七、Elasticsearch+elasticsearch-head的安装+Kibana环境搭建+ik分词器安装
一、安装JDK1.8
二、安装ES
三个节点:master、slave01、slave02
1、这里下载的是elasticsearch-6.3.1.rpm版本包
https://www.elastic.co/cn/downloads/elasticsearch
wget --no-check-certificate https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.1.rpm
2、解压
rpm -ivh elasticsearch-6.3.1.rpm
- /usr/share/elasticsearch
- /usr/share/elasticsearch/bin/elasticsearch
- /var/log/elasticsearch
- /var/lib/elasticsearch
- /var/run/elasticsearch
- /etc/sysconfig/elasticsearch
- /etc/rc.d/init.d/elasticsearch
- /etc/elasticsearch
3、elasticsearch的配置文件
elasticsearch配置文件在这两个地方,有两个配置文件:
[root@master mnt]# ll /etc/elasticsearch/
总用量 28
-rw-rw---- 1 root elasticsearch 207 4月 8 18:10 elasticsearch.keystore
-rw-rw---- 1 root elasticsearch 3300 4月 8 18:14 elasticsearch.yml
-rw-rw---- 1 root elasticsearch 2920 6月 30 2018 jvm.options
-rw-rw---- 1 root elasticsearch 6380 6月 30 2018 log4j2.properties
-rw-rw---- 1 root elasticsearch 473 6月 30 2018 role_mapping.yml
-rw-rw---- 1 root elasticsearch 197 6月 30 2018 roles.yml
-rw-rw---- 1 root elasticsearch 0 6月 30 2018 users
-rw-rw---- 1 root elasticsearch 0 6月 30 2018 users_roles
[root@master mnt]# ll /etc/sysconfig/elasticsearch
-rw-rw---- 1 root elasticsearch 1613 6月 30 2018 /etc/sysconfig/elasticsearch
elasticsearch.yml 文件用于配置集群节点等相关信息的,elasticsearch 文件则是配置服务本身相关的配置,例如某个配置文件的路径以及java的一些路径配置什么的。
