深入解析Dropout
过拟合是深度神经网(DNN)中的一个常见问题:模型只学会在训练集上分类,这些年提出的许多过拟合问题的解决方案;其中dropout具有简单性并取得良好的结果:
Dropout
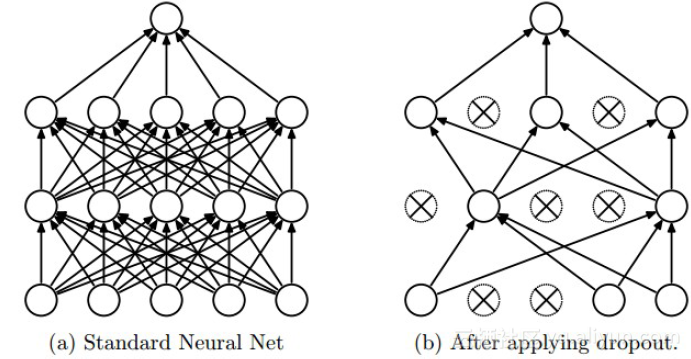
上图为Dropout的可视化表示,左边是应用Dropout之前的网络,右边是应用了Dropout的同一个网络。
Dropout的思想是训练整体DNN,并平均整个集合的结果,而不是训练单个DNN。DNNs是以概率P舍弃部分神经元,其它神经元以概率q=1-p被保留,舍去的神经元的输出都被设置为零。
引述作者:
在标准神经网络中,每个参数的导数告诉其应该如何改变,以致损失函数最后被减少。因此神经元元可以通过这种方式修正其他单元的错误。但这可能导致复杂的协调,反过来导致过拟合,因为这些协调没有推广到未知数据。Dropout通过使其他隐藏单元存在不可靠性来防止共拟合。
简而言之:Dropout在实践中能很好工作是因为其在训练阶段阻止神经元的共适应。
Dropout如何工作
Dropout以概率p舍弃神经元并让其它神经元以概率q=1-p保留。每个神经元被关闭的概率是相同的。这意味着:
假设:
h(x)=xW+b,di维的输入x在dh维输出空间上的线性投影;
a(h)是激活函数
在训练阶段中,将假设的投影作为修改的激活函数:
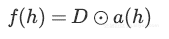
其中D=(X1,...,Xdh)是dh维的伯努利变量Xi,伯努利随机变量具有以下概率质量分布:
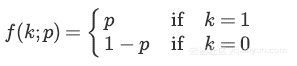
其中k是可能的输出。
将Dropout应用在第i个神经元上:
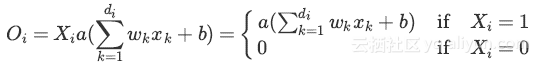
其中P(Xi=0)=p
由于在训练阶段神经元保持q概率,在测试阶段必须仿真出在训练阶段使用的网络集的行为。
为此,作者建议通过系数q来缩放激活函数:
训练阶段: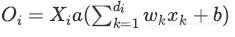
测试阶段: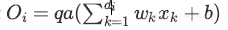
Inverted Dropout
与dropout稍微不同。该方法在训练阶段期间对激活值进行缩放,而测试阶段保持不变。
倒数Dropout的比例因子为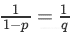 ,因此:
,因此:
训练阶段: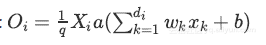
测试阶段: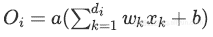
Inverted Dropout是Dropout在各种深度学习框架实践中实现的,因为它有助于一次性定义模型,并只需更改参数(保持/舍弃概率)就可以在同一模型上运行训练和测试过程。
一组神经元的Dropout
n个神经元的第h层在每个训练步骤中可以被看作是n个伯努利实验的集合,每个成功的概率等于p。
因此舍弃部分神经元后h层的输出等于:
因为每一个神经元建模为伯努利随机变量,且所有这些随机变量是独立同分布的,舍去神经元的总数也是随机变量,称为二项式:
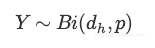
n次尝试中有k次成功的概率由概率质量分布给出:
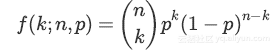
当使用dropout时,定义了一个固定的舍去概率p,对于选定的层,成比例数量的神经元被舍弃。
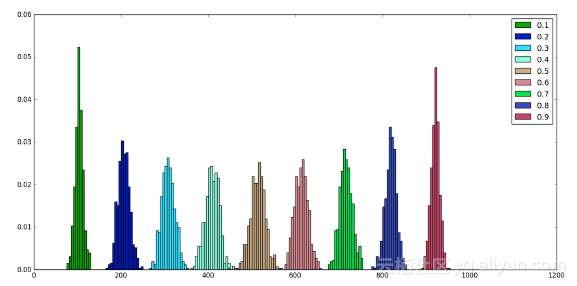
从上图可以看出,无论p值是多少,舍去的平均神经元数量均衡为np:
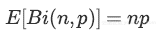
此外可以注意到,围绕在p = 0.5值附近的分布是对称。
Dropout与其它正则化
Dropout通常使用L2归一化以及其他参数约束技术。正则化有助于保持较小的模型参数值。
L2归一化是损失的附加项,其中λ是一种超参数、F(W;x)是模型以及ε是真值y与和预测值y^之间的误差函数。
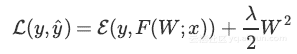
通过梯度下降进行反向传播,减少了更新数量。
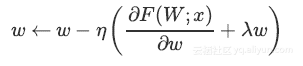
Inverted Dropout和其他正则化
由于Dropout不会阻止参数增长和彼此压制,应用L2正则化可以起到作用。
明确缩放因子后,上述等式变为:
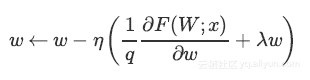
可以看出使用Inverted Dropout,学习率是由因子q进行缩放 。由于q在[0,1]之间,η和q之间的比例变化:
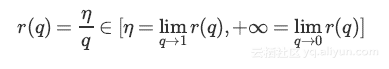
将q称为推动因素,因为其能增强学习速率,将r(q)称为有效的学习速率。
有效学习速率相对于所选的学习速率而言更高:基于此约束参数值的规一化可以帮助简化学习速率选择过程。
总结
1 Dropout存在两个版本:直接(不常用)和反转
2 单个神经元上的dropout可以使用伯努利随机变量建模
3 可以使用二项式随机变量来对一组神经元上的舍弃进行建模
4 即使舍弃神经元恰巧为np的概率是低的,但平均上np个神经元被舍弃。
5 Inverted Dropout提高学习率
6 Inverted Dropout应该与限制参数值的其他归一化技术一起使用,以便简化学习速率选择过程
7 Dropout有助于防止深层神经网络中的过度拟合
深入解析Dropout的更多相关文章
- 深入解析Dropout——基本思想:以概率P舍弃部分神经元,其它神经元以概率q=1-p被保留,舍去的神经元的输出都被设置为零
深度学习网络大杀器之Dropout——深入解析Dropout 转自:https://yq.aliyun.com/articles/68901 摘要: 本文详细介绍了深度学习中dropout技巧的思想 ...
