hbase 集群(完全分布式)方式安装
一,环境
1, 主节点一台: ubuntu desktop 16.04
zhoujun 172.16.12.1
从节点(slave)两台:ubuntu server 16.04
hadoop2 172.16.12.131
hadoop3 172.16.12.129
2, hadoop 分布式环境安装
hadoop版本,2.8.2 ,集群的安装请参考:查看 hadoop 集群安装
3, hbase 版本: 1.2.6
这里我使用的hbase自带的
二, 安装hbase 分布式环境
1, 安装前请大家一定要确保自己的hadoop环境正常运行,能够在上面读写数据,可以尝试一下方式验证hadoop 的hdfs文件系统是否正确!
hadoop fs -ls / # 查看hdfs 文件系统根目录下的文件有哪些 hadoop fs -mkdir /test # 创建一个test测试的目录 hadoop fs -put ./regionservers /test # 随便上传一个本地文件到hdfs文件系统刚才创建的test文件夹下 hadoop fs -ls /test # 查看刚才上传的文件,如果存在且没有异常信息,说明集群环境没有问题
2, 下载hbase 的bin压缩包, hbase 安装包下载

下载好后,到自己的下好刚才文件的目录下,解压压缩包,我这里移动到 /opt 文件夹下,大家可以根据自己的需求进行选择
tar -zxvf hbase-1.2.6-bin.tar.gz

将其移动到 /opt 文件夹下,可以根据自己安装目录选择,
sudo mv hbase-1.2.6 /opt/hbase
对 /opt/hbase 这个文件夹添加当前用户的所有操作权限, 我这里的用户为 zhoujun
cd /optsudo chown -R zhoujun ./hbase

