docker+mysql集群+读写分离+mycat管理+垂直分库+负载均衡
依然如此,只要大家跟着我的步骤一步步来,100%是可以测试成功的
centos6.8已不再维护,可能很多人的虚拟机中无法使用yum命令下载docker,
但是阿里源还是可以用的 因为他的centos-vault仓库里放了之前版本的centos的包
只需要在centos命令行界面下执行一下几条命令
sed -i "s|enabled=1|enabled=0|g" /etc/yum/pluginconf.d/fastestmirror.conf
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
curl -o /etc/yum.repos.d/CentOS-Base.repo https://www.xmpan.com/Centos-6-Vault-Aliyun.repo
yum clean all
yum makecache
然后执行如下命令安装docker
yum install https://get.docker.com/rpm/1.7.1/centos-6/RPMS/x86_64/docker-engine-1.7.1-1.el6.x86_64.rpm
如果提示检查软件失败什么的,可以试试使用命令 yum remove docker 删除docker,再执行安装
安装完成后可以给docker配置一下阿里云的加速器,具体方法自行百度,在此不再过多赘述
docker安装完成后开始准备搭建Mysql,我一直强调开发中应秉承约定>配置>编码,接下来就按部就班先准备环境:
我准备了两台虚拟机130(主),和131(从),首先在两台电脑上分别通过docker安装mysql
因为需要配置读写分离,一定要挂载mysql配置文件目录到主机
docker pull mysql:5.6 //拉取mysql镜像 docker run -p 3306:3306 --name mysql -v $PWD/conf:/etc/mysql/conf.d -v $PWD/logs:/logs -v $PWD/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.6 docker cp containedID:/etc/mysql/my.cnf $PWD //拷贝一份容器内的配置文件
两台虚拟机执行相同的操作,配置主从Mysql的数据库版本最好一致
首先是主库的my.cnf的配置:
在mysql的配置文件的 [mysqld] 下面修改(从库也是如此):
#开启主从复制,主库的配置(log-bin属性在配置主从时才指定,单机不需要) log-bin= mysql3306-bin #指定主库serverid
#server-id 主库和从库都需要指定,不过主库的server-id必须小于从库的server-id(重要)
server-id=1 #指定同步的数据库,如果不指定则同步全部数据库(一般不需要指定) #binlog-do-db=mybatis_1128 #(配置文件中输入的这些命令一定要和下面有一行空格,不然MySQL不识别)
执行SQL语句查询状态:
SHOW MASTER STATUS

需要记录下Position值,需要在从库中设置同步起始值。(重要)
然后重启130(主),使配置文件生效
docker restart containerID
配置131(从)的my.cnf:
仅仅需要指定一个server-id=2即可
然后重启131(从),使配置文件生效
通过sqlyog连接两台mysql服务器(注意开放端口,笔者为了测试,直接停掉了防火墙)
接着在130(主)中输入以下命令:
GRANT REPLICATION SLAVE ON *.* TO 'slave01'@'192.168.209.131'IDENTIFIED BY '123456'; FLUSH PRIVILEGES;
意思是添加一个slave可以登入的用户,用户名为slave01,密码为123456,只有通过131(从),才可登入
完成后在131(从)中执行以下命令:
CHANGE MASTER TO
MASTER_HOST='192.168.209.130',
MASTER_USER='slave01', MASTER_PASSWORD='123456', MASTER_PORT=3306, MASTER_LOG_FILE='mysql3306-bin.000011', MASTER_LOG_POS=38301;
START SLAVE;//开启主从配置
SHOW SLAVE STATUS //查看主从配置状态信息
38301以及mysql3308-bin.000011对应130(主)中的position和file字段(重要)
如果 show slave status 后,slave_io_running 和slave_sql_running 值都为yes,则配置成功,
直接在130(主)上随便建个数据库,发现131(从)也生成了相同的数据库
到此,Mysql主从配置结束。
很多人配置完成后,就开始在代码中配置双数据源,通过代码来实现数据源的切换以达到读写分离的目的,我一直强调,约定>配置>编码,这种做法显然是不可取的,既然配置了主从,为什么不去选择一种高效明了的管理方式呢?
