水平扩展能力;副本技术为数据提供冗余,部分机器故障不影响系统的正常使用,保证了系统的持续高可用。
有2个分片和3份副本的索引结构如下所示:
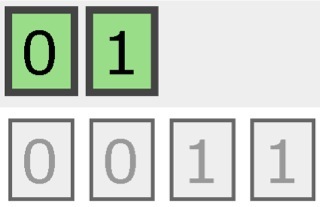
一个完整的索引被切分为0和1两个独立部分,每一部分都有2个副本,即下面的灰色部分。
在
生产环境中,随着数据规模的增大,只需简单地增加硬件机器节点即可,搜索引擎会自动地调整分片数以适应硬件的增加,当部分节点退役的时候,搜索引擎也会自
动调整分片数以适应硬件的减少,同时可以根据硬件的可靠性水平及存储容量的变化随时更改副本数,这一切都是动态的,不需要重启集群,这也是高可用的重要保
障。
基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎的更多相关文章
- 一个大数据方案:基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项.由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎, ...
- 【架构】基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项.由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎, ...
- 网络爬虫与搜索引擎优化(SEO)
爬虫及爬行方式 爬虫有很多名字,比如web机器人.spider等,它是一种可以在无需人类干预的情况下自动进行一系列web事务处理的软件程序.web爬虫是一种机器人,它们会递归地对各种信息性的web站点 ...
- 网络爬虫与搜索引擎优化(SEO)
一.网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引. ...
- 基于Heritrix的特定主题的网络爬虫配置与实现
建议在了解了一定网络爬虫的基本原理和Heritrix的架构知识后进行配置和扩展.相关博文:http://www.cnblogs.com/hustfly/p/3441747.html 摘要 随着网络时代 ...
- hadoop中实现java网络爬虫
这一篇网络爬虫的实现就要联系上大数据了.在前两篇java实现网络爬虫和heritrix实现网络爬虫的基础上,这一次是要完整的做一次数据的收集.数据上传.数据分析.数据结果读取.数据可视化. 需要用到 ...
- [原创]一款基于Reactor线程模型的java网络爬虫框架
AJSprider 概述 AJSprider是笔者基于Reactor线程模式+Jsoup+HttpClient封装的一款轻量级java多线程网络爬虫框架,简单上手,小白也能玩爬虫, 使用本框架,只需要 ...
- 【Nutch2.3基础教程】集成Nutch/Hadoop/Hbase/Solr构建搜索引擎:安装及运行【集群环境】
1.下载相关软件,并解压 版本号如下: (1)apache-nutch-2.3 (2) hadoop-1.2.1 (3)hbase-0.92.1 (4)solr-4.9.0 并解压至/opt/jedi ...
- Android网络爬虫程序(基于Jsoup)
摘要:基于 Jsoup 实现一个 Android 的网络爬虫程序,抓取网页的内容并显示出来.写这个程序的主要目的是抓取海投网的宣讲会信息(公司.时间.地点)并在移动端显示,这样就可以随时随地的浏览在学 ...
随机推荐
- 【Django入坑之路】Form组件
1:From组件的简单使用 1创建From: #导入模块 from django import forms from django.forms import fields, widgets # 导入自 ...
- LRM-00109: could not open parameter file '/u01/app/oracle/product/12.1.0/db_1/dbs/initepps.ora'
安装好oracle后,起动时报如下错误: [oracle@Oracle-A ~]$ export ORACLE_SID=ORCL [oracle@Oracle-A ~]$ sqlplus / as s ...
- 不撞南墙不回头———深度优先搜索(DFS)Oil Deposits
Oil Deposits Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Tota ...
- laravel 5.5 登录验证码 captcha 引入
https://blog.csdn.net/u013372487/article/details/79461730 前提: 开启Laravel 的用户认证功能 1.安装 Captcha 安装 Capt ...
- uva 10566 Crossed Ladders (二分)
http://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&p ...
- Python基础之(三)----PyGame安装步骤
http://blog.csdn.net/qq_33166080/article/details/68928563 如果你已经有一定的编程经验,那么学习一门新语言最快的方式就是拿着一个比较中型的项目, ...
- axios用headers传参,设置请求头token
新建一个配置文件http.js // 导入axios import axios from 'axios'; // 全局配置默认路由 axios.defaults.baseURL = 'http://1 ...
- springmvc使用javabean作为请求参数
1 首先写两个javabean对象 person 和 address 代码如下.两个类之间的关系如代码中 package cn.bean.demo.bo; public class Person ...
- 在对文件进行随机读写,RandomAccessFile类,如何提高其效率
花1K内存实现高效I/O的RandomAccessFile类 JAVA的文件随机存取类(RandomAccessFile)的I/O效率较低.通过分析其中原因,提出解决方案.逐步展示如何创建具备缓存读写 ...
- supersockets多个 listener
你可以增加一个子节点 "listeners" 用于添加多对监听 ip/port: <superSocket> <servers> <server na ...