Pandas分组运算(groupby)修炼
Pandas分组运算(groupby)修炼
Pandas的groupby()功能很强大,用好了可以方便的解决很多问题,在数据处理以及日常工作中经常能施展拳脚。
今天,我们一起来领略下groupby()的魅力吧。
首先,引入相关package:
import pandas as pd
import numpy as np
groupby的基础操作
In [2]: df = pd.DataFrame({'A': ['a', 'b', 'a', 'c', 'a', 'c', 'b', 'c'],
...: 'B': [2, 8, 1, 4, 3, 2, 5, 9],
...: 'C': [102, 98, 107, 104, 115, 87, 92, 123]})
...: df
...:
Out[2]:
A B C
0 a 2 102
1 b 8 98
2 a 1 107
3 c 4 104
4 a 3 115
5 c 2 87
6 b 5 92
7 c 9 123
按A列分组(groupby),获取其他列的均值
df.groupby('A').mean()
Out[3]:
B C
A
a 2.0 108.000000
b 6.5 95.000000
c 5.0 104.666667
按多列进行分组(groupby)
df.groupby(['A','B']).mean()
Out[4]:
C
A B
a 1 107
2 102
3 115
b 5 92
8 98
c 2 87
4 104
9 123
分组后选择列进行运算
分组后,可以选取单列数据,或者多个列组成的列表(list)进行运算
In [5]: df = pd.DataFrame([[1, 1, 2], [1, 2, 3], [2, 3, 4]], columns=["A", "B", "C"])
...: df
...:
Out[5]:
A B C
0 1 1 2
1 1 2 3
2 2 3 4
In [6]: g = df.groupby("A")
In [7]: g['B'].mean() # 仅选择B列
Out[7]:
A
1 1.5
2 3.0
Name: B, dtype: float64
In [8]: g[['B', 'C']].mean() # 选择B、C列
Out[8]:
B C
A
1 1.5 2.5
2 3.0 4.0
可以针对不同的列选用不同的聚合方法
In [9]: g.agg({'B':'mean', 'C':'sum'})
Out[9]:
B C
A
1 1.5 5
2 3.0 4
聚合方法size()和count()
size跟count的区别: size计数时包含NaN值,而count不包含NaN值
In [10]: df = pd.DataFrame({"Name":["Alice", "Bob", "Mallory", "Mallory", "Bob" , "Mallory"],
...: "City":["Seattle", "Seattle", "Portland", "Seattle", "Seattle", "Portland"],
...: "Val":[4,3,3,np.nan,np.nan,4]})
...:
...: df
...:
Out[10]:
City Name Val
0 Seattle Alice 4.0
1 Seattle Bob 3.0
2 Portland Mallory 3.0
3 Seattle Mallory NaN
4 Seattle Bob NaN
5 Portland Mallory 4.0
count()
In [11]: df.groupby(["Name", "City"], as_index=False)['Val'].count()
Out[11]:
Name City Val
0 Alice Seattle 1
1 Bob Seattle 1
2 Mallory Portland 2
3 Mallory Seattle 0
size()
In [12]: df.groupby(["Name", "City"])['Val'].size().reset_index(name='Size')
Out[12]:
Name City Size
0 Alice Seattle 1
1 Bob Seattle 2
2 Mallory Portland 2
3 Mallory Seattle 1
分组运算方法 agg()
针对某列使用agg()时进行不同的统计运算
In [13]: df = pd.DataFrame({'A': list('XYZXYZXYZX'), 'B': [1, 2, 1, 3, 1, 2, 3, 3, 1, 2],
...: 'C': [12, 14, 11, 12, 13, 14, 16, 12, 10, 19]})
...: df
...:
Out[13]:
A B C
0 X 1 12
1 Y 2 14
2 Z 1 11
3 X 3 12
4 Y 1 13
5 Z 2 14
6 X 3 16
7 Y 3 12
8 Z 1 10
9 X 2 19
In [14]: df.groupby('A')['B'].agg({'mean':np.mean, 'standard deviation': np.std})
Out[14]:
mean standard deviation
A
X 2.250000 0.957427
Y 2.000000 1.000000
Z 1.333333 0.577350
针对不同的列应用多种不同的统计方法
In [15]: df.groupby('A').agg({'B':[np.mean, 'sum'], 'C':['count',np.std]})
Out[15]:
B C
mean sum count std
A
X 2.250000 9 4 3.403430
Y 2.000000 6 3 1.000000
Z 1.333333 4 3 2.081666
分组运算方法 apply()
In [16]: df = pd.DataFrame({'A': list('XYZXYZXYZX'), 'B': [1, 2, 1, 3, 1, 2, 3, 3, 1, 2],
...: 'C': [12, 14, 11, 12, 13, 14, 16, 12, 10, 19]})
...: df
...:
Out[16]:
A B C
0 X 1 12
1 Y 2 14
2 Z 1 11