这就引出了这篇文章的重点:mycat
mycat是
1、一个彻底开源的,面向企业应用开发的大数据库集群
2、支持事务、ACID、可以替代MySQL的加强版数据库
3、一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
4、一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
5、结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
6、一个新颖的数据库中间件产品
mycat就是为集群而生的,并能通过简单配置达到数据库分片的目的
- 下载安装Mycat 执行如下命令:
docker pull longhronshens/mycat-docker mkdir -p /usr/local/mycat cd /usr/local/mycat
进入我们新建的mycat目录,将server.xml rule.xml schema.xml复制到该目录下,三个文件的基本内容如下:schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" /> <!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<!-- random sharding using mod sharind rule -->
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3"
rule="mod-long" />
<!-- <table name="dual" primaryKey="ID" dataNode="dnx,dnoracle2" type="global"
needAddLimit="false"/> <table name="worker" primaryKey="ID" dataNode="jdbc_dn1,jdbc_dn2,jdbc_dn3"
rule="mod-long" /> -->
<table name="employee" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile" />
<table name="customer" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id"
parentKey="id">
<childTable name="order_items" joinKey="order_id"
parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id"
parentKey="id" />
</table>
<!-- <table name="oc_call" primaryKey="ID" dataNode="dn1$0-743" rule="latest-month-calldate"
/> -->
</schema>
<!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743"
/> -->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<!--<dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" />
<dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" />
<dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" />
<dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="192.168.209.130:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.209.130:3306" user="root" password="123456" />
</writeHost>
<writeHost host="hostS1" url="192.168.209.130:3306" user="root"
password="123456" />
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<!--
<dataHost name="sequoiadb1" maxCon="1000" minCon="1" balance="0" dbType="sequoiadb" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="sequoiadb://1426587161.dbaas.sequoialab.net:11920/SAMPLE" user="jifeng" password="jifeng"></writeHost>
</dataHost> <dataHost name="oracle1" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="oracle" dbDriver="jdbc"> <heartbeat>select 1 from dual</heartbeat>
<connectionInitSql>alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'</connectionInitSql>
<writeHost host="hostM1" url="jdbc:oracle:thin:@127.0.0.1:1521:nange" user="base" password="123456" > </writeHost> </dataHost> <dataHost name="jdbchost" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="mongodb" dbDriver="jdbc">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM" url="mongodb://192.168.0.99/test" user="admin" password="123456" ></writeHost> </dataHost> <dataHost name="sparksql" maxCon="1000" minCon="1" balance="0" dbType="spark" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="jdbc:hive2://feng01:10000" user="jifeng" password="jifeng"></writeHost> </dataHost> --> <!-- <dataHost name="jdbchost" maxCon="1000" minCon="10" balance="0" dbType="mysql"
dbDriver="jdbc"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1"