4、修改配置文件
master节点:
[root@master~]# vim /etc/elasticsearch/elasticsearch.yml # 增加或更改以下内容
cluster.name: elasticsearch1 # 集群中的名称
node.name: master # 该节点名称
node.master: true # 意思是该节点为主节点
node.data: false # 表示这不是数据节点
network.host: 0.0.0.0 # 监听全部ip,在实际环境中应设置为一个安全的ip
http.port: 9200 # es服务的端口号
discovery.zen.ping.unicast.hosts: ["192.168.200.100", "192.168.200.101", "192.168.200.102"] # 配置自动发现
slave01节点:
[root@slave01~]# vim /etc/elasticsearch/elasticsearch.yml # 增加或更改以下内容
cluster.name: elasticsearch1 # 集群中的名称
node.name: slave01# 该节点名称
node.master: false# 意思是该节点不为主节点
node.data: true# 表示这是数据节点
network.host: 0.0.0.0 # 监听全部ip,在实际环境中应设置为一个安全的ip
http.port: 9200 # es服务的端口号
discovery.zen.ping.unicast.hosts: ["192.168.200.100", "192.168.200.101", "192.168.200.102"] # 配置自动发现
slave02节点:
[root@slave01~]# vim /etc/elasticsearch/elasticsearch.yml # 增加或更改以下内容
cluster.name: elasticsearch1 # 集群中的名称
node.name: slave02# 该节点名称
node.master: false# 意思是该节点不为主节点
node.data: true# 表示这是数据节点
network.host: 0.0.0.0 # 监听全部ip,在实际环境中应设置为一个安全的ip
http.port: 9200 # es服务的端口号
discovery.zen.ping.unicast.hosts: ["192.168.200.100", "192.168.200.101", "192.168.200.102"] # 配置自动发现
完成以上的配置之后,到主节点上,启动es服务:
/usr/share/elasticsearch/bin
systemctl start elasticsearch.service
主节点启动完成之后,再启动其他节点的es服务。
三、服务启动异常排查(以master节点为例,实际操作了三个节点:master、slave01、slave02)
