python实现简单爬虫功能
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。
我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度。好吧~!其实你很厉害的,右键查看页面源代码。
我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的代码爬取到本地。下面就看看如何使用python来实现这样一个功能。
一,获取整个页面数据
首先我们可以先获取要下载图片的整个页面信息。
getjpg.py

#coding=utf-8
import urllib def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html html = getHtml("http://tieba.baidu.com/p/2738151262") print html
Urllib 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据。首先,我们定义了一个getHtml()函数:
urllib.urlopen()方法用于打开一个URL地址。
read()方法用于读取URL上的数据,向getHtml()函数传递一个网址,并把整个页面下载下来。执行程序就会把整个网页打印输出。
二,筛选页面中想要的数据
Python 提供了非常强大的正则表达式,我们需要先要了解一点python 正则表达式的知识才行。
http://www.cnblogs.com/fnng/archive/2013/05/20/3089816.html
假如我们百度贴吧找到了几张漂亮的壁纸,通过到前段查看工具。找到了图片的地址,如:src=”http://imgsrc.baidu.com/forum......jpg”pic_ext=”jpeg”
修改代码如下:
import re
import urllib def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
return imglist html = getHtml("http://tieba.baidu.com/p/2460150866")
print getImg(html)
我们又创建了getImg()函数,用于在获取的整个页面中筛选需要的图片连接。re模块主要包含了正则表达式:
re.compile() 可以把正则表达式编译成一个正则表达式对象.
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
运行脚本将得到整个页面中包含图片的URL地址。
三,将页面筛选的数据保存到本地
把筛选的图片地址通过for循环遍历并保存到本地,代码如下:
#coding=utf-8
import urllib
import re def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1 html = getHtml("http://tieba.baidu.com/p/2460150866") print getImg(html)
这里的核心是用到了urllib.urlretrieve()方法,直接将远程数据下载到本地。
通过一个for循环对获取的图片连接进行遍历,为了使图片的文件名看上去更规范,对其进行重命名,命名规则通过x变量加1。保存的位置默认为程序的存放目录。
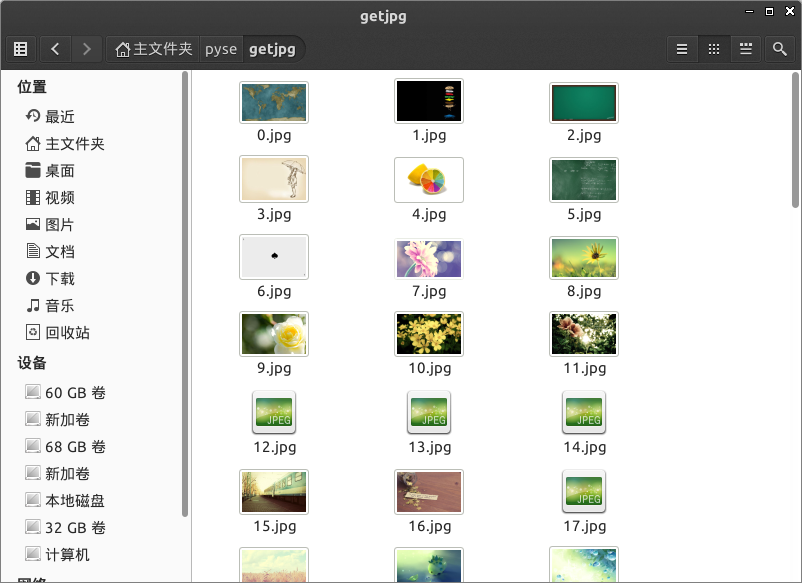
程序运行完成,将在目录下看到下载到本地的文件。
转自:http://www.cnblogs.com/fnng/p/3576154.html
python实现简单爬虫功能的更多相关文章
- python3实现简单爬虫功能
本文参考虫师python2实现简单爬虫功能,并增加自己的感悟. #coding=utf-8 import re import urllib.request def getHtml(url): page ...
- Python开发简单爬虫 - 慕课网
课程链接:Python开发简单爬虫 环境搭建: Eclipse+PyDev配置搭建Python开发环境 Python入门基础教程 用Eclipse编写Python程序 课程目录 第1章 课程介绍 ...
