python实现简单爬虫功能
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。
我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度。好吧~!其实你很厉害的,右键查看页面源代码。
我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的代码爬取到本地。下面就看看如何使用python来实现这样一个功能。
一,获取整个页面数据
首先我们可以先获取要下载图片的整个页面信息。
getjpg.py

#coding=utf-8
import urllib def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html html = getHtml("http://tieba.baidu.com/p/2738151262") print html
Urllib 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据。首先,我们定义了一个getHtml()函数:
urllib.urlopen()方法用于打开一个URL地址。
read()方法用于读取URL上的数据,向getHtml()函数传递一个网址,并把整个页面下载下来。执行程序就会把整个网页打印输出。
二,筛选页面中想要的数据
Python 提供了非常强大的正则表达式,我们需要先要了解一点python 正则表达式的知识才行。
http://www.cnblogs.com/fnng/archive/2013/05/20/3089816.html
假如我们百度贴吧找到了几张漂亮的壁纸,通过到前段查看工具。找到了图片的地址,如:src=”http://imgsrc.baidu.com/forum......jpg”pic_ext=”jpeg”
修改代码如下:
import re
import urllib def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
return imglist html = getHtml("http://tieba.baidu.com/p/2460150866")
print getImg(html)
我们又创建了getImg()函数,用于在获取的整个页面中筛选需要的图片连接。re模块主要包含了正则表达式:
re.compile() 可以把正则表达式编译成一个正则表达式对象.
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
运行脚本将得到整个页面中包含图片的URL地址。
三,将页面筛选的数据保存到本地
把筛选的图片地址通过for循环遍历并保存到本地,代码如下:
#coding=utf-8
import urllib
import re def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1 html = getHtml("http://tieba.baidu.com/p/2460150866") print getImg(html)
这里的核心是用到了urllib.urlretrieve()方法,直接将远程数据下载到本地。
通过一个for循环对获取的图片连接进行遍历,为了使图片的文件名看上去更规范,对其进行重命名,命名规则通过x变量加1。保存的位置默认为程序的存放目录。
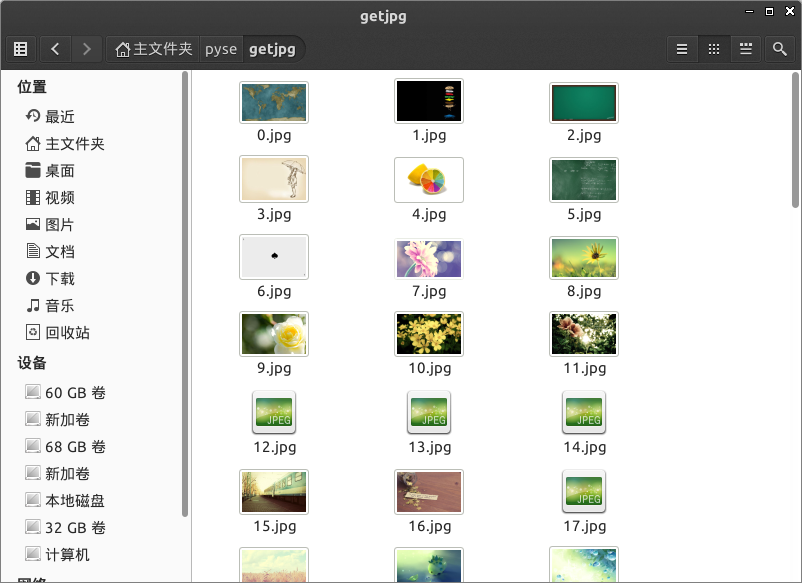
程序运行完成,将在目录下看到下载到本地的文件。
转自:http://www.cnblogs.com/fnng/p/3576154.html
python实现简单爬虫功能的更多相关文章
- python3实现简单爬虫功能
本文参考虫师python2实现简单爬虫功能,并增加自己的感悟. #coding=utf-8 import re import urllib.request def getHtml(url): page ...
- Python开发简单爬虫 - 慕课网
课程链接:Python开发简单爬虫 环境搭建: Eclipse+PyDev配置搭建Python开发环境 Python入门基础教程 用Eclipse编写Python程序 课程目录 第1章 课程介绍 ...