1、我这里启动主节点的时候没有启动成功,于是查看es的日志,但是却并没有生成,那就只能去看系统日志了:
[root@master~]# ls /var/log/elasticsearch/
[root@master~]# tail -n50 /var/log/message

如图,可以看到是JDK的路径配置得不对,没法在PATH里找到相应的目录。
于是查看JAVA_HOME环境变量的值指向哪里:
[root@master mnt]# echo $JAVA_HOME
/mnt/jdk1.8.0_111
发现指向的路径并没有错,那就可能是忘记在profile里写export了,于是在profile的末尾加上了这一句:
export JAVA_HOME JAVA_BIN JRE_HOME PATH CLASSPATH
[root@master mnt]# source /etc/profile
使用source命令重新加载了profile之后,重新启动es服务,但是依旧启动不起来,于是我发现我忽略了一条错误日志:

这是无法在环境变量中找到java可执行文件,那就好办了,做一个软链接过去即可:
[root@master~]# ln -s /mnt/jdk1.8.0_111/bin/java /usr/bin/
再次启动es服务,这次就终于启动成功了:
[root@master~]# systemctl restart elasticsearch.service
[root@master~]# ps aux |grep elasticsearch
elastic+ 2655 9.4 31.8 3621592 1231396 ? Ssl 15:42 0:14 /bin/java -Xms1g -Xmx1g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AlwaysPreTouch -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThrow -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Djava.io.tmpdir=/tmp/elasticsearch.4M9NarAc -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/lib/elasticsearch -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationStoppedTime -Xloggc:/var/log/elasticsearch/gc.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=32 -XX:GCLogFileSize=64m -Des.path.home=/usr/share/elasticsearch -Des.path.conf=/etc/elasticsearch -cp /usr/share/elasticsearch/lib/* org.elasticsearch.bootstrap.Elasticsearch -p /var/run/elasticsearch/elasticsearch.pid --quiet