url="jdbc:mysql://localhost:3306" user="root" password="123456"> </writeHost>
</dataHost> -->
</mycat:schema>server.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 --> <property name="sequnceHandlerType">2</property>
<!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议-->
<!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号-->
<!-- <property name="processorBufferChunk">40960</property> -->
<!--
<property name="processors">1</property>
<property name="processorExecutor">32</property>
-->
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena-->
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequnceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property> <!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">1</property> <!--
单位为m
-->
<property name="memoryPageSize">1m</property> <!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property> <property name="useStreamOutput">0</property> <!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property> <!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">true</property> </system> <!-- 全局SQL防火墙设置 -->
<!--
<firewall>
<whitehost>
<host host="127.0.0.1" user="mycat"/>
<host host="127.0.0.2" user="mycat"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
--> <user name="root">
<property name="password">123456</property>
<property name="schemas">TESTDB</property> <!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user> <user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user> </mycat:server>rule.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule> <tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule> <tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule> <tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule> <tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule> <function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function> <function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function> <function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function> <function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function> <function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
</mycat:rule>启动mycat
docker run --name mycat -v /usr/local/mycat/schema.xml:/usr/local/mycat/conf/schema.xml -v /usr/local/mycat/rule.xml:/usr/local/mycat/conf/rule.xml -v /usr/local/mycat/server.xml:/usr/local/mycat/conf/server.xml --privileged=true -p 8066:8066 -p 9066:9066 -e MYSQL_ROOT_PASSWORD=123456 -d longhronshens/mycat-docker
- 配置mycat mycat正常启动后就可以开始配置mycat关于Mysql的集群配置了 首先是schema.xml中的配置:
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">//一个schema标签就是一个逻辑库,是我们连接mycat所要查询的库,对应于Mysql物理库中的database name:库名称 checkSQLschema:mycat对sql语句的过滤策略
<table name="company" dataNode="dn1,dn2,dn3" rule="crc32slot" type="global" /> //一个table就是一个逻辑表,表名称为company,dataNode为库节点,需要配置分片就写多个,用逗号隔开,没有分片就写一个,rule为分片策略,对应于rule.xml中的策略
</schema>//type="global"为全局策略,亲自测试配置上这个属性后,数据将会重复插入所有的db1,db2,db3中,分片不起作用<dataNode name="dn1" dataHost="localhost1" database="db1" /> //database对应物理数据库 name对应上边schema节点的dataNode属性
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" /><dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> //writeType属性负载均衡类型,目前的取值有3种:
1. writeType="0", 所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .
2. writeType="1",所有写操作都随机的发送到配置的writeHost。
3. writeType="2",没实现。1.当balance=0 时,不开启读写分离,所有读操作都发生在当前的writeHost上
当balance=1 ,所有读操作都随机发送到当前的writeHost对应的readHost和备用的writeHost 一般配置读写分离balance值为1即可
当balance=2,所有的读操作都随机发送到所有的writeHost,readHost上
当balance=3 ,所有的读操作都只发送到writeHost的readHost上
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="192.168.209.130:3306" user="root"
password="123456"> //130(主) 写操作
<readHost host="hostS1" url="192.168.209.131:3306" user="root" password="123456" /> //131(从) 读操作
<!-- can have multi read hosts -->
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>然后是server.xml的配置
<user name="root">
<property name="password">123456</property> //mycat对外提供服务的用户名和密码,使用Mycat后,就直接将mycat当成mysql使用即可
<property name="schemas">TESTDB</property> //逻辑库名称对应schema.xml中的名字 <!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>rule.xml
<function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">3</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function> - 配置130(主),131(从)数据库 在130(主)上新建db1,db2,db3三个数据库(mycat只能新建表,无法新建数据库,表也必须是schema.xml中指定过的table)
- 测试mycat 我的mycat与130(主)是同一台虚拟机,在130(主)上重新启动Mycat,使配置文件生效(schema.xml 中 去掉type="global"属性)
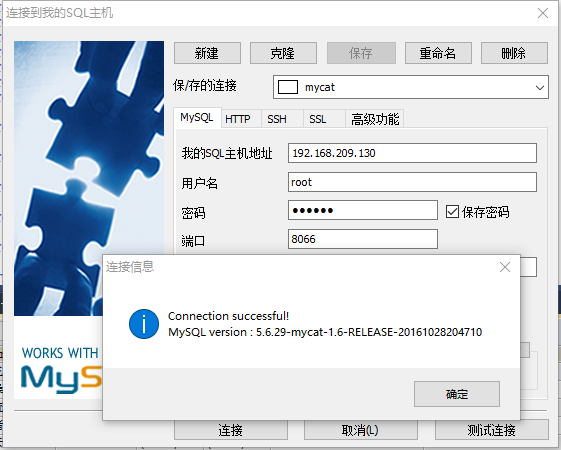
mycat对外提供服务的默认端口号为8066
在mycat中创建表:CREATE TABLE `company` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`username` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用户名',
`password` VARCHAR(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '密码,加密存储',
`phone` VARCHAR(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '注册手机号',
`email` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '注册邮箱',
`created` DATETIME(0) NOT NULL,
`updated` DATETIME(0) NOT NULL,
PRIMARY KEY (`id`)
);在Mycat中插入数据:
INSERT INTO company(id,username) VALUES('1','张飞');
INSERT INTO company(id,username) VALUES('2','樊哙');
INSERT INTO company(id,username) VALUES('3','曹操');
INSERT INTO company(id,username) VALUES('4','刘备');
INSERT INTO company(id,username) VALUES('5','庞统');
INSERT INTO company(id,username) VALUES('6','许诸');
INSERT INTO company(id,username) VALUES('7','赵云');
INSERT INTO company(id,username) VALUES('8','关羽'); INSERT INTO company(id,username) VALUES('9','关羽1'); INSERT INTO company(id,username) VALUES('10','关羽2'); INSERT INTO company(id,username) VALUES('11','关羽3'); INSERT INTO company(id,username) VALUES('12','关羽4'); INSERT INTO company(id,username) VALUES('13','关羽5');
然后查看130(主)数据库数据:
db1: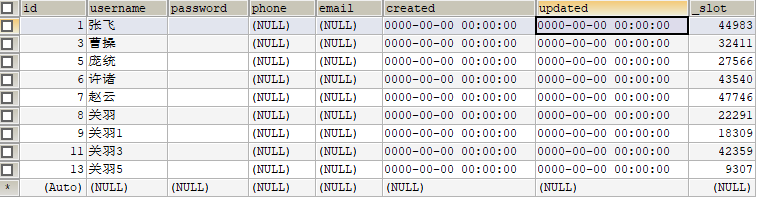
db2:
mycat中执行查询 select * from company:
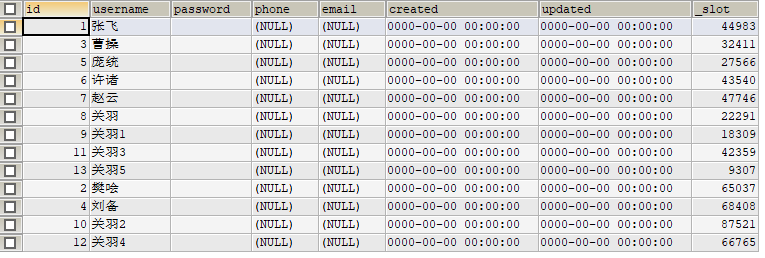
数据都能查出来,没有问题
接下来在131(从)db1插入一条数据,这时130(主)中没有该条数据,继续在mycat中执行查询select * from company;

查出来了该test数据,说明读写分离配置成功。
docker+mysql集群+读写分离+mycat管理+垂直分库+负载均衡的更多相关文章
- MySQL集群读写分离的自定义实现
基于MySQL Router可以实现高可用,读写分离,负载均衡之类的,MySQL Router可以说是非常轻量级的一个中间件了.看了一下MySQL Router的原理,其实并不复杂,原理也并不难理解, ...
- Mysql集群读写分离(Amoeba)
Amoeba原理戳这里:Amoeba详细介绍 实验环境 Master.Amoeba--IP:192.168.1.5 Slave---IP:192.168.1.10 安装JDK JDK下载地址:http ...
- 使用mysql-proxy 快速实现mysql 集群 读写分离
目前较为常见的mysql读写分离分为两种: 1. 基于程序代码内部实现:在代码中对select操作分发到从库:其它操作由主库执行:这类方法也是目前生产环境应用最广泛,知名的如DISCUZ X2.优点是 ...
