Kaggle-pandas(6)
Renaming-and-combining
教程
通常,数据会以列名,索引名或我们不满意的其他命名约定提供给我们。 在这种情况下,您将学习如何使用pandas函数将有问题的条目的名称更改为更好的名称。
Renaming
我们将在这里介绍的第一个函数是rename(),它使您可以更改索引名和/或列名。 例如,要将数据集中的点列更改为得分,我们可以
reviews.rename(columns={'points': 'score'})
通过rename(),可以分别通过指定索引或列关键字参数来重命名索引或列值。 它支持多种输入格式,但是通常最方便的是Python字典。 这是一个使用它重命名索引的某些元素的示例。
reviews.rename(index={0: 'firstEntry', 1: 'secondEntry'})
您可能会经常重命名列,但是很少重命名索引值。 为此,通常使用set_index()更方便。
行索引和列索引都可以具有自己的名称属性。 互补的rename_axis()方法可用于更改这些名称。 例如:
reviews.rename_axis("wines", axis='rows').rename_axis("fields", axis='columns')
原来的表:
现在的表:
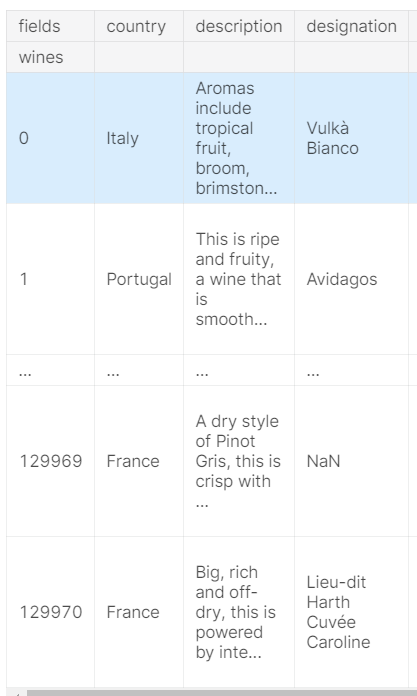
Combining
在数据集上执行操作时,有时我们需要以不平常的方式组合不同的DataFrame和/或Series。 pandas有三种核心方法可以做到这一点。 按照从简单到复杂的顺序,分别是concat(),join()和merge()。 merge()可以执行的大多数操作也可以通过join()来更简单地完成,因此我们将省略它,而只关注前两个函数。
最简单的组合方法是concat()。 给定一个元素列表,此函数会将这些元素沿轴拖在一起。
当我们在不同的DataFrame或Series对象中具有数据但具有相同的字段(列)时,这很有用。 一个示例:YouTube视频数据集,该数据集可根据来源国家/地区(例如本例中的加拿大和英国)对数据进行拆分。 如果我们想同时研究多个国家,可以使用concat()将它们混在一起:
canadian_youtube = pd.read_csv("../input/youtube-new/CAvideos.csv")
british_youtube = pd.read_csv("../input/youtube-new/GBvideos.csv")
pd.concat([canadian_youtube, british_youtube])
相当于两个表拼接到了一起。
就复杂性而言,最中间的组合器是join()。 join()使您可以组合具有共同索引的不同DataFrame对象。 例如,要提取加拿大和英国在同一天流行的视频,我们可以执行以下操作:
left = canadian_youtube.set_index(['title', 'trending_date'])
right = british_youtube.set_index(['title', 'trending_date']) left.join(right, lsuffix='_CAN', rsuffix='_UK')
这里必须使用lsuffix和rsuffix参数,因为在英国和加拿大数据集中,数据具有相同的列名。 如果这不是真的(例如,因为我们事先将其重命名),则不需要它们。
join就是数据库之中的连接操作,主键与外键需要一样。
练习
1.
region_1 and region_2 are pretty uninformative names for locale columns in the dataset. Create a copy of reviews with these columns renamed to region and locale, respectively.
# Your code here
renamed = reviews.rename(columns={'region_1': 'region','region_2':'locale'}) # Check your answer
q1.check()
2.
Set the index name in the dataset to wines.
reindexed = reviews.rename_axis("wines", axis='rows')
print(reindexed)
# Check your answer
q2.check()
3.
The Things on Reddit dataset includes product links from a selection of top-ranked forums ("subreddits") on reddit.com. Run the cell below to load a dataframe of products mentioned on the /r/gaming subreddit and another dataframe for products mentioned on the r//movies subreddit.
gaming_products = pd.read_csv("../input/things-on-reddit/top-things/top-things/reddits/g/gaming.csv")
gaming_products['subreddit'] = "r/gaming"
movie_products = pd.read_csv("../input/things-on-reddit/top-things/top-things/reddits/m/movies.csv")
movie_products['subreddit'] = "r/movies"
Create a DataFrame of products mentioned on either subreddit.
combined_products = pd.concat([gaming_products, movie_products]) # Check your answer
q3.check()
4.