- [python爬虫]简单爬虫功能
在我们日常上网浏览网页的时候,经常会看到某个网站中一些好看的图片,它们可能存在在很多页面当中,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材. 我们最常规的做法就是通过鼠标 ...
- Python做简单爬虫(urllib.request怎么抓取https以及伪装浏览器访问的方法)
一:抓取简单的页面: 用Python来做爬虫抓取网站这个功能很强大,今天试着抓取了一下百度的首页,很成功,来看一下步骤吧 首先需要准备工具: 1.python:自己比较喜欢用新的东西,所以用的是Pyt ...
- python实现简单爬虫抓取图片
最近在学习python,正如大家所知,python在网络爬虫方面有着广泛的应用,下面是一个利用python程序抓取网络图片的简单程序,可以批量下载一个网站更新的图片,其中使用了代理IP的技术. imp ...
- Python开发简单爬虫(一)
一 .简单爬虫架构: 爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况 URL管理器:对将要爬取的和已经爬取过的URL进行管理:可取出带爬取的URL,将其传送给“网页下载器” 网页下载器:将URL指定 ...
- Python开发简单爬虫
简单爬虫框架: 爬虫调度器 -> URL管理器 -> 网页下载器(urllib2) -> 网页解析器(BeautifulSoup) -> 价值数据 Demo1: # codin ...
- 教你如何入手用python实现简单爬虫微信公众号并下载视频
主要功能 如何简单爬虫微信公众号 获取信息:标题.摘要.封面.文章地址 自动批量下载公众号内的视频 一.获取公众号信息:标题.摘要.封面.文章URL 操作步骤: 1.先自己申请一个公众号 2.登录自己 ...
- python多线程简单爬虫
爬虫本质就是将网站或者接口的数据经过筛选后按需求保存 这里实现一个简单爬虫仅供参考 import requests import bs4 import threading import queue i ...
随机推荐
- Mysql binlog 安全删除
简介: 如果你的 Mysql 搭建了主从同步 , 或者数据库开启了 log-bin 日志 , 那么随着时间的推移 , 你的数据库 data 目录下会产生大量的日志文件 shell > ll /u ...
- 遍历list、set、map和array
public static void main(String[] args) { /*1. List*/ ArrayList<Integer> list = new ArrayList&l ...
- nginx+fastcgi+c/cpp
参考:http://github.tiankonguse.com/blog/2015/01/19/cgi-nginx-three/ 跟着做了一遍,然后根据记忆写的,不清楚有没错漏步骤,希望多多评论多多 ...
- [Android] charles高级使用总结
reference to : http://blog.csdn.net/a910626/article/details/52823981 charles高级使用总结 网速模拟 点击菜单“Proxy→T ...
- CSS3简易表盘时钟
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 网站添加第三方登陆(PHP版)
这两周正在写毕业设计,我做的是一个问答网站.先介绍一下这个网站:这是一个关于大学生在线问答的网站,类似知乎和百度知道,不过功能没有人家多,毕竟这个网站我一个人在做.网站部署在阿里云,网站包括API,W ...
- node.js express架构安装部署
安装-g:表示全局安装(必须以安装node.js) npm install -g express-generator 创建一个express架构的项目文件夹express testWebApp 在pa ...
- win7 下安装RVCT
由于项目的需求,需要使用RVCT 3.1: 一看此包的发布日期,老的吓人,但没办法,只能硬着头皮安装: 环境:WIN7 安装软件RVCT 3.1 build 569 license:由于需要编译的代码 ...
- UWP 判断windows mobile是使用的实体键还是虚拟按键
最近在写启动屏幕,发现虚拟按钮会挡住,启动屏幕的最下面的元素,大概有50 px.可是有什么办法知道手机是用的实体键还是虚拟按键吗? 如下图.可以看到红色的部分显示了一点点.代码里设置的是60px. 在 ...
- AC自动机专题
AC自动机简介:KMP是用于解决单模式串匹配问题, AC自动机用于解决多模式串匹配问题. 精华:设这个节点上的字母为C,沿着他父亲的失败指针走,直到走到一个节点,他的儿子中也有字母为C的节点.然后把当 ...