root 2735 0.0 0.0 112660 968 pts/0 S+ 15:44 0:00 grep --color=auto elasticsearch
[root@master~]# netstat -lntp |grep java # es服务会监听两个端口
tcp6 0 0 :::9200 :::* LISTEN 2655/java
tcp6 0 0 :::9300 :::* LISTEN 2655/java
[root@master~]#
9300端口是集群通信用的,9200则是数据传输时用的。
主节点启动成功后,依次启动其他节点即可,我这里其他节点都是启动正常的。
查看集群状况:
[root@master mnt]# curl 'master:9200/_cluster/health?pretty'
{
"cluster_name" : "elasticsearch1",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 2,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
四、安装elasticsearch web页面插件
一、安装nodejs
1、环境
centos 7.3
2、elasticsearch-head的zip包,github网址如下:https://github.com/mobz/elasticsearch-head
3、nodejs的linux对应位数下载:https://nodejs.org/en/download/
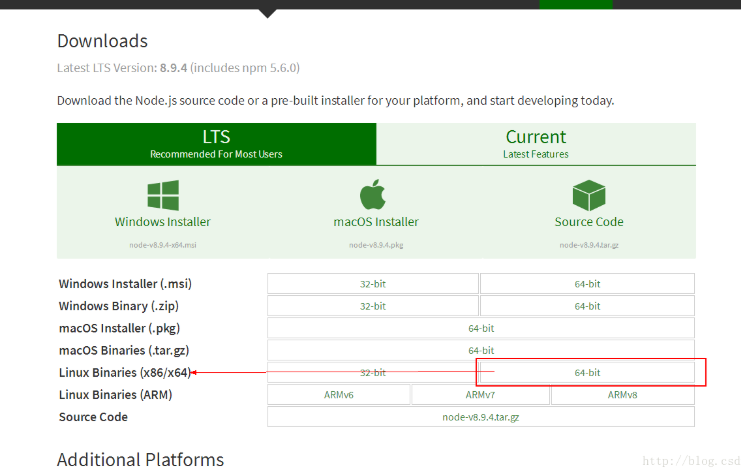
4、解压
tar -xvf node-v10.15.3-linux-x64.tar.xz
进入bin中可以看到最下面的三个可执行文件:
配置环境变量:
export NODE_HOME=/mnt/node-v8.9.4-linux-x64/
export PATH=$PATH:$NODE_HOME/bin
export NODE_PATH=$NODE_HOME/lib/node_modules
source /etc/profile
#如何检查是否安装成功了呢?此处有两个命令
一定要cd到bin的目录下进行操作,因为你的/user/bin下并没有配置相关的软连接
./node -v
./npm -v
执行第一个命令:
[root@master bin]# ./node -v
v10.15.3
执行第二个命令:
[root@master bin]# ./npm -v
/usr/bin/env: node: 没有那个文件或目录
解决办法:
推测!!因为npm执行的时候默认是使用/usr/bin/node去执行的,但我本地是没有/usr/bin/node的,所以需要创建一个
