MapReduce框架组成
- 原文地址:MapReduce的架构组成
MapReduce基本架构
分而治之,并行计算
一句话 —— 整体主从架构,map加reduce;map、split入磁盘,数据对分partition;shuffle、sort、key-value,一个reduce解析一个partition。
一堆话 —— 如下:
和HDFS一样,MapReduce也是采用Master/Slave的架构,其架构如下图所示:
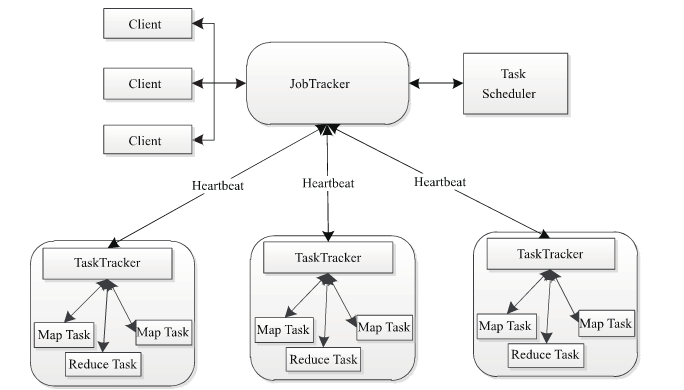
MapReduce包含四个组成部分,分别为Client,JobTracker,TaskTracker,Task
1. client客户端
每一个Job都会在用户端通过Client类将应用程序以及配置信息Configuration打包成Jar文件上传到HDFS,并把路径提交到JobTracker的master服务,然后由master创建每一个Task(即MapTask和ReduceTask),将它们分发到各个TaskTracker服务中去执行。
2. JobTracker
JobTracker负责资源监控和作业调度。JobTracker监控所有的TaskTracker与Job的健康状态,一旦发现失败,就将相应的任务转移到其他节点;同时JobTracker会跟踪任务的执行进度,资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。在Hadoop中,任务调度器是一个可插拔的模块,用于可以根据自己的需要设计相应的调度器。
TaskTracker
TaskTracker是运行在多个节点上的slave服务。TaskTracker主动与JobTracker通信(与DataNode和NameNode相似,通过心跳来实现),会周期性地将本节点上资源使用情况和任务的运行进度汇报给JobTracker,同时执行JobTracker发送过来的命令并执行相应的操作(如启动新任务,杀死任务等)。TaskTracker使用"slot"等量划分本节点上的资源量。"slot"代表计算资源(cpu,内存等)。一个Task获取到一个slot之后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot分为MapSlot和ReduceSlot两种,分别提供MapTask和ReduceTask使用。TaskTracker通过slot数目(可配置参数)限定Task的并发度。
Task:
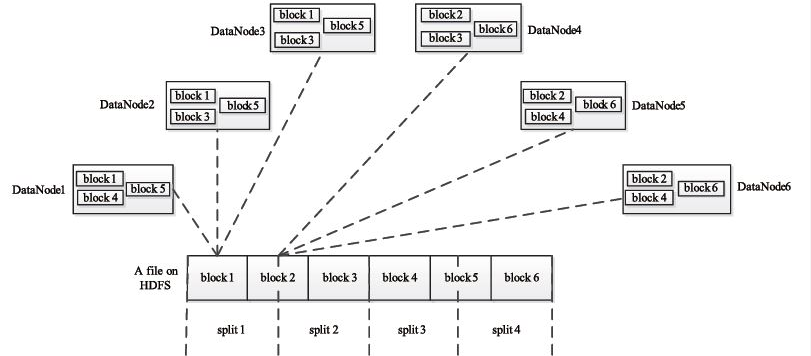
Task分为MapTask和ReduceTask两种,均由TaskTracker启动。HDFS以固定大小的block为基本单位存储数据,而对于MapReduce而言,其处理单位是split。split是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全有用户自己决定。但需要注意的是,split的多少决定了MapTask的数目,因为每一个split只会交给一个MapTask处理。spilt与block的关系如下图:
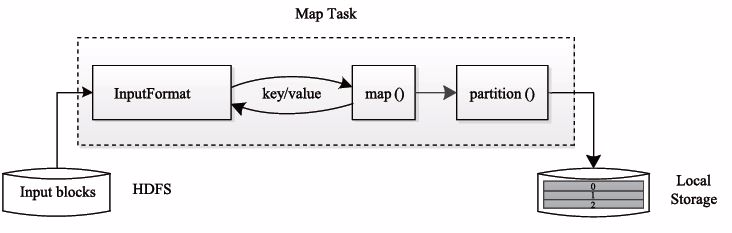
MapTask的执行过程如下图所示:由下图可知,Map Task先将对应的split迭代解析成一个key-value对,依次调用用户定义的map()函数进行处理,最终将临时结果存放到本地磁盘上。其中,临时数据被分成若干个partition,每个partition将被一个Reduce Task处理。
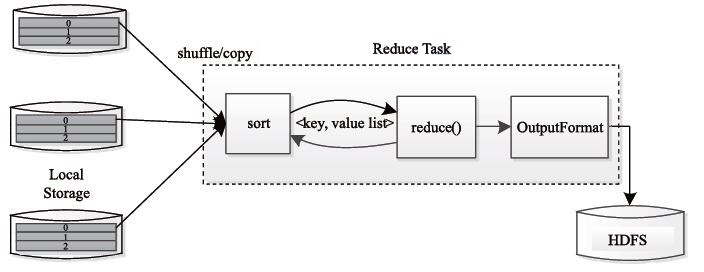
ReduceTask的执行过程如下图所示。该过程分为三个阶段:
- 从运程节点上读取Map Task中间结果(称为"Shuffle阶段")
- 按照Key对Key-Value对进行排序(称为"Sort阶段")
- 依次读取<key,value list>,调用用户自定义的Reduce函数处理,并将最终结果存到HDFS上(称为"Reduce阶段")
过程如下图:
MapReduce框架组成的更多相关文章
- Hadoop 之 MapReduce 框架演变详解
经典版的MapReduce 所谓的经典版本的MapReduce框架,也是Hadoop第一版成熟的商用框架,简单易用是它的特点,来看一幅图架构图: 上面的这幅图我们暂且可以称谓Hadoop的V1.0版本 ...
