python之 栈与队列
忍不住想报一句粗口“卧槽”这尼玛python的数据结构也太特么方便了吧
想到当初学c语言的数据结构的时候,真的是一笔一划都要自己写出来,这python尼玛直接一个模块就ok
真的是没有对比就没有伤害啊,之前试着用类来模拟栈与队列的时候就感觉,我擦这还挺方便的。
现在直接就可以import了,直接使用函数了,唉,这这这现在只想说一声,
人生苦短,我用python
当然栈好像没有这个库
.栈(stacks)是一种只能通过访问其一端来实现数据存储与检索的线性数据结构,具有后进先出(last in first out,LIFO)的特征
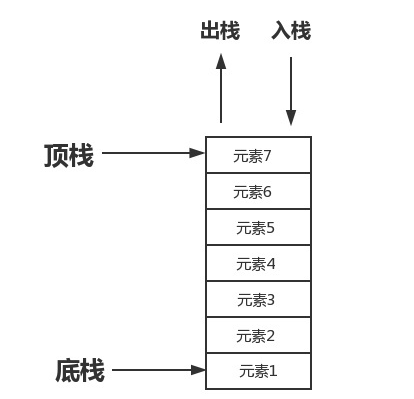
我们可以用这张图来说明栈的应用,那么栈呢有以下功能
def push(self, num):
# 把一个元素添加到栈的最顶层
def pop(self):
# 删除栈最顶层的元素,并返回这个元素
def peek(self):
# 返回最顶层的元素,并不删除它
def isEmpty(self):
# 判断栈是否为空
def size(self):
# 返回栈中元素的个数
我们这里用顺序来实现栈的功能
class Stack(object):
def __init__(self):
self.__Stack = []
def push(self, num):
# 把一个元素添加到栈的最顶层
self.__Stack.append(num)
def pop(self):
# 删除栈最顶层的元素,并返回这个元素
return self.__Stack.pop()
def peek(self):
return self.__Stack[len(self.__Stack)-1]
# 返回最顶层的元素,并不删除它
def isEmpty(self):
return self.__Stack == []
# 判断栈是否为空
def size(self):
return len(self.__Stack)
# 返回栈中元素的个数 s = Stack()
当然如果你愿意的话同样可以构成一个链式的栈
队列(queue·)我操,这个就厉害了直接导入一个函数就ok了
import queue
我们不妨大胆的help一下 help(queue)
就有了这样的东西
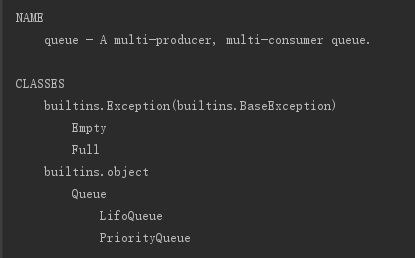
我们只需要关注 queue 和lifoqueue(先进先出队列),priorityqueue(优先级队列)
当然一般的queue都是先进后出啦,
empty(self)
| Return True if the queue is empty, False otherwise (not
reliable!).
|
| This method is likely to be removed at some point. Use
qsize() == 0
| as a direct substitute, but be aware that either approach
risks a race
| condition where a queue can grow before the result of
empty() or
| qsize() can be used.
|
| To create code that needs to wait for all queued tasks to
be
| completed, the preferred technique is to use the join()
method.
|
| full(self)
| Return True if the queue is full, False otherwise (not
reliable!).
|
| This method is likely to be removed at some point. Use
qsize() >= n
| as a direct substitute, but be aware that either approach
risks a race
| condition where a queue can shrink before the result of
full() or
| qsize() can be used.
|
| get(self, block=True, timeout=None)
| Remove and return an item from the queue.
|
| If optional args 'block' is true and 'timeout' is None (the
default),
| block if necessary until an item is available. If 'timeout' is
| a non-negative number, it blocks at most 'timeout'
seconds and raises
| the Empty exception if no item was available within that
time.
| Otherwise ('block' is false), return an item if one is
immediately
| available, else raise the Empty exception ('timeout' is
ignored
| in that case).
|
| get_nowait(self)
| Remove and return an item from the queue without
blocking.
|
| Only get an item if one is immediately available.
Otherwise
| raise the Empty exception.
|
| join(self)
| Blocks until all items in the Queue have been gotten and
processed.
|
| The count of unfinished tasks goes up whenever an item
is added to the
| queue. The count goes down whenever a consumer
thread calls task_done()
| to indicate the item was retrieved and all work on it is
complete.
|
| When the count of unfinished tasks drops to zero, join()
unblocks.
|
| put(self, item, block=True, timeout=None)
| Put an item into the queue.
|
| If optional args 'block' is true and 'timeout' is None (the
default),
| block if necessary until a free slot is available. If 'timeout'
is
| a non-negative number, it blocks at most 'timeout'
seconds and raises
| the Full exception if no free slot was available within that
time.
| Otherwise ('block' is false), put an item on the queue if a
free slot
| is immediately available, else raise the Full exception
('timeout'
| is ignored in that case).
|
| put_nowait(self, item)
| Put an item into the queue without blocking.
|
| Only enqueue the item if a free slot is immediately
available.
| Otherwise raise the Full exception.
|
| qsize(self)
| Return the approximate size of the queue (not reliable!).
|
| task_done(self)
| Indicate that a formerly enqueued task is complete.
|
| Used by Queue consumer threads. For each get() used
to fetch a task,
| a subsequent call to task_done() tells the queue that the
processing
| on the task is complete.
|
| If a join() is currently blocking, it will resume when all
items
| have been processed (meaning that a task_done() call
was received
| for every item that had been put() into the queue).
|
| Raises a ValueError if called more times than there were
items
| placed in the queue.