所以需要创建一个软连接将自己的node的执行文件指到/usr/bin/node上,于是修改如下:
[root@master bin]# ln -s /mnt/node-v10.15.3-linux-x64/bin/node /usr/bin/node
[root@master bin]# ./npm -v
6.4.1
到这里,npm和nodejs算是安装成功了!继续回归我们的elasticsearch-head插件的安装。
二、安装elasticsearch-head插件
1、解压:elasticsearch-head-master.zip
unzip elasticsearch-head-master.zip
[root@master mnt]# unzip elasticsearch-head-master.zip
-bash: unzip: 未找到命令
若未找到命令,先安装,再次执行解压命令
[root@master mnt]# yum -y install zip unzip
进入到elasticsearch-head主目录,如下图:
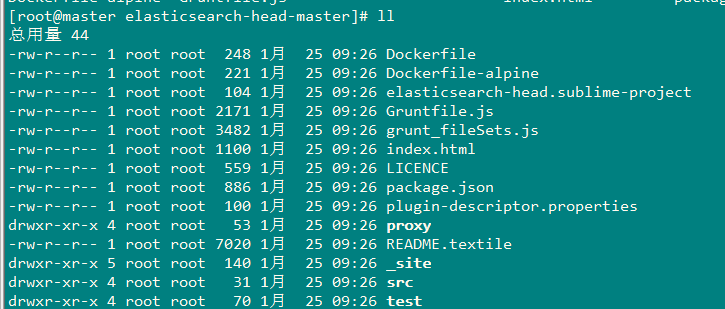
在此处运行:
[root@master elasticsearch-head-master]# pwd
/mnt/elasticsearch-head-master
[root@master elasticsearch-head-master]#npm install
-bash: npm: 未找到命令
解决办法:
nodejs 目录发现:
-rwxr-xr-x 2 root root 20231104 Mar 23 22:08 node
lrwxrwxrwx 2 root root 38 Mar 31 02:40 npm -> ../lib/node_modules/npm/bin/npm-cli.js
npm 指向另一个地址。
于是重新创建软连。
先删除原来的软连
[root@master bin]# ln -s /mnt/node-v10.15.3-linux-x64/lib/node_modules/npm/bin/npm-cli.js /usr/local/bin/npm
再次,执行。它会自动的从相应的地址进行下载对应的依赖包,从而放入到node_modules中去,如下执行过程:

安装过程中出现错误:
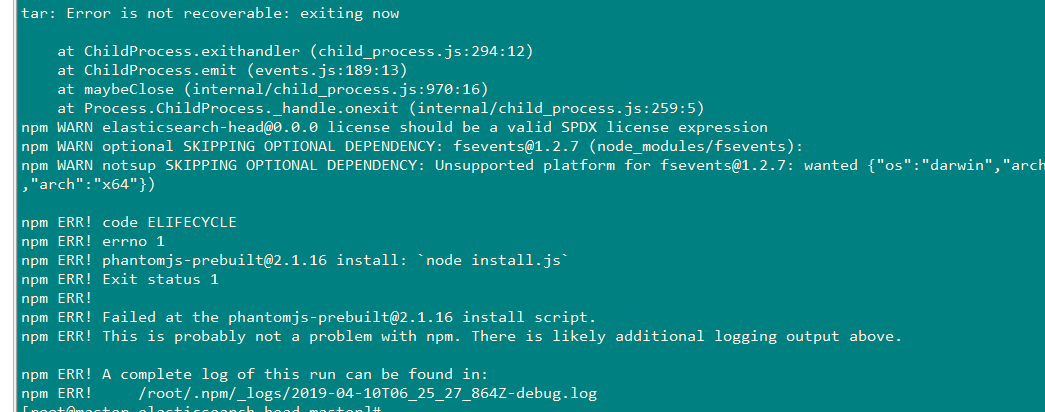
解决方案如下:
#忽略脚本继续进行安装
npm install phantomjs-prebuilt@2.1.14 --ignore-scripts
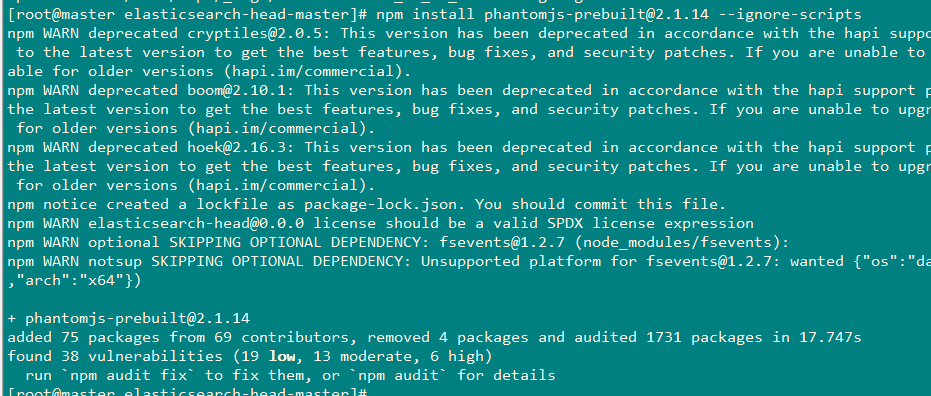
最终安装成功!成功后当前目录多了一个node_modules文件夹。。
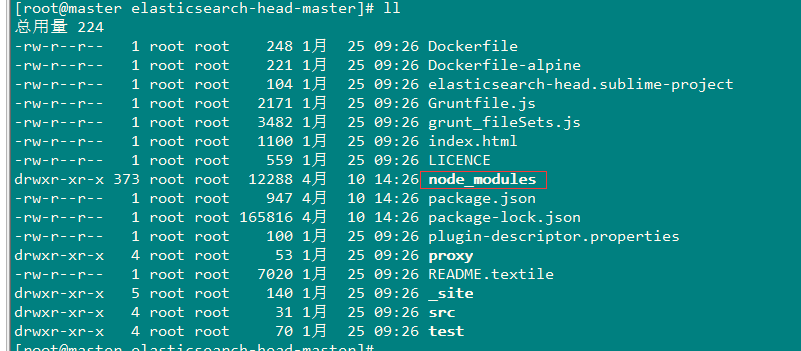
三、启动Head插件