3 X 3 12
4 Y 1 13
5 Z 2 14
6 X 3 16
7 Y 3 12
8 Z 1 10
9 X 2 19
In [17]: df.groupby('A').apply(np.mean)
...: # 跟下面的方法的运行结果是一致的
...: # df.groupby('A').mean()
Out[17]:
B C
A
X 2.250000 14.750000
Y 2.000000 13.000000
Z 1.333333 11.666667
apply()方法可以应用lambda函数,举例如下:
In [18]: df.groupby('A').apply(lambda x: x['C']-x['B'])
Out[18]:
A
X 0 11
3 9
6 13
9 17
Y 1 12
4 12
7 9
Z 2 10
5 12
8 9
dtype: int64
In [19]: df.groupby('A').apply(lambda x: (x['C']-x['B']).mean())
Out[19]:
A
X 12.500000
Y 11.000000
Z 10.333333
dtype: float64
分组运算方法 transform()
前面进行聚合运算的时候,得到的结果是一个以分组名为 index 的结果对象。如果我们想使用原数组的 index 的话,就需要进行 merge 转换。transform(func, args, *kwargs) 方法简化了这个过程,它会把 func 参数应用到所有分组,然后把结果放置到原数组的 index 上(如果结果是一个标量,就进行广播):
In [20]: df = pd.DataFrame({'group1' : ['A', 'A', 'A', 'A',
...: 'B', 'B', 'B', 'B'],
...: 'group2' : ['C', 'C', 'C', 'D',
...: 'E', 'E', 'F', 'F'],
...: 'B' : ['one', np.NaN, np.NaN, np.NaN,
...: np.NaN, 'two', np.NaN, np.NaN],
...: 'C' : [np.NaN, 1, np.NaN, np.NaN,
...: np.NaN, np.NaN, np.NaN, 4]})
...: df
...:
Out[20]:
B C group1 group2
0 one NaN A C
1 NaN 1.0 A C
2 NaN NaN A C
3 NaN NaN A D
4 NaN NaN B E
5 two NaN B E
6 NaN NaN B F
7 NaN 4.0 B F
In [21]: df.groupby(['group1', 'group2'])['B'].transform('count')
Out[21]:
0 1
1 1
2 1
3 0
4 1
5 1
6 0
7 0
Name: B, dtype: int64
In [22]: df['count_B']=df.groupby(['group1', 'group2'])['B'].transform('count')
...: df
...:
Out[22]:
B C group1 group2 count_B
0 one NaN A C 1
1 NaN 1.0 A C 1
2 NaN NaN A C 1
3 NaN NaN A D 0
4 NaN NaN B E 1
5 two NaN B E 1
6 NaN NaN B F 0
7 NaN 4.0 B F 0
上面运算的结果分析: {‘group1’:’A’, ‘group2’:’C’}的组合共出现3次,即index为0,1,2。对应”B”列的值分别是”one”,”NaN”,”NaN”,由于count()计数时不包括Nan值,因此{‘group1’:’A’, ‘group2’:’C’}的count计数值为1。
transform()方法会将该计数值在dataframe中所有涉及的rows都显示出来(我理解应该就进行广播)
将某列数据按数据值分成不同范围段进行分组(groupby)运算
In [23]: np.random.seed(0)
...: df = pd.DataFrame({'Age': np.random.randint(20, 70, 100),
...: 'Sex': np.random.choice(['Male', 'Female'], 100),
...: 'number_of_foo': np.random.randint(1, 20, 100)})
...: df.head()
...:
Out[23]:
Age Sex number_of_foo
0 64 Female 14
1 67 Female 14
2 20 Female 12
3 23 Male 17
4 23 Female 15
这里将“Age”列分成三类,有两种方法可以实现:
(a)bins=4
(b)bins=[19, 40, 65, np.inf]
In [24]: pd.cut(df['Age'], bins=4)
Out[24]:
...
In [25]: pd.cut(df['Age'], bins=[19,40,65,np.inf])
分组结果范围结果如下:

In [26]: age_groups = pd.cut(df['Age'], bins=[19,40,65,np.inf])
...: df.groupby(age_groups).mean()
运行结果如下:

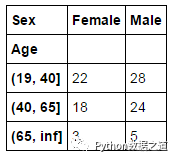
按‘Age’分组范围和性别(sex)进行制作交叉表
In [27]: pd.crosstab(age_groups, df['Sex'])
运行结果如下:
参考文章:http://stackoverflow.com/documentation/pandas/1822/grouping-data#t=201705040520188108539
更多精彩内容请关注公众号:
“Python数据之道”
Pandas分组运算(groupby)修炼的更多相关文章
- pandas聚合和分组运算——GroupBy技术(1)
数据聚合与分组运算——GroupBy技术(1),有需要的朋友可以参考下. pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片.切块.摘要等操作.根据一个或多个 ...
