miou
1. 前言
- 本文学习记录了机器学习中的分类常见评价指标以及分割中的MIoU。
- 主要有以下概念:Accuracy, Precision, Recall, Fscore,混淆矩阵,IoU及MIoU。
2. 分类评测指标
- 图像分类, 顾名思义就是一个模式分类问题, 它的目标是将不同的图像, 划分到不同的类别,实现最小的分类误差, 这里我们只考虑单标签分类问题, 即每一个图片都有唯一的类别。
- 对于单个标签分类的问题, 评价指标主要有 Accuracy, Precision, Recall, Fscore。
在计算这些指标之前, 我们先计算几个基本指标, 这些指标是基于二分类的任务, 也可以拓展到多分类。
- 标签为正样本, 分类为正样本的数目为 True Positive, 简称 TP。
- 标签为正样本, 分类为负样本的数目为 False Negative,简称 FN。
- 标签为负样本, 分类为正样本的数目为 False Positive,简称 FP。
- 标签为负样本, 分类为负样本的数目为True Negative,简称 TN。
判别是否为正例只需要设一个概率阈值 T,预测概率大于阈值 T 的为正类, 小于阈值 T 的为负类,默认就是 0.5。 如果我们减小这个阀值 T, 更多的样本会被识别为正类,这 样可以提高正类的召回率, 但同时也会带来更多的负类被错分为正类。 如果增加阈值 T, 则正类的召回率降低, 精度增加。 如果是多类,比如 ImageNet1000 分类比赛中的 1000 类, 预测类别就是预测概率最大的那一类。
2.1 准确率 Accuracy
- 单标签分类任务中每一个样本都只有一个确定的类别, 预测到该类别就是分类正确, 没有预测到就是分类错误,因此最直观的指标就是 Accuracy,也就是准确率。
- Accuracy=(TP+TN)/(TP+FP+TN+FN), 表示的就是所有样本都正确分类的概率, 可以 使用不同的阈值 T。
- 在 ImageNet 中使用的 Accuracy 指标包括 Top_1 Accuracy 和 Top_5 Accuracy, Top_1 Accuracy 就是前面计算的 Accuracy。
- 记样本 xi 的类别为 yi,类别种类为(0,1,…,C),预测类别函数为 f,则 Top-1 的计 算方法如下:
- 如果给出概率最大的 5 个预测类别, 只要包含真实的类别,则判定预测正确, 计算出来的指标就是 Top-5。
2.2 精确度 Precision 和召回率 Recall
- 正样本精确率为:Precision=TP/(TP+FP), 表示召回为正样本的样本中, 到底有多少是真正的正样本。