第一步先不要着急启动,因为我是用虚拟机进行的搭建,所以希望的是本机也可以进行对应的ip网址访问,于是经各种查询,发现有2处需要注意:
1、修改/mnt/elasticsearch-head-master主目录下的Gruntfile.js
2、修改elasticearch下的配置文件
①先说修改Gruntfile.js
打开这个js文件找到如下图所示的地方,默认文件中是没有hostname属性的,我们需要手动添加。

②修改elasticsearch 的启动配置文件:/etc/elasticsearch/elasticsearch.yml
这里说下为什么需要修改配置文件:
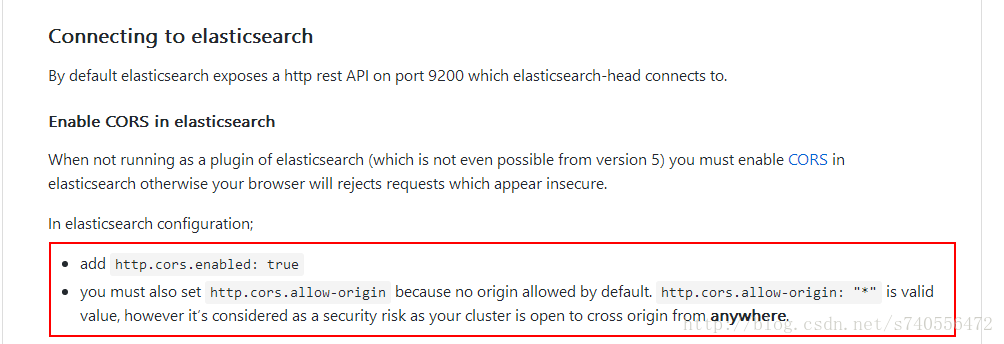
上图是从github上截的图 大致意思是,head插件连接elasticsearch需要注意的点:
因为head插件是一个独立进程,启动后是一个独立的服务器外加端口,比如我的虚拟机ip地址:http://192.168.0.111:9100/
而elasticsearch启动后也是一个独立的进程,ip地址:http://192.168.0.111:9200/
这样两个独立进程,虽然服务器ip地址相同,但是端口不同,此时会发生跨域的情况。。
于是官方给出这样一段话,我们在对elasticsearch启动的时候追加两个配置文件属性即可防止跨域。
#在文件/etc/elasticsearch/elasticsearch.yml末尾添加即可,此处需要注意yml的格式问题(有的博友已经遇到了不生效,详见评论---20180927)
http.cors.enabled: true
http.cors.allow-origin: "*"
到这里,基本需要注意的点都说到了,然后开始启动吧。
1、先启动elasticsearch:master、slave01、slave02节点:
[root@master ~]# systemctl start elasticsearch.service
[root@slave01 ~]# systemctl start elasticsearch.service
[root@slave02 ~]# systemctl start elasticsearch.service
2、启动npm(等elasticsearch完全启动之后再启动)
#切回到head的主目录下,执行如下命令
npm run start
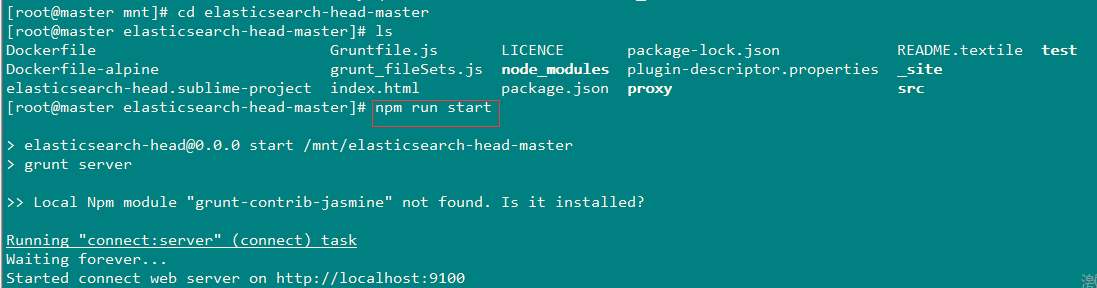
3、登录页面查看
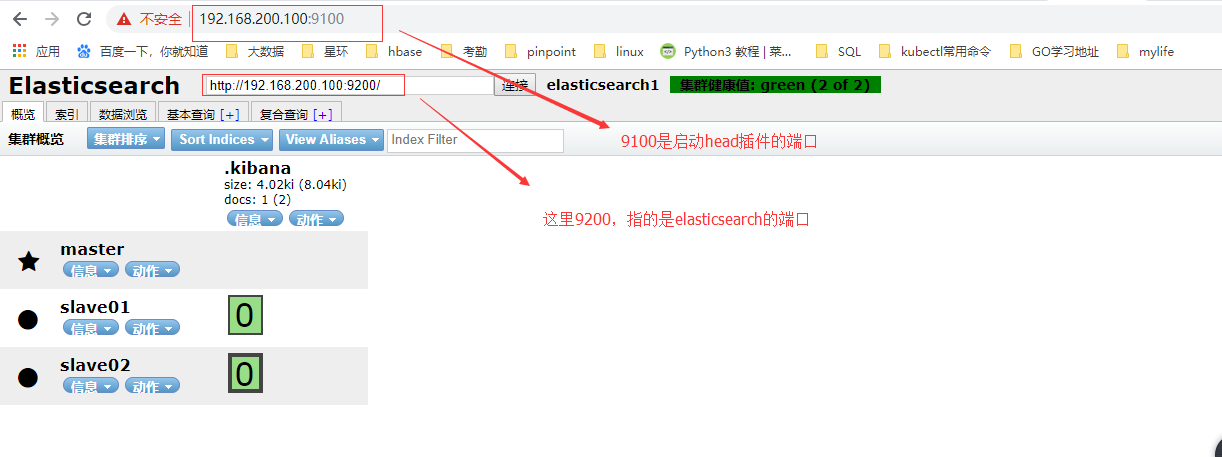
4、创建一个index
[root@master ~]# curl -XPUT '192.168.200.100:9200/employee/?pretty'
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "employee"
}
再次查看页面:
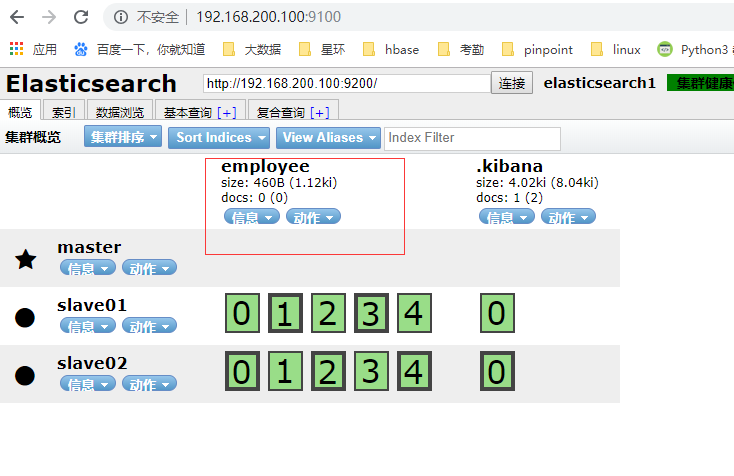
搭建head大功告成!!!!!