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop学习笔记:MapReduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- 更快、更强——解析Hadoop新一代MapReduce框架Yarn(CSDN)
摘要:本文介绍了Hadoop 自0.23.0版本后新的MapReduce框架(Yarn)原理.优势.运作机制和配置方法等:着重介绍新的Yarn框架相对于原框架的差异及改进. 编者按:对于业界的大数据存 ...
- 提升资源利用率的MapReduce框架
Hadoop系统提供了MapReduce计算框架的开源实现,像Yahoo!.Facebook.淘宝.中移动.百度.腾讯等公司都在借助 Hadoop进行海量数据处理.Hadoop系统性能不仅取决于任务调 ...
- Hadoop 新 MapReduce 框架 Yarn 详解
Hadoop 新 MapReduce 框架 Yarn 详解: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ Ap ...
- mapreduce框架详解【转载】
[本文转载自:http://www.cnblogs.com/sharpxiajun/p/3151395.html] 开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoo ...
- mapreduce框架详解
hadoop 学习笔记:mapreduce框架详解 开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感 ...
- MapReduce框架Hadoop应用(一)
Google对其的定义:MapReduce是一种变成模型,用于大规模数据集(以T为级别的数据)的并行运算.用户定义一个map函数来处理一批Key-Value对以生成另一批中间的Key-Value对,再 ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
随机推荐
- bzoj2724: [Violet 6]蒲公英(离散化+分块)
我好弱啊..这题调了2天QwQ 题目大意:给定一个长度为n(n<=40000)的序列,m(m<=50000)次询问l~r之间出现次数最多的数.(区间众数) 这题如果用主席树就可以不用处理一 ...
- Eclipse中 properties 文件中 中文乱码
在.properties文件写注释时,发现中文乱码了,由于之前在idea中有见设置.properties文件的编码类型,便找了找乱码原因 在中文操作系统中,Eclipse中的Java类型文件的编码的默 ...
- VC对话框实现添加滚动条实现滚动效果
对话框滚动条及滚动效果实现,用的api主要有: ScrollWindow, SetScrollInfo, GetScrollInfo, SetWindowOrgEx.涉及的数据结构为SCROLLINF ...
- react+propTypes
React.createClass({ propTypes: { // 可以声明 prop 为指定的 JS 基本数据类型,默认情况,这些数据是可选的 optionalArray: React.Prop ...
- 图论:Floyd-多源最短路、无向图最小环
在最短路问题中,如果我们面对的是稠密图(十分稠密的那种,比如说全连接图),计算多源最短路的时候,Floyd算法才能充分发挥它的优势,彻彻底底打败SPFA和Dijkstra 在别的最短路问题中都不推荐使 ...
- Codeforces 617E XOR and Favorite Number莫队
http://codeforces.com/contest/617/problem/E 题意:给出q个查询,每次询问区间内连续异或值为k的有几种情况. 思路:没有区间修改,而且扩展端点,减小端点在前缀 ...
- Enterprise Architect 13 : 需求建模 自动命名并计数
如何给模型中的需求元素配置计数器以自动设置新创建元素的名称和别名: Configure -> Settings -> Auto Names and Counters 设置好后的效果图:
- 解决Sourcetree 每次拉取提交都需要输入密码
问题产生背景 客户端领导决定使用http方式拉取和push代码,所以无法使用之前的ssh方式做免密处理 解决办法 方法1:在.git目录中有个config目录,在路径前配置下用户名和密码即可,如下所示 ...
- jsp 内置对象(一)
一.jsp的九大内置对象 内置对象 所属类 pageContext javax.servlet.jsp.PageContext request javax.servlet.http.HttpServl ...
- Linux系统文件权限体系详解
准备工作:先简单了解Linux文件权限 在Linux系统中,ls -l 命令可以查看文件的权限,如 [zhaohuizhen@localhost Test]$ ls -l a -rw-rw-r--. ...