- 正样本召回率为:Recall=TP/(TP+FN),,表示的是有多少样本被召回类。
2.3 F1 score
- 有的时候我们不仅关注正样本的准确率,也关心其召回率, 但是又不想用 Accuracy 来进行衡量, 一个折中的指标是采用 F-score。
- F1 score=2x Precision x Recall / (Precision+Recall), 只有在召回率 Recall 和 精确率 Precision 都高的情况下,F1 score 才会很高, 因此 F1 score 是一个综合性能 的指标。
2.4 混淆矩阵
- 如果对于每一类, 我们想知道类别之间相互误分的情况, 查看是否有特定的类别之间相互混淆, 就可以用混淆矩阵画出分类的详细预测结果。 对于包含多个类别的任务, 混淆矩阵很清晰的反映出各类别之间的错分概率,如下。
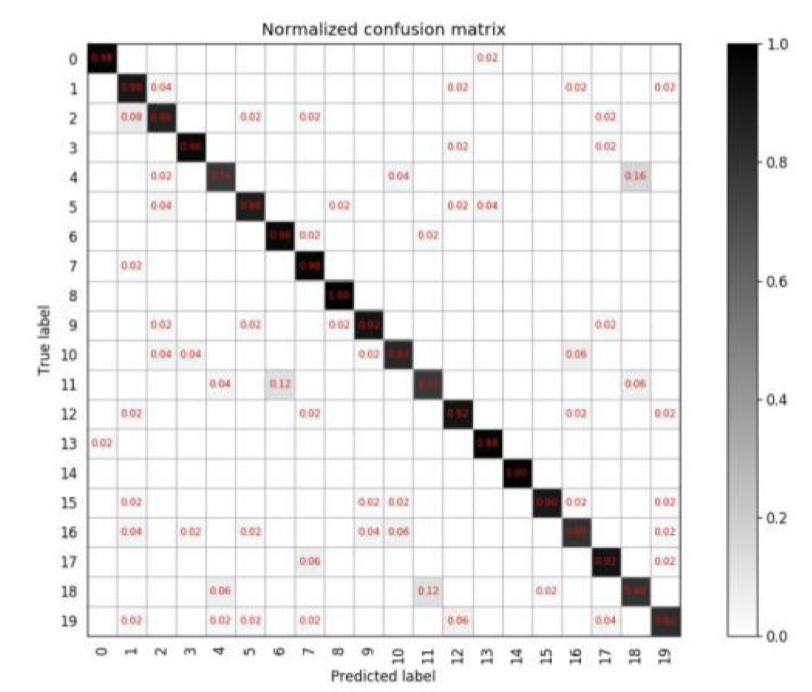
- 这是一个包含 20 个类别的分类任务,混淆矩阵为 20 x 20 的矩阵, 其中第 i 行第 j 列, 表示第 i 类目标被分类为第 j 类的概率,可以知道, 越好的分类器对角线上的值更大, 其他地方应该越小。
3. 分割评价指标
3.1 IoU
- IoU 全称 Intersection-over-Union, 即交并比, 在目标检测领域中, 定义为两个矩形框面积的交集和并集的比值, IoU=A∩B/A∪B。

- 如果完全重叠,则 IoU 等于 1, 是最理想的情况。一般在检测任务中,IoU 大于等于 0.5 就认为召回, 如果设置更高的 IoU 阈值,则召回率下降,同时定位框也越更加精确。
- 在图像分割中也会经常使用 IoU,此时就不必限定为两个矩形框的面积。 比如对于二 分类的前背景分割, 那么 IoU=(真实前景像素面积∩预测前景像素面积)/(真实前景像素面积∪预测前景像素面积), 这一个指标, 通常比直接计算每一个像素的分类正确概 率要低,也对错误分类更加敏感。
3.2 精确度
假设共有k类($L0-L_k,其中包含背景),,其中包含背景),p{ij}表示原本是i类但预测为j类的结果数。表示原本是i类但预测为j类的结果数。p{ii}$表示真正的结果数。而$p{ij}和和p_{ji}$分别被解释为假正和假负,尽管两者都是假正与假负之和。
Pixel Accuracy:标记正确的像素占总像素的比例
PA=∑ki=0pii∑ki=0∑kj=0pijPA=∑i=0kpii∑i=0k∑j=0kpijMean Pixel Accuracy:PA的平均值
