AlexNet神经网络结构
Alexnet是2014年Imagenet竞赛的冠军模型,准确率达到了57.1%, top-5识别率达到80.2%。
AlexNet包含5个卷积层和3个全连接层,模型示意图:

精简版结构:
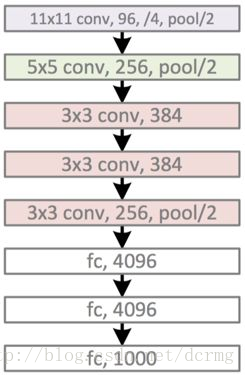
conv1阶段
输入数据:227×227×3
卷积核:11×11×3;步长:4;数量(也就是输出个数):96
卷积后数据:55×55×96 (原图N×N,卷积核大小n×n,卷积步长大于1为k,输出维度是(N-n)/k+1)
relu1后的数据:55×55×96
Max pool1的核:3×3,步长:2
Max pool1后的数据:27×27×96
norm1:local_size=5 (LRN(Local Response Normalization) 局部响应归一化)
最后的输出:27×27×96
AlexNet采用了Relu激活函数,取代了之前经常使用的S函数和T函数,Relu函数也很简单:
ReLU(x) = max(x,0)
AlexNet另一个创新是LRN(Local Response Normalization) 局部响应归一化,LRN模拟神经生物学上一个叫做 侧抑制(lateral inhibitio)的功能,侧抑制指的是被激活的神经元会抑制相邻的神经元。LRN局部响应归一化借鉴侧抑制的思想实现局部抑制,使得响应比较大的值相对更大,提高了模型的泛化能力。
LRN只对数据相邻区域做归一化处理,不改变数据的大小和维度。
LRN概念是在AlexNet模型中首次提出,在GoogLenet中也有应用,但是LRN的实际作用存在争议,如在2015年Very Deep Convolutional Networks for Large-Scale Image Recognition 论文中指出LRN基本没什么用。
AlexNet还应用了Overlapping(重叠池化),重叠池化就是池化操作在部分像素上有重合。池化核大小是n×n,步长是k,如果k=n,则是正常池化,如果 k<n, 则是重叠池化。官方文档中说明,重叠池化的运用减少了top-5和top-1错误率的0.4%和0.3%。重叠池化有避免过拟合的作用。
conv2阶段
输入数据:27×27×96
卷积核:5×5;步长:1;数量(也就是输出个数):256
卷积后数据:27×27×256 (做了Same padding(相同补白),使得卷积后图像大小不变。)
relu2后的数据:27×27×256
Max pool2的核:3×3,步长:2
Max pool2后的数据:13×13×256 ((27-3)/2+1=13 )
norm2:local_size=5 (LRN(Local Response Normalization) 局部响应归一化)
最后的输出:13×13×256
在AlexNet的conv2中使用了same padding,保持了卷积后图像的宽高不缩小。
conv3阶段
输入数据:13×13×256
卷积核:3×3;步长:1;数量(也就是输出个数):384
卷积后数据:13×13×384 (做了Same padding(相同补白),使得卷积后图像大小不变。)
relu3后的数据:13×13×384
最后的输出:13×13×384
conv3层没有Max pool层和norm层
conv4阶段
输入数据:13×13×384
卷积核:3×3;步长:1;数量(也就是输出个数):384
卷积后数据:13×13×384 (做了Same padding(相同补白),使得卷积后图像大小不变。)
relu4后的数据:13×13×384
最后的输出:13×13×384
conv4层也没有Max pool层和norm层
conv5阶段
输入数据:13×13×384
卷积核:3×3;步长:1;数量(也就是输出个数):256
卷积后数据:13×13×256 (做了Same padding(相同补白),使得卷积后图像大小不变。)
relu5后的数据:13×13×256
Max pool5的核:3×3,步长:2
Max pool2后的数据:6×6×256 ((13-3)/2+1=6 )
最后的输出:6×6×256
conv5层有Max pool,没有norm层
fc6阶段
输入数据:6×6×256
全连接输出:4096×1
relu6后的数据:4096×1
drop out6后数据:4096×1
最后的输出:4096×1
AlexNet在fc6全连接层引入了drop out的功能。dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率(一般是50%,这种情况下随机生成的网络结构最多)将其暂时从网络中丢弃(保留其权值),不再对前向和反向传输的数据响应。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而相当于每一个mini-batch都在训练不同的网络,drop out可以有效防止模型过拟合,让网络泛化能力更强,同时由于减少了网络复杂度,加快了运算速度。还有一种观点认为drop
out有效的原因是对样本增加来噪声,变相增加了训练样本。
fc7阶段
输入数据:4096×1
全连接输出:4096×1
relu7后的数据:4096×1
drop out7后数据:4096×1
最后的输出:4096×1
fc8阶段
输入数据:4096×1
全连接输出:1000
fc8输出一千种分类的概率。
AlexNet与在其之前的神经网络相比改进:
1. 数据增广(Data Augmentation增强)
常用的数据增强的方法有 水平翻转、随机裁剪、平移变换、颜色、光照、对比度变换
2. Dropout
有效防止过拟合。
3. Relu激活函数
用ReLU代替了传统的S或者T激活函数。
4. Local Response Normalization 局部响应归一化
参考了生物学上神经网络的侧抑制的功能,做了临近数据归一化,提高来模型的泛化能力,这一功能的作用有争议。
5. Overlapping Pooling 重叠池化
重叠池化减少了系统的过拟合,减少了top-5和top-1错误率的0.4%和0.3%。
6. 多GPU并行训练
AlexNet将网络分成了上下两部分,两部分的结构完全一致,这两部分由两块不同的GPU来训练,提高了训练速度。AlexNet大约有6000万个参数。
AlexNet神经网络结构的更多相关文章
- 深度神经网络结构以及Pre-Training的理解
Logistic回归.传统多层神经网络 1.1 线性回归.线性神经网络.Logistic/Softmax回归 线性回归是用于数据拟合的常规手段,其任务是优化目标函数:$h(\theta )=\thet ...
