Centos7搭建hadoop3.3.4分布式集群
- 1、背景
- 2、集群规划
- 2.1 hdfs集群规划
- 2.2 yarn集群规划
- 3、集群搭建步骤
- 3.1 安装JDK
- 3.2 修改主机名和host映射
- 3.3 配置时间同步
- 3.4 关闭防火墙
- 3.5 配置ssh免密登录
- 3.7 配置hadoop
- 3.7.1 创建目录(3台机器都执行)
- 3.7.2 下载hadoop并解压(hadoop01操作)
- 3.7.3 配置hadoop环境变量(hadoop01操作)
- 3.7.4 hadoop的配置文件分类(hadoop01操作)
- 3.7.5 配置 hadoop-env.sh(hadoop01操作)
- 3.7.6 配置core-site.xml文件(hadoop01操作)(核心配置文件)
- 3.7.7 配置hdfs-site.xml文件(hadoop01操作)(hdfs配置文件)
- 3.7.8 配置yarn-site.xml文件(hadoop01操作)(yarn配置文件)
- 3.7.9 配置mapred-site.xml文件(hadoop01操作)(mapreduce配置文件)
- 3.7.10 配置workers文件(hadoop01操作)
- 3.7.11 3台机器hadoop配置同步(hadoop01操作)
- 3、启动集群
- 4、参考链接
1、背景
最近在学习hadoop,本文记录一下,怎样在Centos7系统上搭建一个3个节点的hadoop集群。
2、集群规划
hadoop集群是由2个集群构成的,分别是hdfs集群和yarn集群。2个集群都是主从结构。
2.1 hdfs集群规划
| ip地址 | 主机名 | 部署服务 |
|---|---|---|
| 192.168.121.140 | hadoop01 | NameNode,DataNode,JobHistoryServer |
| 192.168.121.141 | hadoop02 | DataNode |
| 192.168.121.142 | hadoop03 | DataNode,SecondaryNameNode |
2.2 yarn集群规划
| ip地址 | 主机名 | 部署服务 |
|---|---|---|
| 192.168.121.140 | hadoop01 | NodeManager |
| 192.168.121.141 | hadoop02 | ResourceManager,NodeManager |
| 192.168.121.142 | hadoop03 | NodeManager |
3、集群搭建步骤
3.1 安装JDK
安装jdk步骤较为简单,此处省略。需要注意的是hadoop需要的jdk版本。 https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
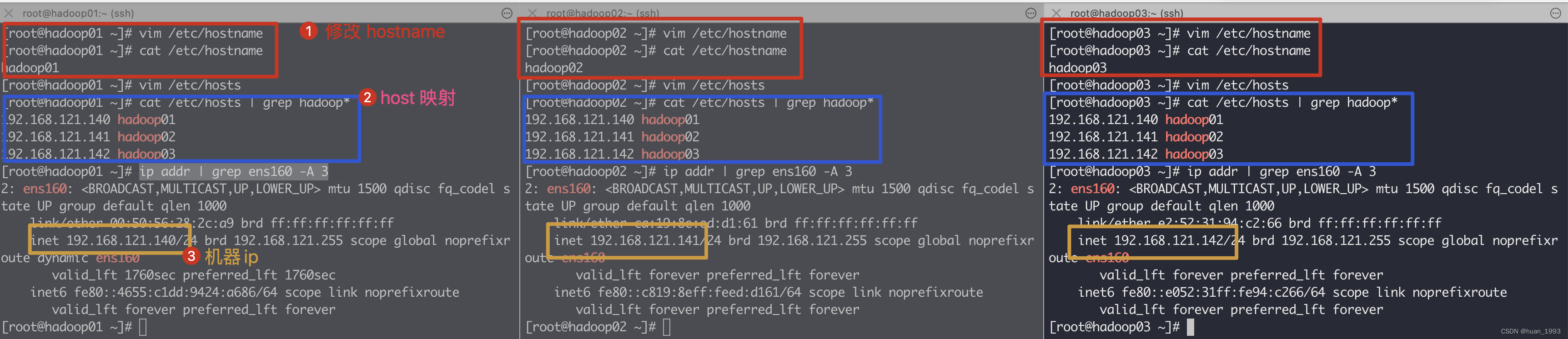
3.2 修改主机名和host映射
| ip地址 | 主机名 |
|---|---|
| 192.168.121.140 | hadoop01 |
| 192.168.121.141 | hadoop02 |
| 192.168.121.142 | hadoop03 |
3台机器上同时执行如下命令
# 此处修改主机名,3台机器的主机名需要都不同
[root@hadoop01 ~]# vim /etc/hostname
[root@hadoop01 ~]# cat /etc/hostname
hadoop01
[root@hadoop01 ~]# vim /etc/hosts
[root@hadoop01 ~]# cat /etc/hosts | grep hadoop*
192.168.121.140 hadoop01
192.168.121.141 hadoop02
192.168.121.142 hadoop03
3.3 配置时间同步
集群中的时间最好保持一致,否则可能会有问题。此处我本地搭建,虚拟机是可以链接外网,直接配置和外网时间同步。如果不能链接外网,则集群中的3台服务器,让另外的2台和其中的一台保持时间同步。
3台机器同时执行如下命令
# 将centos7的时区设置成上海
[root@hadoop01 ~]# ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# 安装ntp
[root@hadoop01 ~]# yum install ntp
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
base | 3.6 kB 00:00
extras | 2.9 kB 00:00
updates | 2.9 kB 00:00
软件包 ntp-4.2.6p5-29.el7.centos.2.aarch64 已安装并且是最新版本
无须任何处理
# 将ntp设置成缺省启动
[root@hadoop01 ~]# systemctl enable ntpd
# 重启ntp服务
[root@hadoop01 ~]# service ntpd restart
Redirecting to /bin/systemctl restart ntpd.service