- 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
- Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象.在训练神经网络的时候经常会遇到过拟合的问题, ...
- Hebye 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
- Theano:LSTM源码解析
最难读的Theano代码 这份LSTM代码的作者,感觉和前面Tutorial代码作者不是同一个人.对于Theano.Python的手法使用得非常娴熟. 尤其是在两重并行设计上: ①LSTM各个门之间并 ...
- Tensorflow的CNN教程解析
之前的博客我们已经对RNN模型有了个粗略的了解.作为一个时序性模型,RNN的强大不需要我在这里重复了.今天,让我们来看看除了RNN外另一个特殊的,同时也是广为人知的强大的神经网络模型,即CNN模型.今 ...
- 解析Tensorflow官方PTB模型的demo
RNN 模型作为一个可以学习时间序列的模型被认为是深度学习中比较重要的一类模型.在Tensorflow的官方教程中,有两个与之相关的模型被实现出来.第一个模型是围绕着Zaremba的论文Recurre ...
- 第三十六节,目标检测之yolo源码解析
在一个月前,我就已经介绍了yolo目标检测的原理,后来也把tensorflow实现代码仔细看了一遍.但是由于这个暑假事情比较大,就一直搁浅了下来,趁今天有时间,就把源码解析一下.关于yolo目标检测的 ...
- YOLO系列:YOLO v2深度解析 v1 vs v2
概述 第一,在保持原有速度的优势之下,精度上得以提升.VOC 2007数据集测试,67FPS下mAP达到76.8%,40FPS下mAP达到78.6%,可以与Faster R-CNN和SSD一战 第二, ...
随机推荐
- lnmp环境下nginx配置‘负载均衡’
NGINX负载均衡分发请求的几种方式: 1.轮询(默认)每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除.2.weight 指定轮询几率,weight和访问比率成正比 ...
- ZT 3.1 依赖倒置原则的定义
设计模式精解-GoF 23 种设计模式解析附 C++实现源码http://www.mscenter.edu.cn/blog/k_eckelP58 Template 模式获得一种反向控制结构效果,这也是 ...
- csr867x开发日记——常用软件工具介绍
xIDE xIDE开发环境(编译器)可以被用于以下操作 查看代码 构建新应用 调试 运行 重新配置 修改 Universal Front End 通用前端 通用前端(UFE)工具用于配置DSP,ADK ...
- linux自动备份oracle数据库
#此脚本只备份数据表,而且为了方便恢复数据是做的单表逐个备份#在写脚本过程中遇到的报错均加入了解决方案的链接(虽然错误代码没有贴出来)#最终将在脚本所在目录生成年月日-时分的目录,目录下为表名.dmp ...
- linux shell数据重定向
标准输入 (stdin) :代码为 0 ,使用 < 或 << :标准输出 (stdout):代码为 1 ,使用 > 或 >> :标准错误输出(stderr):代码为 ...
- c++11 多线程新特性学习 (1) 管理线程
1.基础介绍 c++11中,线程是通过std::thread对象来开始的,用法为 #include<thread> //必须包含的头文件 void do_work(){ std::cout ...
- Android(java)学习笔记208:Android下的属性动画高级用法(Property Animation)
1. 大家好,在上一篇文章当中,我们学习了Android属性动画的基本用法,当然也是最常用的一些用法,这些用法足以覆盖我们平时大多情况下的动画需求了.但是,正如上篇文章当中所说到的,属性动画对补间动画 ...
- anydesk重启脚本
1.restart.sh: #!/bin/sh sh /home/zhoushuo/anydeskTest/stop.sh echo 'zhoushuo'|sudo -S /usr/bin/anyde ...
- Linux 查看所有登录用户的操作历史
在linux系统的环境下,不管是root用户还是其它的用户只有登陆系统后用进入操作我们都可以通过命令history来查看历史记录,可是假如一台服务器多人登陆,一天因为某人误操作了删除了重要的数据.这时 ...
- mac 删除自带 ABC 输入法的方法
首先需要关闭 mac 系统的 SIP ,不然删不掉,不会关的可以查看我的另一篇文章:mac 关闭系统完整性保护 SIP(System Integrity Protection)的方法 . 关闭 SIP ...