- [python爬虫]简单爬虫功能
在我们日常上网浏览网页的时候,经常会看到某个网站中一些好看的图片,它们可能存在在很多页面当中,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材. 我们最常规的做法就是通过鼠标 ...
- Python做简单爬虫(urllib.request怎么抓取https以及伪装浏览器访问的方法)
一:抓取简单的页面: 用Python来做爬虫抓取网站这个功能很强大,今天试着抓取了一下百度的首页,很成功,来看一下步骤吧 首先需要准备工具: 1.python:自己比较喜欢用新的东西,所以用的是Pyt ...
- python实现简单爬虫抓取图片
最近在学习python,正如大家所知,python在网络爬虫方面有着广泛的应用,下面是一个利用python程序抓取网络图片的简单程序,可以批量下载一个网站更新的图片,其中使用了代理IP的技术. imp ...
- Python开发简单爬虫(一)
一 .简单爬虫架构: 爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况 URL管理器:对将要爬取的和已经爬取过的URL进行管理:可取出带爬取的URL,将其传送给“网页下载器” 网页下载器:将URL指定 ...
- Python开发简单爬虫
简单爬虫框架: 爬虫调度器 -> URL管理器 -> 网页下载器(urllib2) -> 网页解析器(BeautifulSoup) -> 价值数据 Demo1: # codin ...
- 教你如何入手用python实现简单爬虫微信公众号并下载视频
主要功能 如何简单爬虫微信公众号 获取信息:标题.摘要.封面.文章地址 自动批量下载公众号内的视频 一.获取公众号信息:标题.摘要.封面.文章URL 操作步骤: 1.先自己申请一个公众号 2.登录自己 ...
- python多线程简单爬虫
爬虫本质就是将网站或者接口的数据经过筛选后按需求保存 这里实现一个简单爬虫仅供参考 import requests import bs4 import threading import queue i ...
随机推荐
- $q -- AngularJS中的服务(理解)
描述 译者注: 看到了一篇非常好的文章,如果你有兴趣,可以查看: Promises与Javascript异步编程 , 里面对Promises规范和使用情景,好处讲的非常好透彻,个人觉得简单易懂. ...
- ThinkPHP3.2.3多文件上传,文件丢失问题的解决
描述 thinkphp多文件上传时,有些时候会出现文件丢失的情况.比如上传多个图片,最终只上传了一个图片.本地测试的时候是正常的,但上传到服务器上就会出现丢失文件这种情况. 原因 查看tp上传类(Th ...
- eclipse逐步调试
Eclipse 的单步调试 1.设置断点在程序里面放置一个断点,也就是双击需要放置断点的程序左边的栏目上.2.调试(1)点击"打开透视图"按钮,选择调试透视图,则打开调试透视图界面 ...
- centos6安装php5.4以上版本
1.检查当前安装的PHP包 yum list installed | grep php 如果有安装的PHP包,先删除他们 yum remove php.x86_64 php-cli.x86_64 p ...
- ACM/ICPC 之 计算几何入门-叉积-to left test(POJ2318-POJ2398)
POJ2318 本题需要运用to left test不断判断点处于哪个分区,并统计分区的点个数(保证点不在边界和界外),用来做叉积入门题很合适 //计算几何-叉积入门题 //Time:157Ms Me ...
- MySQL索引背后的数据结构及算法原理【转】
本文来自:张洋的MySQL索引背后的数据结构及算法原理 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持 ...
- Python 小爬虫流程总结
接触Python3一个月了,在此分享一下知识点,也算是温故而知新了. 接触python之前是做前端的.一直希望接触面能深一点.因工作需求开始学python,几乎做的都是爬虫..第一个demo就是爬取X ...
- 如何去掉MyEclipse中的空格符,回车符?
我前几天不小心把空格符合回车符显示了出来,如图: 天啊,看了两天以后,我感觉整个人都不行了,眼花缭乱,于是就各种尝试,想要去掉,就有了如下方法,其实很简单 在eclipse中的菜单的 window-& ...
- PEtools
// PETools.cpp : Defines the entry point for the console application.// #include "stdafx.h" ...
- A Game(洛谷 2734)
题目背景 有如下一个双人游戏:N(2 <= N <= 100)个正整数的序列放在一个游戏平台上,游戏由玩家1开始,两人轮流从序列的任意一端取一个数,取数后该数字被去掉并累加到本玩家的得分中 ...