- Pandas分组(GroupBy)
任何分组(groupby)操作都涉及原始对象的以下操作之一.它们是 - 分割对象 应用一个函数 结合的结果 在许多情况下,我们将数据分成多个集合,并在每个子集上应用一些函数.在应用函数中,可以执行以下 ...
- pandas分组运算(groupby)
1. groupby() import pandas as pd df = pd.DataFrame([[1, 1, 2], [1, 2, 3], [2, 3, 4]], columns=[" ...
- pandas学习(数据分组与分组运算、离散化处理、数据合并)
pandas学习(数据分组与分组运算.离散化处理.数据合并) 目录 数据分组与分组运算 离散化处理 数据合并 数据分组与分组运算 GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表 ...
- 【学习】数据聚合和分组运算【groupby】
分组键可以有多种方式,且类型不必相同 列表或数组, 某长度与待分组的轴一样 表示DataFrame某个列名的值 字典或Series,给出待分组轴上的值与分组名之间的对应关系 函数用于处理轴索引或索引中 ...
- Python数据聚合和分组运算(1)-GroupBy Mechanics
前言 Python的pandas包提供的数据聚合与分组运算功能很强大,也很灵活.<Python for Data Analysis>这本书第9章详细的介绍了这方面的用法,但是有些细节不常用 ...
- python库学习笔记——分组计算利器:pandas中的groupby技术
最近处理数据需要分组计算,又用到了groupby函数,温故而知新. 分组运算的第一阶段,pandas 对象(无论是 Series.DataFrame 还是其他的)中的数据会根据你所提供的一个或多个键被 ...
- 利用Python进行数据分析-Pandas(第六部分-数据聚合与分组运算)
对数据集进行分组并对各组应用一个函数(无论是聚合还是转换),通常是数据分析工作中的重要环节.在将数据集加载.融合.准备好之后,通常是计算分组统计或生成透视表.pandas提供了一个灵活高效的group ...
- python中pandas数据分析基础3(数据索引、数据分组与分组运算、数据离散化、数据合并)
//2019.07.19/20 python中pandas数据分析基础(数据重塑与轴向转化.数据分组与分组运算.离散化处理.多数据文件合并操作) 3.1 数据重塑与轴向转换1.层次化索引使得一个轴上拥 ...
随机推荐
- JMeter 保持sessionId
因项目需要,这几天用到了jmeter进行性能测试,测试的是一个管理系统,需要用户先登录,然后才能做操作的,其中就遇到了关于session的问题. 我使用的是badboy(版本2.1)进行的脚本录制,然 ...
- 验证组件——FluentValidation
FluentValidation FluentValidation是与ASP.NET DataAnnotataion Attribute验证实体不同的数据验证组件,提供了将实体与验证分离开 ...
- Robot Framework Change chrome language
由于open browser的参数只有一个ff_profile_dir,所以不能指定chrome profile. 只能通过python 传递lang这个参数去改变语言. python: from s ...
- uva10766生成树计数(矩阵树定理)
更正了我之前打错的地方,有边的话G[i][j]=-1; WA了好多次,中间要转成long double才行..这个晚点更新. #include<cstdio> #include<cs ...
- jQuery操作Table学习总结[转]
<style type="text/css"> .hover { } </style>< ...
- bzoj 2440 容斥原理
首先根据样例或者自己打表大概可以知道,对于询问k,答案不会超过k<<1,那么我们就可以二分答案,求当前二分的值内有多少个数不是完全平方数的倍数,这样就可以了,对于每个二分到的值x,其中完全 ...
- poj 2387 Til the Cows Come Home(dijkstra算法)
题目链接:http://poj.org/problem?id=2387 题目大意:起点一定是1,终点给出,然后求出1到所给点的最短路径. 注意的是先输入边,在输入的顶点数,不要弄反哦~~~ #incl ...
- tensorflow常用函数解析
一.tf.transpose函数的用法 tf.transpose(input, [dimension_1, dimenaion_2,..,dimension_n]):这个函数主要适用于交换输入张量的不 ...
- ImportError: libQtTest.so.4: cannot open shared
错误: import cv2 File , in <module> from .cv2 import * ImportError: libQtTest.so.: cannot open s ...
- Java 关于微信公众号支付总结附代码
很多朋友第一次做微信支付的时候都有蒙,但当你完整的做一次就会发现其实并没有那么难 业务流程和应用场景官网有详细的说明:https://pay.weixin.qq.com/wiki/doc/api/js ...