- GoogLeNet 神经网络结构
GoogLeNet是2014年 ILSVRC 冠军模型,top-5 错误率 6.7% ,GoogLeNet做了更大胆的网络上的尝试而不像vgg继承了lenet以及alexnet的一些框架,该模型虽然有 ...
- 神经网络结构在命名实体识别(NER)中的应用
神经网络结构在命名实体识别(NER)中的应用 近年来,基于神经网络的深度学习方法在自然语言处理领域已经取得了不少进展.作为NLP领域的基础任务-命名实体识别(Named Entity Recognit ...
- Evolution of Image Classifiers,进化算法在神经网络结构搜索的首次尝试 | ICML 2017
论文提出使用进化算法来进行神经网络结构搜索,整体搜索逻辑十分简单,结合权重继承,搜索速度很快,从实验结果来看,搜索的网络准确率挺不错的.由于论文是个比较早期的想法,所以可以有很大的改进空间,后面的很大 ...
- CARS: 华为提出基于进化算法和权值共享的神经网络结构搜索,CIFAR-10上仅需单卡半天 | CVPR 2020
为了优化进化算法在神经网络结构搜索时候选网络训练过长的问题,参考ENAS和NSGA-III,论文提出连续进化结构搜索方法(continuous evolution architecture searc ...
- EAS:基于网络转换的神经网络结构搜索 | AAAI 2018
论文提出经济实惠且高效的神经网络结构搜索算法EAS,使用RL agent作为meta-controller,学习通过网络变换进行结构空间探索.从指定的网络开始,通过function-preservin ...
- 经典卷积神经网络结构——LeNet-5、AlexNet、VGG-16
经典卷积神经网络的结构一般满足如下表达式: 输出层 -> (卷积层+ -> 池化层?)+ -> 全连接层+ 上述公式中,“+”表示一个或者多个,“?”表示一个或者零个,如“卷积层+ ...
- CNN 卷积神经网络结构
cnn每一层会输出多个feature map, 每个Feature Map通过一种卷积滤波器提取输入的一种特征,每个feature map由多个神经元组成,假如某个feature map的shape是 ...
- 神经网络结构:DenseNet
论文地址:密集连接的卷积神经网络 博客地址(转载请引用):https://www.cnblogs.com/LXP-Never/p/13289045.html 前言 在计算机视觉还是音频领域,卷积神经网 ...
随机推荐
- HDU - 6406 Taotao Picks Apples (RMQ+dp+二分)
题意:N个高度为hi的果子,摘果子的个数是从位置1开始从左到右的严格递增子序列的个数.有M次操作,每次操作对初始序列修改位置p的果子高度为q.每次操作后输出修改后能摘到得数目. 分析:将序列分为左.右 ...
- HDU - 3488 Tour (KM最优匹配)
题意:对一个带权有向图,将所有点纳入一个或多个环中,且每个点只出现一次,求其所有环的路径之和最小值. 分析:每个点都只出现一次,那么换个思路想,每个点入度出度都为1.将一个点拆成两个点,一个作为入度点 ...
- SqlHelper简单实现(通过Expression和反射)2.特性和实体设计
对于需求中的不要暴露DataTable或DataSet,我想到了设计中常用的对象:实体(Entity),通过实体将数据库中的字段封装成类,这样做不仅使代码更有可读性,维护起来也很方便.同时我自定义了一 ...
- 新建Maven项目时出错:org.apache.maven.archiver.MavenArchiver.getManifest
新建Maven项目时出错:org.apache.maven.archiver.MavenArchiver.getManifest eclipse新建maven项目时,pom.xml文件第一行报错: o ...
- sublime text 3 配置在浏览器中快速预览
1.打开Sublime,在菜单栏找到 preferences->package control->输入install package,回车 2.在弹出的输入框里输入SideBarEnhan ...
- 【leetcode刷题笔记】Majority Element
Given an array of size n, find the majority element. The majority element is the element that appear ...
- Linux 设置中文编码
Linux 设置中文编码 1.测试是否存在字体列表 fc-list 2.安装字体列表包 yum -y install fontconfig 3.去win系统中找到拷贝字体文件. 路径:C:/Windo ...
- 20145235李涛《网络对抗》Exp7 网络欺诈技术防范
基础问题回答 通常在什么场景下容易受到DNS spoof攻击? 使用未知的公共wifi或者在不安全的局域网下容易受到DNS spoof攻击. 在日常生活工作中如何防范以上两攻击方法? 首先要提高防范意 ...
- IntelliJ Idea 常用功能及其快捷键总结(长期更新,纯手动)
基础功能总结 快捷键总结 全局搜索 CTRL SHIF F 局部搜索 CTRL F 替换 CTRL R 复制一行 CTRL D 剪切一行 CTRL X 行定位 CTRL G 文件重命名 SHIFT F ...
- window下安裝redis服務
一.下载windows版本的Redis github下载地址:https://github.com/MicrosoftArchive/redis/releases/tag/win-3.2.100 ...