The Powerlifting Database dataset on Kaggle includes one CSV table for powerlifting meets and a separate one for powerlifting competitors. Run the cell below to load these datasets into dataframes:
powerlifting_meets = pd.read_csv("../input/powerlifting-database/meets.csv")
powerlifting_competitors = pd.read_csv("../input/powerlifting-database/openpowerlifting.csv")
Both tables include references to a MeetID, a unique key for each meet (competition) included in the database. Using this, generate a dataset combining the two tables into one.
powerlifting_combined = powerlifting_meets.set_index("MeetID").join(powerlifting_competitors.set_index("MeetID"))
# Check your answer
q4.check()
Kaggle-pandas(6)的更多相关文章
- 由Kaggle竞赛wiki文章流量预测引发的pandas内存优化过程分享
pandas内存优化分享 缘由 最近在做Kaggle上的wiki文章流量预测项目,这里由于个人电脑配置问题,我一直都是用的Kaggle的kernel,但是我们知道kernel的内存限制是16G,如下: ...
- kaggle入门2——改进特征
1:改进我们的特征 在上一个任务中,我们完成了我们在Kaggle上一个机器学习比赛的第一个比赛提交泰坦尼克号:灾难中的机器学习. 可是我们提交的分数并不是非常高.有三种主要的方法可以让我们能够提高他: ...
- Kaggle入门教程
此为中文翻译版 1:竞赛 我们将学习如何为Kaggle竞赛生成一个提交答案(submisson).Kaggle是一个你通过完成算法和全世界机器学习从业者进行竞赛的网站.如果你的算法精度是给出数据集中最 ...
- 如何使用Python在Kaggle竞赛中成为Top15
如何使用Python在Kaggle竞赛中成为Top15 Kaggle比赛是一个学习数据科学和投资时间的非常的方式,我自己通过Kaggle学习到了很多数据科学的概念和思想,在我学习编程之后的几个月就开始 ...
- kaggle数据挖掘竞赛初步--Titanic<原始数据分析&缺失值处理>
Titanic是kaggle上的一道just for fun的题,没有奖金,但是数据整洁,拿来练手最好不过啦. 这道题给的数据是泰坦尼克号上的乘客的信息,预测乘客是否幸存.这是个二元分类的机器学习问题 ...
- kaggle& titanic代码
这两天报名参加了阿里天池的’公交线路客流预测‘赛,就顺便先把以前看的kaggle的titanic的训练赛代码在熟悉下数据的一些处理.题目根据titanic乘客的信息来预测乘客的生还情况.给了titan ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- 逻辑回归应用之Kaggle泰坦尼克之灾(转)
正文:14pt 代码:15px 1 初探数据 先看看我们的数据,长什么样吧.在Data下我们train.csv和test.csv两个文件,分别存着官方给的训练和测试数据. import pandas ...
- kaggle之Grupo Bimbo Inventory Demand
Grupo Bimbo Inventory Demand kaggle比赛解决方案集合 Grupo Bimbo Inventory Demand 在这个比赛中,我们需要预测某个产品在某个销售点每周的需 ...
- kaggle之人脸特征识别
Facial_Keypoints_Detection github code facial-keypoints-detection, 这是一个人脸识别任务,任务是识别人脸图片中的眼睛.鼻子.嘴的位置. ...
随机推荐
- DVWA学习记录 PartⅦ
SQL Injection 1. 题目 SQL Injection,即SQL注入,是指攻击者通过注入恶意的SQL命令,破坏SQL查询语句的结构,从而达到执行恶意SQL语句的目的. 2. Low a. ...
- 2-ADC
- .NET Core 微服务—API网关(Ocelot) 教程 [一]
前言: 最近在关注微服务,在 eShop On Containers 项目中存在一个API网关项目,引起想深入了解下它的兴趣. 一.API网关是什么 API网关是微服务架构中的唯一入口,它提供一个单独 ...
- 通过Vue实现的todolist
和接口对接的todolist因为有后台的存在,todolist获取的数据会一直存在不丢失(不管你如何刷新页面),思路如下: 首先得先搞到接口: 通过这个接口地址可以获取整段的数据,成功err为0. 于 ...
- C++语法小记---前置操作符和后置操作符
前置操作符和后置操作符 单独的"++i"和"i++"是否有区别 对于基本类型: 二者没有区别,因为编译器会对代码进行优化,二者的汇编代码完全相同 对于类类型: ...
- [redis] -- 持久化机制篇
快照(snapshotting)持久化(RDB) 该方式是redis默认 持久化方式 Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本.Redis创建快照之后,可以对快照进行备 ...
- 《java常用设计模式之----单例模式》
一.简介 单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一.这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式. 这种模式涉及到一个单一的类,该类负责创 ...
- DDD之5限界上下文-定义领域边界的利器
上图是一张普通地图,最刺眼的就是边界? 非常好奇地图绘制工程师是如何描绘如此弯曲多变的边界的?强制行政区域还是人群历史原因自然的人以群分? 我们再换个视角,对工程师或者架构师来说,微服务的边界如何划分 ...
- JMS微服务开发示例(一)Hello world
网关部署 1.在网关服务器上,安装.net core 3.1运行环境: 2.到 https://www.cnblogs.com/IWings/p/13354541.html 下载Gateway.zip ...
- CentOS7 firewalld docker 端口映射问题,firewall开放端口后,还是不能访问,解决方案
# 宿主机ip: 192.168.91.19 docker run -itd --name tomcat -p 8080:8080 tomcat /usr/local/apache-tomcat-9. ...