利用Node实现HTML5离线存储
前言
支持离线Web应用开发是HTML5的一个重点。离线Web应用就是在设备不能上网的时候仍然可以运行的应用。开发离线Web应用需要几个步骤,其中一个就是离线下必须能访问一定的资源(图像 JS css等)
HTML5引入了应用程序缓存,这意味着 web 应用可进行缓存,并可在离线时进行访问。
应用程序缓存为应用带来三个优势:
- 离线浏览 – 用户可在应用离线时使用它们
- 速度 – 已缓存资源加载得更快
- 减少服务器负载 – 浏览器将只从服务器下载更新过或更改过的资源。
原理和环境
- 在线的情况下, 当浏览器渲染到
<html manifest="test.manifest">时,会发出一个请求,请求获取test.manifest文件 ,如果是第一次访问,那么浏览器就会根据 描述文件(manifest 文件)中(CACHE MANIFEST)的内容下载相应的资源并且进行离线存储。如果已经访问过并且资源已经离线存储了,那么浏览器就会使用离线的资源加载页面,然后浏览器会对比新的manifest文件与旧的manifest文件,如果文件没有发生改变,就不做任何操作,如果文件改变了,那么就会重新下载文件中的资源并进行离线存储。
【注】 这个demo演示是为了更深的了解这个原理 - 离线的情况下,浏览器就直接使用离线存储的资源
- 就像cookie一样,HTML5的离线存储也需要服务器环境,服务端基于Node.js、Express框架和art-tmplate
描述文件
要想在缓存中保存数据,需要使用描述文件manifest 文件,列出要下载和缓存的资源
manifest 文件可分为三个部分:
- CACHE MANIFEST - 在此标题下列出的文件将在首次下载后进行缓存
- NETWORK - 在此标题下列出的文件需要与服务器的连接,且不会被缓存
- FALLBACK - 在此标题下列出的文件规定当页面无法访问时的回退页面(比如 404 页面)
- 在线的情况下,用户代理每次访问页面,都会去读一次manifest.如果发现其改变, 则重新加载全部清单中的资源
结构
【注意】 所有的你想让浏览器缓存的资源放在public静态资源文件夹中
服务端环境的搭建
npm init //生成package.json说明书文件
npm i express //安装express包
npm i --save art-template express-art-template //使用art-tmplate
// 入口文件app.js
var express = require("express");
var app = express();
app.use('/public/', express.static('./public/'))
app.engine('html', require('express-art-template'));
app.get('/', function (req, res) {
res.render('index.html');
});
app.listen(3000, function () {
console.log("app is running at port 3000.");
});
其它
offline.appcache描述文件
CACHE MANIFEST
#v01
/public/image/01.jpg //缓存第一张图片
NETWORK:
*
FALLBACK:
/
index.html
<!DOCTYPE html>
<html lang="en" manifest="../public/offline.appcache">
<head>
<meta charset="UTF-8">
<title>HTML5离线存储</title>
<link rel="stylesheet" href="../public/index.css">
</head>
<body>
<img src="../public/image/01.jpg" alt="">
<img src="../public/image/02.jpg" alt="">
</body>
</html>
结果
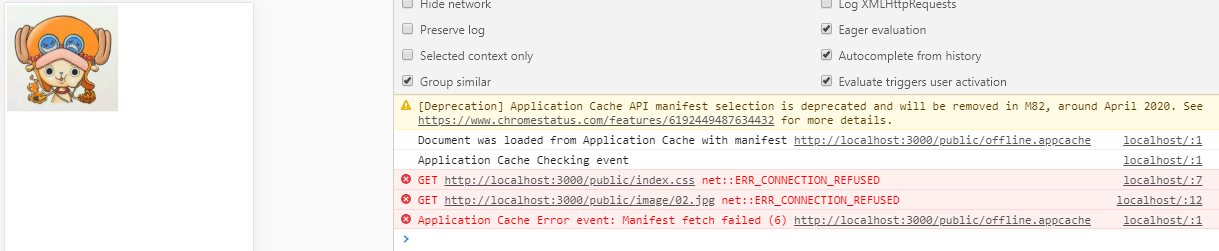
开启服务端后:


关闭服务端后:
改变manifest后 再次连接服务器
CACHE MANIFEST
#v01
/public/image/01.jpg
/public/index.css
NETWORK:
*
FALLBACK:
/
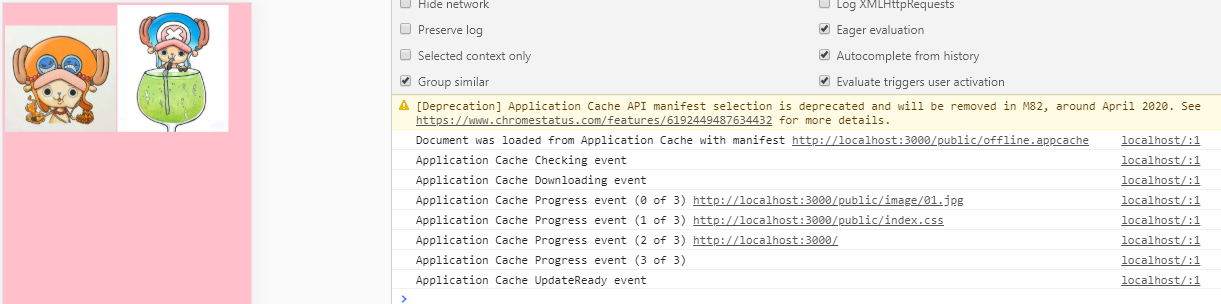
【注】看图右边控制端的输出,因为改变了manifest文件,浏览器会对比新的 manifest 文件与旧的 manifest 文件,发现文件改变了,那么就会重新下载文件中的资源并进行离线存储
再次关闭服务端后:

利用Node实现HTML5离线存储的更多相关文章
- 吓哭原生App的HTML5离线存储技术,却出乎意料的容易!【低调转载】
吓哭原生App的HTML5离线存储技术,却出乎意料的容易![WeX5低调转载] 2015-11-16 lakb248 起步软件 近几天,WeX5小编编跟部分移动应用从业人士聊了聊,很多已经准备好全面拥 ...
