jmeter数据分析,压测实现
 1.开始之前,先介绍下压测的一些基本插件:线程组常用分为三类:user thread , step thread ,ultimate thread :
1.开始之前,先介绍下压测的一些基本插件:线程组常用分为三类:user thread , step thread ,ultimate thread :
user thread :最通用的最原始的线程实现;分为循环实现线程,可以实现线程delay延时;
step thread :能够实现一些较复杂场景,比如常见爬坡类类型,以及持续在线场景
This Group will start 10 threads:这次的测试总共会起10个线程。 First , wait for 0 seconds:等待0s后开始起线程,也就是不等待直接起线程。 Then start 0 threads;从0个线程开始持续增加。 Next,add 2 threads every 3 seconds:每增加2个线程后会运行3s,再起余下的2个线程,再运行3s,以此类推。 Using ramp-up 6seconds:前面每起2个线程的时候花6s,与上面结合起来即6s内起2个线程,运行3s,然后再再6s内再起2个线程,再运行3s,以此类推。 Then hold load for 30 seconds. :全部的线程起来后,运行30s 后开始停止。 Finally , stop 2 threads every 1 seconds:最后停止线程,2个线程停一次,等1s再
ultimate thread:
参数含义解释: Start Threads Count:当前行启动的线程总数 Initial Delay/sec:延时启动当前行的线程,单位:秒 Startup Time/sec:启动当前行所有线程达峰值所需时间,单位:秒 Hold Load For/sec:当前行线程达到峰值后的稳定加载时间,单位:秒 Shutdown Time:停止当前行所有线程所需时间,单位:秒
2。关于同步定时器syn timer:

它有两个参数:1.模拟用户组数量,我这里把他称为集合释放阈值意思,就是当你想实现用户达到一定数量时一起同时请求目的,他会根据你的 timeout时间设置决定什么时间发送已经集结的thread请求requests,2. time out in millionseconds 简称ttl ,意思是超时时间