MPA=1k∑i=0kpii∑kj=0pijMPA=1k∑i=0kpii∑j=0kpij
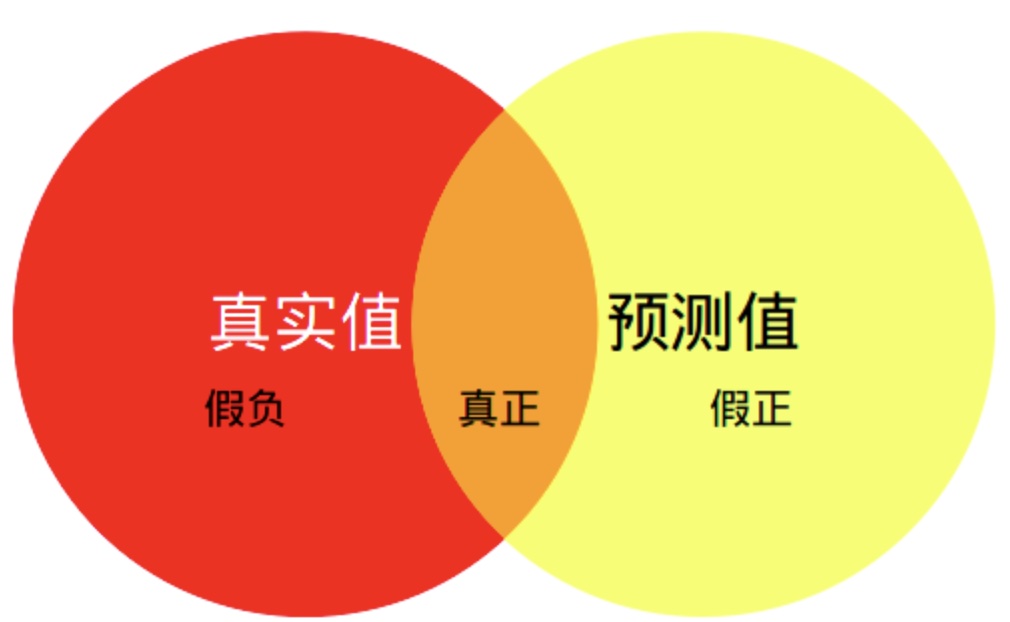
MIoU:均交并比,语义分割的标准度量。计算两个集合的交集与并集之比,在语义分割中,这两个集合为真实值和预测值。这个比例可以理解为:真正数/真正+假负+假正。
MIoU=1k∑i=0kpii∑kj=0pij+∑kj=0pji−piiMIoU=1k∑i=0kpii∑j=0kpij+∑j=0kpji−pii等价于
MIoU=1k∑i=0kTPTP+FP+FNMIoU=1k∑i=0kTPTP+FP+FN直观理解如下图:
3.3 上述指标的计算
- 首先得得出混淆矩阵,例如:
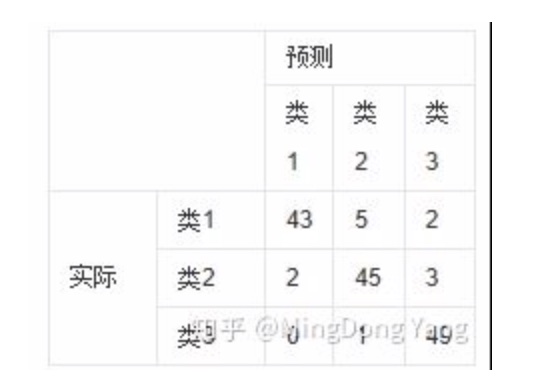
- 对于上例,MIoU的解释:
- 对于类别1:TP=43,FN=7,FP=2;
- 类别2:TP=45,FN=5,FP=6;
- 类别3:TP=49,FN=1,FP=5.
- 因此:IoU1=43/(43+2+7)=82.69%,IoU2=45/(45+5+6)=80.36%,IoU=49/(49+1+5)=89.09%
- 因此mIoU=84.05%,其实就是IOU的分母计算为矩阵的每一行加每一列,再减去重复的TP。
- 根据上述公式,代码如下:
miou的更多相关文章
- DeeplabV3+ 命令行不显示miou的解决
首先看到训练时会在命令行里输出 loss 和 total loss,那是怎么做到的呢,通过分析 train.py 源码,看到如下代码 total_loss = tf.cond( should_log, ...
- mIoU混淆矩阵生成函数代码详解
代码参考博客原文: https://blog.csdn.net/jiongnima/article/details/84750819 在原文和原文的引用里,找到了关于mIoU详尽的解释.这里重点解析 ...
- 目标检测的评价指标(TP、TN、FP、FN、Precision、Recall、IoU、mIoU、AP、mAP)
1. TP TN FP FN GroundTruth 预测结果 TP(True Positives): 真的正样本 = [正样本 被正确分为 正样本] TN(True Negatives): 真的 ...
- 详解计算miou的代码以及混淆矩阵的意义
详解计算miou的代码以及混淆矩阵的意义 miou的定义 ''' Mean Intersection over Union(MIoU,均交并比):为语义分割的标准度量.其计算两个集合的交集和并集之比. ...