五、安装Kibana
1.下载https://www.elastic.co/cn/downloads/kibana 版本要和es版本相同
2、在master上解压
tar -zxvf kibana-6.3.1-linux-x86_64.tar.gz
3、修改配置文件
vim config/kibana.yml
elasticsearch.url: "http://192.168.200.101:9200" # kibana监控哪台es机器
server.port:5601
server.host: "192.168.200.101" # kibana运行在哪台机器
启动:bin/kibana
查看界面http://192.168.200.101:5601 可以直接访问

六、elasticsearch ik分词器安装
1、该插件Github官网地址:https://github.com/medcl/elasticsearch-analysis-ik 由于我安装的是elasticsearch 6.3.1 就下载了该对应版本

2、在ed主目录下的pligins目录下创建一个ik目录,将elasticsearch-analysis-ik-6.3.1.zip 包上传至该目录下进行解压。
unzip elasticsearch-analysis-ik-6.3.1.zip
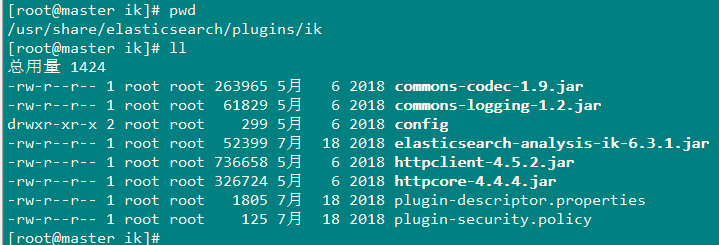
再将ik目录发送到elasticsearch集群的其他两台机器:
[root@master plugins]# scp -r ik slave01:/usr/share/elasticsearch/plugins/
[root@master plugins]# scp -r ik slave02:/usr/share/elasticsearch/plugins/
然后就可以启动es了:
安装ik分词器前后对比:
安装前:

安装后:

在启动日志中可以看到加载ik插件成功!
3、简单使用测试一下:
ik插件提供了两种分词模式:ik_max_word和ik_smart:

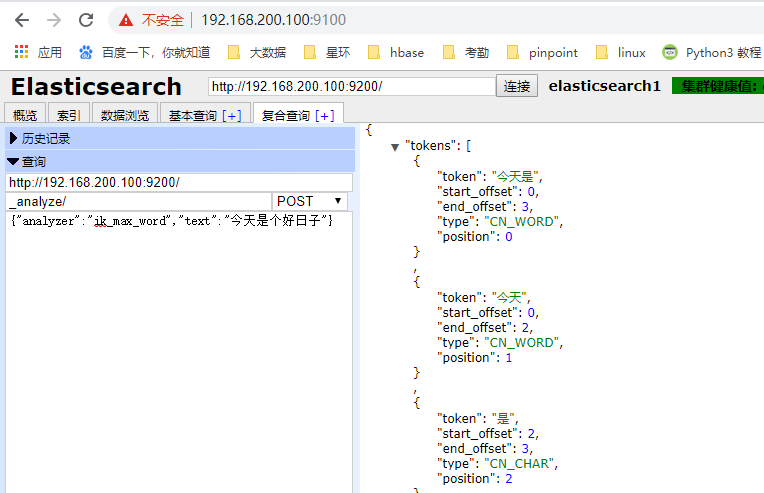
k_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
ik_smart:会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
这样就大功告成啦!!!!!!!!!!!!!!!!!!!!!!!!!
七、Elasticsearch+elasticsearch-head的安装+Kibana环境搭建+ik分词器安装的更多相关文章
- Elasticsearch教程(三),IK分词器安装 (极速版)
如果只想快速安装IK,本教程管用.下面看经过. 简介: 下面讲有我已经打包并且编辑过的zip包,你可以在下面下载即可. 当前讲解的IK分词器 包的 version 为1.8. 一.下载zip包. 下面 ...
- elasticsearch 之IK分词器安装
IK分词器地址:https://github.com/medcl/elasticsearch-analysis-ik 安装好ES之后就可以安装分词器插件了 记住选择ES对应的版本 对应的有版本选择下载 ...
- Elasticsearch学习系列一(部署和配置IK分词器)
Elasticsearch简介 Elasticsearch是什么? Elaticsearch简称为ES,是一个开源的可扩展的分布式的全文检索引擎,它可以近乎实时的存储.检索数据.本身扩展性很好,可扩展 ...