- html5 离线存储
在html页面中引入manifest文件 <html manifest="sample.appcache"> 在服务器添加mime-type text/cache-ma ...
- HTML5离线存储原理
找到一篇介绍离线缓存的,感觉比之前看到的解释的更透彻,新的知识点记录如下: 大家都知道Web App是通过浏览器来访问的,所以离线状态下是无法使用app的.其中web app中的一些资源并不经常改变, ...
- html5 离线存储 worker
html5 离线存储 <!DOCTYPE html> <html manifest="cache.manifest"> <!--manifest存储- ...
- 神奇的HTML5离线存储(应用程序缓存)
声明:本文为原创文章,如需转载,请注明来源并保留原文链接前端小尚,谢谢! 前言 使用 HTML5,通过创建 cache manifest 文件,可以轻松地创建 web 应用的离线版本. HTML5引入 ...
- 【html5】html5离线存储
html5本地存储之离线存储 1.为什么使用离线存储 ①最新的主流的浏览器中都已添加了对HTML5的offline storage功能的支持,HTML5离线存储功能非常强大, 它的作用是:在用户没有与 ...
- html5离线存储
为了提升Web应用的用户体验,我们在做网站或者webapp的时候,经常需要保存一些内容到本地.例如,用户登录token,或者一些不经常变动的数据. 随着HTML5的到来,出现了诸如AppCache.l ...
- HTML5离线存储的工作原理和使用
在用户没有与因特网连接时,可以正常访问站点或应用,在用户与因特网连接时,更新用户机器上的缓存文件. 原理:HTML5的离线存储是基于一个新建的.appcache文件的缓存机制(不是存储技术),通过这个 ...
- HTML5离线存储整理
前端html部分 //canvas.html <!DOCTYPE html> <html manifest="/test.appcache"> <he ...
随机推荐
- .Net Core中的诊断日志DiagnosticSource讲解
前言 近期由于需要进行分布式链路跟踪系统的技术选型,所以一直在研究链路跟踪相关的框架.作为能在.Net Core中使用的APM,SkyWalking自然成为了首选.SkyAPM-dotnet是 ...
- maatwebsite lost precision when export long integer data
Maatwebsite would lost precision when export long integer data, no matter string or int storaged in ...
- MySQL数据库下统计记录数小于指定数值的数据
楼主在做一个智慧工地的产品,需要对工人进行一些数据统计,比如要统计导入人员数量小于30的工地,SQL应该怎么写呢? 首先了解一下数据结构,工地分三张表,四级层级关系,Organization表存储区域 ...
- SpringBoot集成Swagger2,3分钟轻松入手!
一.引入maven <dependency> <groupId>io.springfox</groupId> <artifactId>springfox ...
- 使用ClickHouse表函数将MySQL数据导入到ClickHouse
#clickhouse-client :create database dw; :use dw; --导入数据: CREATE TABLE Orders ENGINE = MergeTree ORDE ...
- Java面试题(异常篇)
异常 74.throw 和 throws 的区别? throws是用来声明一个方法可能抛出的所有异常信息,throws是将异常声明但是不处理,而是将异常往上传,谁调用我就交给谁处理.而throw则是指 ...
- 分享几个好用的ui框架,以便开发
1:Layui--经典模块化前端框架 地址:https://www.layui.com/ 2:iview--基于 Vue.js 的高质量 UI 组件库 地址:http://v1.iviewui.com ...
- Fitness - 05.08
倒计时237天 运动34分钟,共计8组,3.4公里.拉伸10分钟. 每组跑步2分钟(6.6KM/h),走路2分钟(6KM/h). 最近掉了几斤,所以今天状态感觉特别好. 虽然每天在拼命学习Unity, ...
- C# Beanstalkd Client
http://bestmike007.com/Beanstalkd.Client/ Other Message Queue http://queues.io
- 网络协议HTTP、TCP/IP、Socket
网络协议HTTP.TCP/IP.Socket 网络七层由下往上分别为物理层.数据链路层.网络层.传输层.会话层.表示层和应用层. 其中物理层.数据链路层和网络层通常被称作媒体层,是网络工程师所研究的 ...