- LeetCode : 223. Rectangle Area
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAABRQAAAQ0CAYAAAAPPZBqAAAMFGlDQ1BJQ0MgUHJvZmlsZQAASImVlw
- 论文笔记(7):Constrained Convolutional Neural Networks for Weakly Supervised Segmentation
UC Berkeley的Deepak Pathak 使用了一个具有图像级别标记的训练数据来做弱监督学习.训练数据中只给出图像中包含某种物体,但是没有其位置信息和所包含的像素信息.该文章的方法将imag ...
- 论文笔记(6):Weakly-and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation
这篇文章的主要贡献点在于: 1.实验证明仅仅利用图像整体的弱标签很难训练出很好的分割模型: 2.可以利用bounding box来进行训练,并且得到了较好的结果,这样可以代替用pixel-level训 ...
- 理解图像分割中的卷积(Understand Convolution for Semantic Segmentation)
以最佳的101 layer的ResNet-DUC为基础,添加HDC,实验探究了几种变体: 无扩张卷积(no dilation):对于所有包含扩张卷积,设置r=1r=1 扩张卷积(dilation Co ...
- SegNet 理解与文章结构
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation 发表于2016年,作者 Vijay B ...
- DeeplabV3+ 训练自己的遥感数据
一.预处理数据部分 1.创建 tfrecord(修改 deeplab\ dateasets\ build_data.py) 模型本身是把一张张 jpg 和 png 格式图片读到一个 Example 里 ...
随机推荐
- 读后笔记 -- Python 全栈测试开发 Chapter8:接口测试
8.1 接口测试 1. 市场分布 UI(web.app)自动化:10% 接口自动化:20% 单元测试:70% -- 测开 2. 接口类型: 1)结构划分:模块间(系统间)的接口称为内部接口:系统与第三 ...
- The 17th Zhejiang Provincial Collegiate Programming Contest B.Bin Packing Problem
题意 给定n个物品,和一个容量为C的桶 需要求出为了装下这些物品,分别使用首次适应算法(FF).最佳适应算法(BF)需要的桶的数量 \(n \leq 10^6\) 思路 BF:容易想到可以用set维护 ...
- GrADS 读取NetCDF和HDF的ctl文件 SDF文件的描述文件
翻译自http://cola.gmu.edu/grads/gadoc/SDFdescriptorfile.html 使用GrADS阅读NetCDF和HDF文件 NetCDF和HDF格式的文件被称作自描 ...
- mi
小米耳机页面 <style> * { margin: 0; padding: 0; } body { width: 1226px; background-color: #f5f5f5; m ...
- lxml库和BeautifulSoup库常用点小结
算是本人的学习笔记吧,仅供个人学习使用. 以下内容摘自<Python3网络爬虫开发实战--崔庆才著> 1.lxml库 XPath 常用规则: 表达式 描述 nodename 选取此节点的所 ...
- 离线谷歌地图API的开发笔记(二)
一.地图引擎介绍 离线地图引擎运行在WINDOWS平台上,底层由Visual c++语言开发,编译为OCX插件方式.占用文件少,便于二次开发的快速安装部署. 具有专业地图的基础操作功能:地图放大.缩小 ...
- Finance财务软件(支持Excel模板打印专题)
我们可以修改模板文件./service/PrintTemplate/凭证打印模板_v1.xlsx 模板中的字段对应 2010_upgrade_01.sql 中的存储过程sp_voucher_print ...
- DIV CSS遮罩层(弹窗窗口)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- react backend and frontend download file
import { View as ViewFile} from '@/api/SafetyRule'; const Handler_DownLoadFile = (Id:number,IsEngli ...
- 记录:安装nginx
练习的项目,数据都是跨域获取,上线后就不能再获取到数据,就用到nginx来做代理 注意点: 我用的是阿里云轻量服务器,防火墙在默认情况下是把80端口占据了,然而,安装nginx后,ngi ...