- Centos7安装elasticsearch6.3及ik分词器,设置开机自启
参考Elasticsearch 在CentOs7 环境中开机启动 建议虚拟机的内存大小为4G 1. 新建一个用户john 出于安全考虑,elasticsearch默认不允许以root账号运行. 创建用 ...
- Elasticsearch教程(二),IK分词器安装
elasticsearch-analysis-ik 是一款中文的分词插件,支持自定义词库,也有默认的词库. 开始安装. 1.下载 下载地址为:https://github.com/medcl/ela ...
- 【ELK】【docker】【elasticsearch】1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安装ik分词器
系列文章:[建议从第二章开始] [ELK][docker][elasticsearch]1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安 ...
- (2)ElasticSearch在linux环境中集成IK分词器
1.简介 ElasticSearch默认自带的分词器,是标准分词器,对英文分词比较友好,但是对中文,只能把汉字一个个拆分.而elasticsearch-analysis-ik分词器能针对中文词项颗粒度 ...
- Elasticsearch入门之从零开始安装ik分词器
起因 需要在ES中使用聚合进行统计分析,但是聚合字段值为中文,ES的默认分词器对于中文支持非常不友好:会把完整的中文词语拆分为一系列独立的汉字进行聚合,显然这并不是我的初衷.我们来看个实例: POST ...
- elasticsearch安装ik分词器(极速版)
简介:下面讲有我已经打包并且编辑过的zip包,你可以在下面下载即可. 1.下载zip包.elasticsearch-analysis-ik-1.8.0.jar下面有附件链接[ik-安装包.zip],下 ...
随机推荐
- 第十一章、Designer中主窗口QMainWindow类
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.概述 主窗口对象是在新建窗口对象时,选择main window类型的模板时创建的窗口对象,如图: ...
- js防抖与节流了解一下
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 数据库查询优化-20条必备sql优化技巧
0.序言 本文我们来谈谈项目中常用的 20 条 MySQL 优化方法,效率至少提高 3倍! 具体如下: 1.使⽤ EXPLAIN 分析 SQL 语句是否合理 使⽤ EXPLAIN 判断 SQL 语句是 ...
- Kubernetes Python Client 初体验之node操作
今天讲一下k8s中对于各个实物节点node的操作. 首先是获取所有nodes信息: self.config.kube_config.load_kube_config(config_file=" ...
- 第一章、Docker 简介
笔记内容来自:第一本Docker书 [澳] James Turnbull 著 李兆海 刘斌 巨震 Docker 是一个能够把开发的应用程序自动部署到容器的开源引擎.(由Docker 公司,前dot ...
- 二、java多线程编程核心技术之(笔记)——如何停止线程?
1.异常法 public class MyThread extends Thread { @Override public void run() { super.run(); try { for (i ...
- yum源 软件仓库 国外===国内
yum源 软件仓库 国外===国内 国内常见的软件仓库地址/yum源 1阿里云 mirrors.aliyun.com 2清华 如何修改mirrors.aliyun.com a 备份系统当前的yum [ ...
- 2020-2021-1 20209307 《Linux内核原理与分析》第八周作业
这个作业属于哪个课程 <2020-2021-1Linux内核原理与分析)> 这个作业要求在哪里 <2020-2021-1Linux内核原理与分析第八周作业> 这个作业的目标 & ...
- 网络编程-python实现-socket(1.1.1)
@ 目录 1.不同电脑进程之间如何通信 2.什么是socket 3.创建socket 1.不同电脑进程之间如何通信 利用ip地址 协议 端口 标识网络的进程,网络中的进程通信就可以利用这个标志与其他进 ...
- Acunetix 11手动导入Burp suite抓取的网页
设置爬取 因为Burp的代理默认配置拦截所有请求,需要先来关闭这个功能,在Proxy标签页面中,选择Intercept子标签页面,点击 Intercept is on按钮. 使用配置好代理服务器的浏览 ...