你需要注意的有以下:1.模拟用户数量的值不能够大于线程组user thread 的线程数所填写的值,其次对于syn timer 的超时时间为0表示定时器会等到模拟用户数达到设置数量才会一次发出所有请求,非0时,如过设置时间内还未达到集合要求数量,将不会在等待后面还未到达请求,直接发送所有已集结threads 的requests;
2.如果你的模拟用户组数量也就是集结数量默认为0,它会按照user thread 线程数进行等待,对于超时时间研究过一个小技巧就是time>模拟用户组数量*1000/user thread number/loop count 可以避免因为设置 timeout =0 时,出现一直等待模拟用户组数量卡死现象情况
3.关于插件: tps trt, activate thread ,监控汇总以及图形插件下载地址:Extras.jar,下载完成后丢进jmeter 的lib/ext下面重启jmeter插件就会生效
https://github.com/chen1932390299/JavaProject/raw/JmeterJavaBranch/lib_jtlChange/ext/JMeterPlugins-Extras.jar
当然如果你有其他的插件也想下载可以使用下面这个old jmeter plugin,不知道什么时间放弃维护,应该是国内源download速度比官网快很多:
https://jmeter-plugins.org/downloads/old/
4.数据分析:对于压力测试很多人都不考虑持续压力测试的这种情况,以较短时间的一段数据来衡量整个服务性能数据是很不科学的:
首先什么是虚拟用户数,什么是并发量,甚至有些pm在表达自己或者用户需求时都没搞清并发和用户数的具体区别,jmeter用户模拟是通过线程实现,一个线程代表着一个虚拟用户;很多新手一上来就是线程数等于并发数堆上去,就是干,更有甚者直接拿着一台windows模拟出5000,甚至更高的数据并发,被很多经验丰富的技术人员所diss,实际上根本不能达到效果,而且一旦出现ko你分不清ko的请求哪些是服务器无法处理导致的error还是因为本地内存资源耗尽导致的request的error;