# 对准时间
[root@hadoop01 ~]# ntpdate asia.pool.ntp.org
19 Feb 12:36:22 ntpdate[1904]: the NTP socket is in use, exiting
# 对准硬件时间和系统时间
[root@hadoop01 ~]# /sbin/hwclock --systohc
# 查看时间
[root@hadoop01 ~]# timedatectl
Local time: 日 2023-02-19 12:36:35 CST
Universal time: 日 2023-02-19 04:36:35 UTC
RTC time: 日 2023-02-19 04:36:35
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: yes
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
# 开始自动时间和远程ntp时间进行同步
[root@hadoop01 ~]# timedatectl set-ntp true
3.4 关闭防火墙
3台机器上同时关闭防火墙,如果不关闭的话,则需要放行hadoop可能用到的所有端口等。
# 关闭防火墙
[root@hadoop01 ~]# systemctl stop firewalld
systemctl stop firewalld
# 关闭防火墙开机自启
[root@hadoop01 ~]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@hadoop01 ~]#
3.5 配置ssh免密登录
3.5.1 新建hadoop部署用户
[root@hadoop01 ~]# useradd hadoopdeploy
[root@hadoop01 ~]# passwd hadoopdeploy
更改用户 hadoopdeploy 的密码 。
新的 密码:
无效的密码: 密码包含用户名在某些地方
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
[root@hadoop01 ~]# vim /etc/sudoers
[root@hadoop01 ~]# cat /etc/sudoers | grep hadoopdeploy
hadoopdeploy ALL=(ALL) NOPASSWD: ALL
[root@hadoop01 ~]#

3.5.2 配置hadoopdeploy用户到任意一台机器都免密登录
配置3台机器,从任意一台到自身和另外2台都进行免密登录。
| 当前机器 | 当前用户 | 免密登录的机器 | 免密登录的用户 |
|---|---|---|---|
| hadoop01 | hadoopdeploy | hadoop01,hadoop02,hadoop03 | hadoopdeploy |
| hadoop02 | hadoopdeploy | hadoop01,hadoop02,hadoop03 | hadoopdeploy |
| hadoop03 | hadoopdeploy | hadoop01,hadoop02,hadoop03 | hadoopdeploy |
此处演示从 hadoop01到hadoop01,hadoop02,hadoop03免密登录的shell
# 切换到 hadoopdeploy 用户
[root@hadoop01 ~]# su - hadoopdeploy
Last login: Sun Feb 19 13:05:43 CST 2023 on pts/0
# 生成公私钥对,下方的提示直接3个回车即可
[hadoopdeploy@hadoop01 ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoopdeploy/.ssh/id_rsa):
Created directory '/home/hadoopdeploy/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoopdeploy/.ssh/id_rsa.
Your public key has been saved in /home/hadoopdeploy/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:PFvgTUirtNLwzDIDs+SD0RIzMPt0y1km5B7rY16h1/E hadoopdeploy@hadoop01
The key's randomart image is:
+---[RSA 2048]----+
|B . . |
| B o . o |
|+ * * + + . |
| O B / = + |
|. = @ O S o |
| o * o * |
| = o o E |
| o + |
| . |
+----[SHA256]-----+
[hadoopdeploy@hadoop01 ~]$ ssh-copy-id hadoop01
...
[hadoopdeploy@hadoop01 ~]$ ssh-copy-id hadoop02
...