3, 修改相关的配置文件
注意我的三台主机的ip以及主机名分别为:
zhoujun 172.16.12.1
hadoop2 172.16.12.131
hadoop3 172.16.12.129
首先修改自己的hbase-site.xml 文件
cd /opt/hbase/conf # 进入到hbase的配置目录
vim hbase-site.xml
<confiuration>中的内容为:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://zhoujun:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/hbase/tmp</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>zhoujun:2181,hadoop2:2181,hadoop3:2181</value>
</property>
</configuration>
修改 regionservers 文件内容,添加 regionservers 节点
我这里三台,内容如下
172.16.12.1
172.16.12.129
172.16.12.131 如果你的 ~/.bashrc 文件 或者 /etc/profile文件中没有添加 JAVA_HOME 请在 hbase-en.sh 的文件头部添加,参考 hadoop 的集群安装中的内容, 点击打开链接
4, 压缩配置好的hbase, 并传送到其他的各个主机上!
cd /opttar -zcf ./hbase.tar.gz ./hbasescp hbase.tar.gz zhoujun@hadoop2:scp hbase.tar.gz zhoujun@hadoop3:
然后登录到 各个节点上,解压文件,移动到 /opt 下并添加文件的权限
ssh hadoop2 # 登录到hadoop2 节点tar -zxvf hbase.tar.gz # 解压
sudo mv ./hbase /opt/hbase # 移动cd /optsudo chown -R zhoujun ./hbase # 添加用户 zhoujun 的权限,可以根据自己的用户设置
然后对 hadoop3 jj节点进行相同的操作,即可
5, 对每个节点添加hbase的相关配置信息到 ~/.bashrc 或者 /etc/profile 中
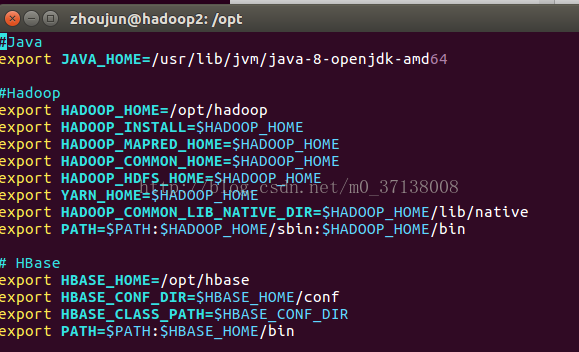
vim ~/.bashrc添加内容如下:
# HBase
export HBASE_HOME=/opt/hbase
export HBASE_CONF_DIR=$HBASE_HOME/conf
export HBASE_CLASS_PATH=$HBASE_CONF_DIR
export PATH=$PATH:$HBASE_HOME/bin
三, 测试并检测
启动相关服务
start-all.sh # 启动 hadoop, 如果启动过了,就不用
start-hbase.sh # 启动 hbase然后jps 查看进程即可:
zhoujun@zhoujun:/opt$ jps
15889 SecondaryNameNode
16067 ResourceManager
15526 NameNode
16198 NodeManager
15690 DataNode
16795 HQuorumPeer
17067 HRegionServer
16909 HMaster
17951 Jps然后启动hbase shell 测试,能够创建表,列出表,说明环境搭建成功!
zhoujun@zhoujun:/opt$ hbase shell
2017-12-19 19:24:17,722 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hbase/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017
hbase(main):001:0> list
TABLE
0 row(s) in 0.3410 seconds
=> []
hbase(main):002:0> create 'test','f'
0 row(s) in 2.4680 seconds
=> Hbase::Table - test
hbase(main):003:0> list
TABLE
test
1 row(s) in 0.0090 seconds
=> ["test"]
hbase(main):004:0>
好了。环境搭建完毕,有什么问题,欢迎大家留言交流!
hbase 集群(完全分布式)方式安装的更多相关文章
- 企业运维实践-还不会部署高可用的kubernetes集群?使用kubeadm方式安装高可用k8s集群v1.23.7
关注「WeiyiGeek」公众号 设为「特别关注」每天带你玩转网络安全运维.应用开发.物联网IOT学习! 希望各位看友[关注.点赞.评论.收藏.投币],助力每一个梦想. 文章目录: 0x00 前言简述 ...
- 从centos7镜像到搭建kubernetes集群(kubeadm方式安装)
在网上看了不少关于Kubernetes的视频,虽然现在还未用上,但是也是时候总结记录一下,父亲常教我的一句话:学到手的东西总有一天会有用!我也相信在将来的某一天会用到现在所学的技术.废话不多扯了... ...
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- hbase单机环境的搭建和完全分布式Hbase集群安装配置
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. @hbase单机环境的搭建 ...
- CentOS6.5安装HBase集群及多HMaster配置
1.配置SSH免登录 请参考:http://www.cnblogs.com/hunttown/p/5470357.html 服务器配置: Hadoop-NN-01 主Hadoop-NN-02 备Had ...
- hbase集群安装与部署
1.相关环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 hbase1.2.4 本篇文章仅涉及hbase集群的搭建,关于hadoop与zookeeper的相关部 ...
- CentOS7 安装Hbase集群
继续接上一章,已安装好Hadoop集群环境 http://www.cnblogs.com/dopeter/p/4612232.html 在此基础上继续安装Hbase集群 Hbase版本为1.0.1.1 ...
- CentOS 6 安装HBase集群教程
hbase0.99.2安装包下载(链接:https://pan.baidu.com/s/1dR-HB3P6mzsXVW6sLI8uxQ 密码:4g1n) 首先需要安装 zookeeper(点击查看) ...
- 高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南
原文:http://my.oschina.net/wstone/blog/365010#OSC_h3_13 (WJW)高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南 [X] ...
- HBase学习之路 (二)HBase集群安装
前提 1.HBase 依赖于 HDFS 做底层的数据存储 2.HBase 依赖于 MapReduce 做数据计算 3.HBase 依赖于 ZooKeeper 做服务协调 4.HBase源码是java编 ...
随机推荐
- shell脚本学习之6小时搞定(6)-重定向及其他
shell学习之-重定向及其他 目录 shell学习之-重定向及其他 1.输出重定向 2.输入重定向 3.重定向深入讲解 4./dev/null 文件 5.awk Unix 命令默认从标准输入设备(s ...
- 在kotlin用jni调用c++的dll中踩的坑
在kotlin用jni调用c++的dll中踩的坑 can't find dependents libraries 不是个有效的32位程序(或者是?????32??????) 常规检查 java 指针 ...
- swack的wiki站上线
swack的个人wiki网址:www.swack.cn [服务器破旧,速度较慢,见谅!]
- 【SpringMVC】SpringMVC 拦截器
SpringMVC 拦截器 文章源码 拦截器的作用 SpringMVC 的处理器拦截器类似于 Servlet 开发中的过滤器 Filter,用于对处理器进行预处理和后处理. 谈到拦截器,还有另外一个概 ...
- 开源:AspNetCore 应用程序热更新升级工具(全网第一份公开的解决方案)
1:下载.开源.使用教程 下载地址:Github 下载 .其它下载 开源地址:https://github.com/cyq1162/AspNetCoreUpdater 使用教程: 解压AspNetCo ...
- requests顺序执行实现
多步请求封装,执行完一个用例 def requests(self,step_info): request_type =step_info['请求方式'] if request_type==" ...
- 克隆slave
在日常生活中,我们做的比较多的操作就是在线添加从库,比如线上有一主一丛两个数据库,由于业务的需要一台从库的读取量无法满足现在的需求,这样就需要我们在线添加从库,出于安全考虑,我们通常需要在从库上进行在 ...
- RandomForest 随机森林算法与模型参数的调优
公号:码农充电站pro 主页:https://codeshellme.github.io 本篇文章来介绍随机森林(RandomForest)算法. 1,集成算法之 bagging 算法 在前边的文章& ...
- File Inclusion - Pikachu
概述: 文件包含,是一个功能.在各种开发语言中都提供了内置的文件包含函数,其可以使开发人员在一个代码文件中直接包含(引入)另外一个代码文件. 比如 在PHP中,提供了: include(),inclu ...
- 基于FPGA的光口通信开发案例|基于Kintex-7 FPGA SFP+光口的10G UDP网络通信开发案例
前言 自著名华人物理学家高锟先生提出"光传输理论",实用化的光纤传输产品始于1976年,经历了PDH→SDH→DWDM→ASON→MSTP的发展历程.本世纪初期,ASON/OADM ...