或许有人会讲了并发本就没有真正意义的并发的确我们并发不可能一点点时间都不差,我们终不过是实现一个更接近并发场景的场景构造就和我们极限求导一个思想,无限逼近那个理想效果;广义并发我们称为同一时刻发生的所有用户行为,可以做不同的事,也可以做相同的事;狭义来讲,我们认为并发是同一时间做相同的事;那么有没有想过为什么不能上面那些新手那样直接怼就是干呢,首先线程启动是又先后顺序的,其次压力机器的资源是有限的当达到上限会对线程排队;再者,单台机器内存有限不可能无限制启动5000甚至上万线程那样本地早就oom了,想要实现更高的并发需要通过分布式压测来解决资源问题分摊请求压力一台master执行机器可以对应多台slave 负载机器实现高并发的请求
计算公式:
concurrent = requests_totals*avgtime_rep/time_totals_continue
request_totals约等于 tps*time_totals_continue
也有一些网友采用tps*avgtime/1000方式这样有一个风险就是如果你取到的波动的一个峰值或取到的刚好是波谷,这就意味着你的所有请求都的为你的这个tps值买单这是有很大风险的
整个推导过程以一段时间的数据请求总时间/持续压测时间,来衡量这段时间的服务器实际并发量,通过计算来得到服务器在不同用户并发下实际能达到的并发处理值也就是每秒处理的实际请求数作为实际并发值,因此我们也可以通过反向计推算出我们想达到某一并发所需要的虚拟用户数,也就是userthreads数量;上面的公式来计算下面这组数据
首先明显测试出的总的requests数量在10 user thread 持续60的时间内总的数量为13490那么,我们用上面的计算公式来验证我们的计算是否与测试出来的一致:
total_requests=tps*time_totals_continue=228.2*60=13692与jmeter测试出来的13490的请求量只有1.5%的误差,由此可见我们的计算是很接近实际的测试值的

但是这个只是一个大概值,其次随着并发数量增加,本地资源耗费以及服务负载增加 user threads 与 并发concurrent 转换率会由1:1 随着thread数量增加,转换率会越来愈低经验来讲一般到后面只有1:0.3的转换率这也是很多压测经验者为什么根据user thread 的30%作为并发数的原因,而在linux会由于io,内存,cpu综合性能优于windows转换率能到达1:1.随着并发增加也能依旧保持1:0.8的优秀转换率,这些都是我和同事一起在工作过程中经过压力统计观测发现的一些有趣的事情:
以下是Extras的监听器部分插件:
activate thread 活跃线程数监控:

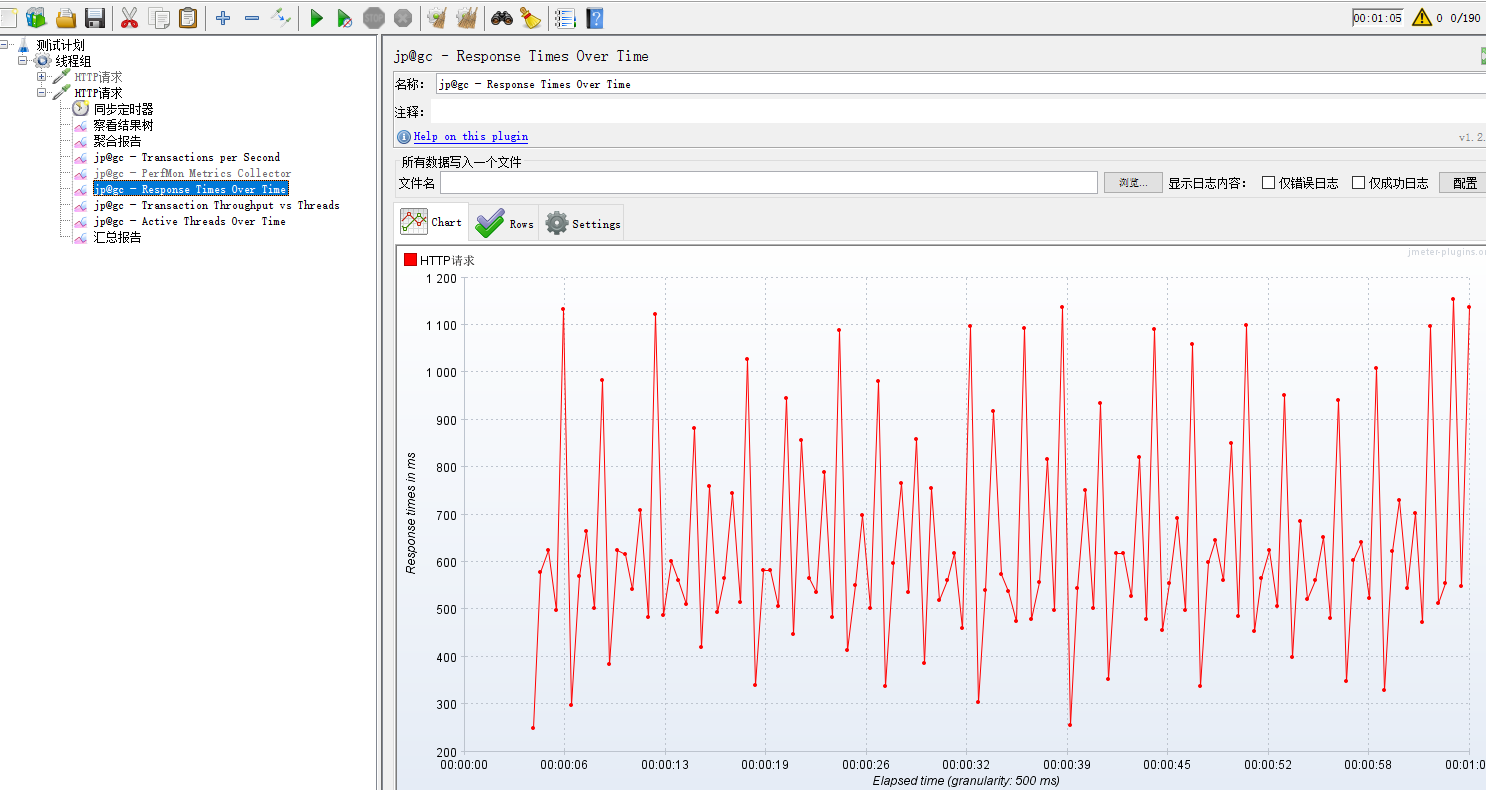
transcations thrououtput/threads监控 :
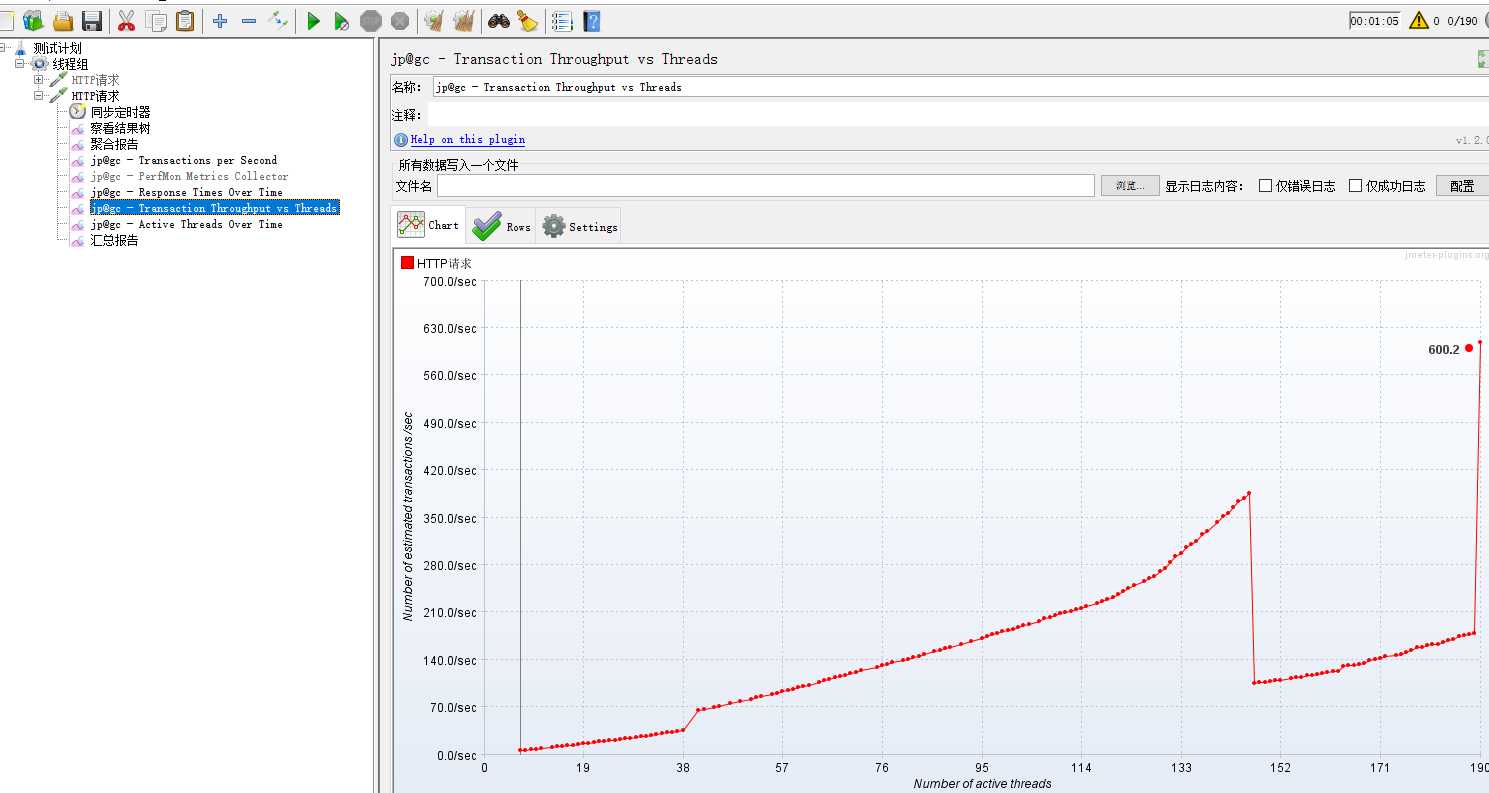
rtt 响应时间监控:
transcations persecond 秒处理事务数 监控数据:

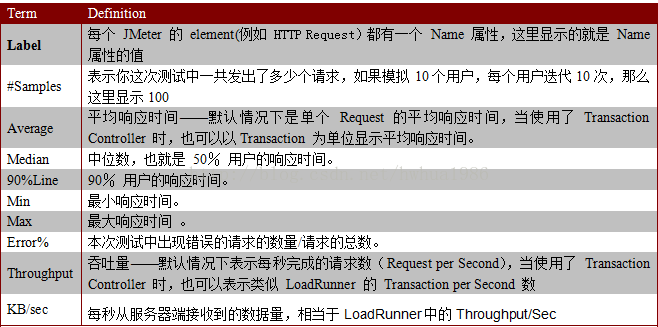
聚合报告:

插件功能解释:

在文章的最后我想推荐一篇国外期刊给大家:让你学习如何通过十二种方式去分析性能数据,如何成为一名优秀的专业的技术人员:
https://octoperf.com/blog/2017/10/19/how-to-analyze-jmeter-results/

jmeter数据分析,压测实现的更多相关文章
- JMeter分布式压测实战(2020年清明假期学习笔记)
一.常用压力测试工具对比 简介:目前用的常用测试工具对比 1.loadrunner 性能稳定,压测结果及颗粒度大,可以自定义脚本进行压测,但是太过于重大,功能比较繁多. 2.Apache ab(单接口 ...
- lesson5:利用jmeter来压测消息队列(activemq)
本文讲述了利用jmeter来压测消息队列,其中消息队列采用apache的activemq,jmeter本身是支持符合jms标准消息队列的压测,由于jmeter的官方sampler配置比较复杂,本文直接 ...
- lesson4:利用jmeter来压测数据库
本文讲述了如何利用jmeter来压测数据库,事例中选取了mysql作为测试数据库,其它的数据库也是一样,只需要更换驱动程序即可. 准备工作:a.mysql数据库安装,请自行百度:b.jdbc驱动包,请 ...
- jmeter 分布式压测(windows)
单台压测机通常会遇到客户端瓶颈,受制于客户机的性能.可能由于网络带宽,CPU,内存的限制不能给到服务器足够的压力,这个时候你就需要用到分布式方案来解决客户机的瓶颈,压测的结果也会更加接近于真实情况. ...