- 重新学习Mysql数据13:Mysql主从复制,读写分离,分表分库策略与实践
一.MySQL扩展具体的实现方式 随着业务规模的不断扩大,需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量. 关于数据库的扩展主要包括:业务拆分.主从复制.读写分离.数据库分库 ...
- MySQL集群系列2:通过keepalived实现双主集群读写分离
在上一节基础上,通过添加keepalived实现读写分离. 首先关闭防火墙 安装keepalived keepalived 2台机器都要安装 rpm .el6.x86_64/ 注意上面要替换成你的内核 ...
- 十四、linux-MySQL的数据库集群读写分离及高可用性、备份等
一.数据库集群及高可用性 二.mysql实现读写分离 mysql实现读写分离有多种方式: 1)代码语言(php\python\java等)层面实现读写分离,找开发进行实现. 2)通过软件工具实现读写分 ...
- Mysql读写分离 及高可用高性能负载均衡实现
什么是读写分离,说白了就是mysql服务器读的操作和写的操作是分开的,当然这个需要两台服务器,master负责写,slave负责读,当然我们可以使用多个slave,这样我们也实现了简单意义上的高可用和 ...
- LVS集群中实现的三种IP负载均衡技术
LVS有三种IP负载均衡技术:VS/NAT,VS/DR,VS/TUN. VS/NAT的体系结构如图所示.在一组服务器前有一个调度器,它们是通过Switch/HUB相连接的.这些服务器 提供相同的网络服 ...
- docker 搭建Mysql集群
docker基本指令: 更新软件包 yum -y update 安装Docker虚拟机(centos 7) yum install -y docker 运行.重启.关闭Docker虚拟机 servic ...
随机推荐
- webpack项目如何正确打包引入的自定义字体
webpack项目如何正确打包引入的自定义字体 一. 如何在Vue或React项目中使用自定义字体 在开发前端项目时,经常会遇到UI同事希望在项目中使用一个炫酷字体的需求.那么怎么在项目中使用自定义字 ...
- HTML引入外部字体
HTML5如何引入外部字体 背景 现在我需要 "Montserrat-ExtraLight ExtraLight"类型的字体,但是html的font-family中找不到这个类型的 ...
- git使用-merge request开发操作步骤
0. 如果当前不在develop分支,则切换到develop分支 git checkout develop 1. 获取develop分支最新代码 git pull 注意:这一步正常来说应该是一个Fas ...
- oracle 时间段查询
<select id="selectByRzrq" resultMap="BaseResultMap" parameterType="java. ...
- 云服务器 ECS Linux 安装 VNC Server 实现图形化访问配置说明
阿里云官方公共 Linux 系统镜像,基于性能及通用性等因素考虑,默认没有安装 VNC 服务组件.本文对常见操作系统下的 VNC Server 安装配置进行简要说明. 本文中仅讨论VNC的安装,关于图 ...
- Salesforce 系列(一):云服务和 Salesforce 理念简介
本系列文章系笔者在 Salesforce 开发过程中的些许总结与心得,旨在记录自己的成长,以及为对 Salesforce 感兴趣的小伙伴提供一些帮助,如有疏漏,还望多多包涵 ~ 云服务 云服务,也称云 ...
- 剑指Java高效编程教程
教程介绍 所谓"武以快为尊,天下武功唯快不破".本课程剑指Java高效编程,致力于从"技术"和"工具"两大 维度提高编程效率,帮助广大程序员 ...
- 设置非root账号不用sudo直接执行docker命令
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- IOS开发中设置导航栏主题
/** * 系统在第一次使用这个类的时候调用(1个类只会调用一次) */ + (void)initialize { // 设置导航栏主题 UINavigationBar *navBar = [UINa ...
- CVE-2019-0708——RDP漏洞利用
影响系统:windows2003.windows2008.windows2008 R2.windows xp .win7环境:攻击机:kali ip:192.168.40.128靶机:windows ...