好啦这是直接help出来的,总结一下就是
get(self, block=True, timeout=None) # 出队列
put(self, item, block=True, timeout=None) # 进队列 block是堵塞的意思,如果等于false则报错,
task_done(self) # 指示以前加入队列的任务已完成
python之 栈与队列的更多相关文章
- 【DataStructure In Python】Python模拟栈和队列
用Python模拟栈和队列主要是利用List,当然也可以使用collection的deque.以下内容为栈: #! /usr/bin/env python # DataStructure Stack ...
- 使用python实现栈和队列
1.使用python实现栈: class stack(): def __init__(self): self.stack = [] def empty(self): return self.stack ...
- Python实现栈、队列
目录 1. 栈的Python实现 1.1 以列表的形式简单实现栈 1.2 以单链表形式实现栈 2. 队列的Python实现 2.1 以列表实现简单队列 2.2 以单链表形式实现队列 本文将使用py ...
- python之栈与队列
这个在官网中list支持,有实现. 补充一下栈,队列的特性: 1.栈(stacks)是一种只能通过访问其一端来实现数据存储与检索的线性数据结构,具有后进先出(last in first out,LIF ...
- Python 实现栈与队列
#基于Python2.7 #基于顺序表实现 #发现用Python写题时,没有像写C++时方便的STL可用,不过查阅资料之后发现用class实现也很简洁,不过效率应该不是很高 Python实现栈并使用: ...
- python之栈和队列
1. 栈 1.1 示例 #!/usr/bin/env python # -*- codinfg:utf-8 -*- ''' @author: Jeff LEE @file: .py @time: 20 ...
- Python数据结构——栈、队列的实现(二)
1. 一个列表实现两个栈 class Twostacks(object): def __init__(self): self.stack=[] self.a_size=0 self.b_size=0 ...
- Python数据结构——栈、队列的实现(一)
1. 栈 栈(Stack)是限制插入和删除操作只能在一个位置进行的表,该位置是表的末端,称为栈的顶(top).栈的基本操作有PUSH(入栈)和POP(出栈).栈又被称为LIFO(后入先出)表. 1.1 ...
- Python的栈和队列实现
栈 class Node: def __init__(self, data=None): self.next = None self.data = data class Stack: def __in ...
随机推荐
- Cypress系列(65)- 测试运行失败自动重试
如果想从头学起Cypress,可以看下面的系列文章哦 https://www.cnblogs.com/poloyy/category/1768839.html 重试的介绍 学习前的三问 什么是重试测试 ...
- FY2E HDF格式数据处理绘图
圆盘标称投影数据时静止气象卫星常见的数据产品,比如FY2E静止气象卫星就有很多这样的产品(可以从国家卫星气象中心网站上下载).所谓的圆盘标称投影就是Geostationary投影,主要的投影参数有中央 ...
- Linux发行版教你如何选 给入门者的选择通法
Linux的发行版何止琳琅满目,简直是乱入你眼. 本篇将介绍选择发行版的经验和通用法则,主要会从PC角度去谈. 更新于2020年,初次发布于2017年 选择发行版需考虑哪些因素 选择发行版时需要考虑的 ...
- 原生js实现一个自定义下拉单选选择框
浏览器自带的原生下拉框不太美观,而且各个浏览器表现也不一致,UI一般给的下拉框也是和原生的下拉框差别比较大的,这就需要自己写一个基本功能的下拉菜单/下拉选择框了.最近,把项目中用到的下拉框组件重新封装 ...
- C# 微信共享收货地址 V1.6
//使用微信共享收货地址在跳转到当前页面的路径上必须要包含Code和state这两个获取用户信息的参数//例如 <a href="ProductOrder.aspx?OID=<% ...
- 如何使用性能分析工具定位SQL执行慢的原因?
但实际上 SQL 执行起来可能还是很慢,那么到底从哪里定位 SQL 查询慢的问题呢?是索引设计的问题?服务器参数配置的问题?还是需要增加缓存的问题呢?性能分析来入手分析,定位导致 SQL 执行慢的原因 ...
- [阿里DIN] 深度兴趣网络源码分析 之 整体代码结构
[阿里DIN] 深度兴趣网络源码分析 之 整体代码结构 目录 [阿里DIN] 深度兴趣网络源码分析 之 整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x0 ...
- spring的xml文件的作用与实现原理
1.Spring读取xml配置文件的原理与实现 https://www.cnblogs.com/wyq178/p/6843502.html 2.首先使用xml配置文件的好处是参数配置项与代码分离,便于 ...
- kettle插入更新流程
kettle转换步骤工作组件 这里有四个类构成了这个kettle 步骤/节点,每一个类都有其特定的目的及所扮演的角色. TemplateStep: 步骤类实现了StepInteface接口,在转换运 ...
- JS如何避免重复性触发操作
btn的click事件,每次点击都会执行给定的function,如果function复杂的话,很容易消耗内存 解决方法--setTimeout延时处理. 给function做延迟处理,比如600毫秒后 ...