- jmeter简单压测设置
参数化 随机参数 时间参数 顺序自增函数 文件读取 直接引用 响应断言 用来查看sessionid 关联 关联引用 jmeter操作数据库 安装连接程序包 ip 端口号 哪个数据库 可以执行多条s ...
- Jmeter阶梯式压测
https://www.cnblogs.com/Zfc-Cjk/p/11639219.html 什么是阶梯式压测? 阶梯式压测,就是对系统的压力呈现阶梯性增加的过程,每个阶段压力值都要增加一个数量值, ...
- jmeter接口压测的反思
jmeter接口压测的反思 1.keepalive的坑:连接数满了,导致发起的请求失败. 2.token关联?是数据库取做参数化,还是随机数生成(需要改代码) 3.签名问题如何处理? 4.压测负载机端 ...
- 压力测试(八)-多节点JMeter分布式压测实战
1.Jmeter4.0分布式压测准备工作 简介:讲解Linux服务器上jmeter进行分布式压测的相关准备工作 1.压测注意事项 the firewalls on the systems are tu ...
- Jmeter让压测随时做起来(转载)
为什么要压测 这个问题问的其实挺没有必要的,做开发的同学应该都很清楚,压测的必要性,压力测试主要目的就是让我们在上线前能够了解到我们系统的承载能力,和当前.未来系统压力的提升情况,能够评估出当前系统的 ...
- jmeter静默压测+可视化
静默压测自动化脚本auto_stress_test.sh #!/usr/bin/env bash export jmx_template="test2" export suffix ...
随机推荐
- 小白学 Python 爬虫(24):2019 豆瓣电影排行
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Electron – 项目报错整理(打包~1): WARNING: Make sure that .NET Framework 4.5 or later and Powershell 3 or later are installed, otherwise extracting the Electron zip file will hang.
WARNING: Make sure that .NET Framework 4.5 or later and Powershell 3 or later are installed, otherwi ...
- django初步了解(一)
安装django pip3 install django==版本号 创建一个djangp项目 django-admin startproject 项目名 目录介绍: 运行django项目: pytho ...
- Myeclipse的一些快捷键整理(转)
1. [ALT+/] 此快捷键为用户编辑的好帮手,能为用户提供内容的辅助,不要为记不全方法和属性名称犯愁,当记不全类.方法和属性的名字时,多体验一下[ALT+/]快捷键带来的好处吧. 2. ...
- 题解【洛谷P1407】 [国家集训队]稳定婚姻
题面 题解 很好的\(Tarjan\)练习题. 主要讲一下如何建图. 先用\(STL \ map\)把每个人的名字映射成数字. 输入第\(i\)对夫妻时把女性映射成\(i\),把男性映射成\(i+n\ ...
- 使用yum时出现Error: rpmdb open failed解决方案
一.问题描述 使用yum安装软件时出现Error: rpmdb open failed,报错信息显示rpm数据库被损坏. 二.解决方案 重建rpm数据库. [root@localhost yum.re ...
- 安装Docker:解决container-selinux >= 2.9问题
1.安装Docker要求Centos内核版本高于3.10:通过uname -r查看当前系统的内核版本 uname -r 2.使用root登陆系统,确保yum包保持更新到最新: sudo yum ...
- springMVC 校验时,CustomValidationMessages.properties中的错误提示信息的中文乱码 问题
今天在学习springmvc的校验时,遇到了CustomValidationMessages.properties配置文件的信息,才错误提示时是乱码的问题:在网上找了很多方法都没解决:最后原来是在配置 ...
- C语言随笔4:指针数组、数组指针
数组: 1:数组名为地址,表达方法: Int A[10]; A;//数组名表示首地址 &A;//数组名加取地址符,仍然表示首地址 &A[0];//第0个元素的地址,即首地址 数组名是指 ...
- Can't bind to 'ngModel' since it isn't a known property of 'input'.
angular项目启动报错 Can't bind to 'ngModel' since it isn't a known property of 'input'. 原因:当前module模块未引入 ' ...