[hadoopdeploy@hadoop01 ~]$ ssh-copy-id hadoop03
3.7 配置hadoop
此处如无特殊说明,都是使用的hadoopdeploy用户来操作。
3.7.1 创建目录(3台机器都执行)
# 创建 /opt/bigdata 目录
[hadoopdeploy@hadoop01 ~]$ sudo mkdir /opt/bigdata
# 将 /opt/bigdata/ 目录及它下方所有的子目录的所属者和所属组都给 hadoopdeploy
[hadoopdeploy@hadoop01 ~]$ sudo chown -R hadoopdeploy:hadoopdeploy /opt/bigdata/
[hadoopdeploy@hadoop01 ~]$ ll /opt
total 0
drwxr-xr-x. 2 hadoopdeploy hadoopdeploy 6 Feb 19 13:15 bigdata
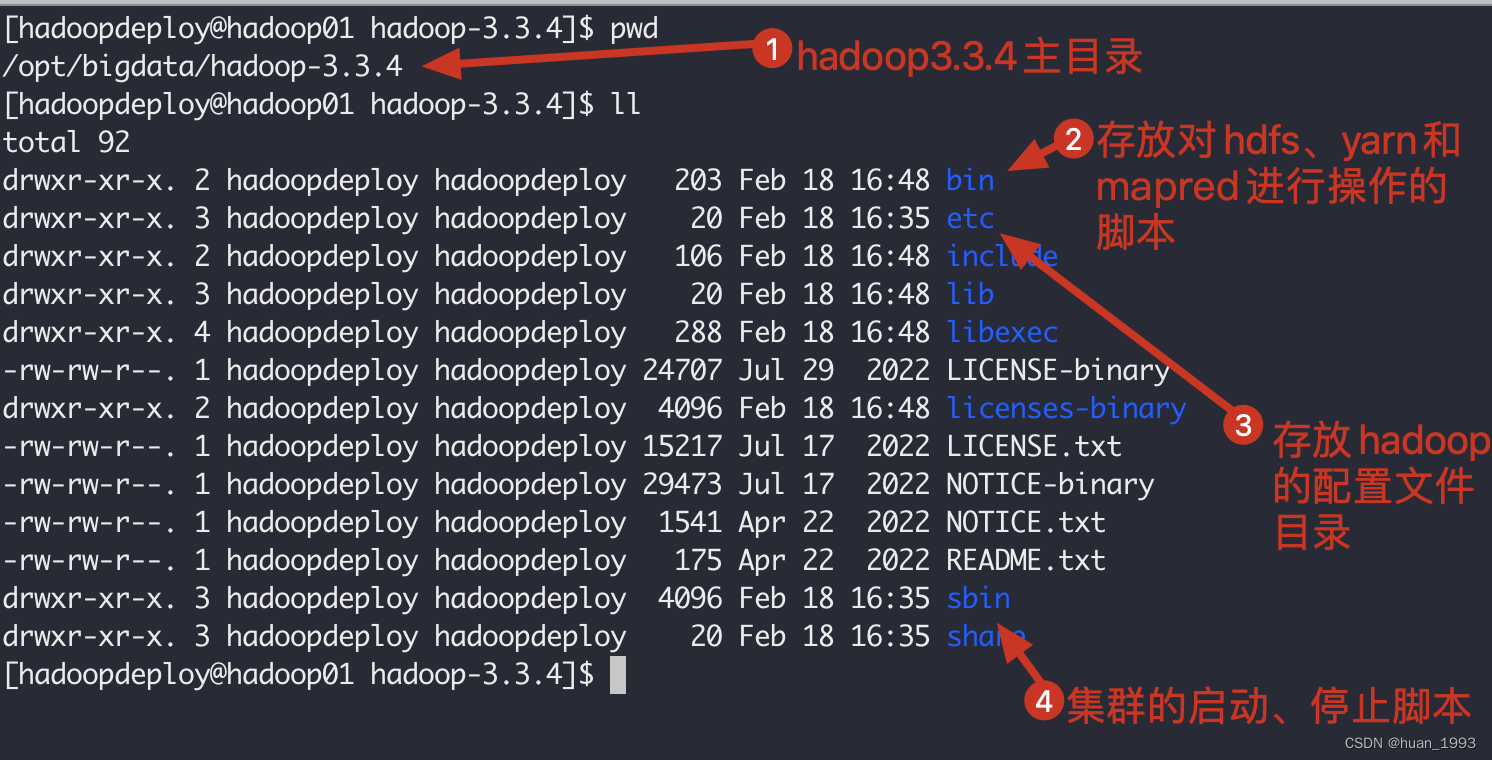
3.7.2 下载hadoop并解压(hadoop01操作)
# 进入目录
[hadoopdeploy@hadoop01 ~]$ cd /opt/bigdata/
# 下载
[hadoopdeploy@hadoop01 ~]$ https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
# 解压并压缩
[hadoopdeploy@hadoop01 bigdata]$ tar -zxvf hadoop-3.3.4.tar.gz && rm -rvf hadoop-3.3.4.tar.gz
3.7.3 配置hadoop环境变量(hadoop01操作)
# 进入hadoop目录
[hadoopdeploy@hadoop01 hadoop-3.3.4]$ cd /opt/bigdata/hadoop-3.3.4/
# 切换到root用户
[hadoopdeploy@hadoop01 hadoop-3.3.4]$ su - root
Password:
Last login: Sun Feb 19 13:06:41 CST 2023 on pts/0
[root@hadoop01 ~]# vim /etc/profile
# 查看hadoop环境变量配置
[root@hadoop01 ~]# tail -n 3 /etc/profile
# 配置HADOOP
export HADOOP_HOME=/opt/bigdata/hadoop-3.3.4/
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
# 让环境变量生效
[root@hadoop01 ~]# source /etc/profile
3.7.4 hadoop的配置文件分类(hadoop01操作)
在hadoop中配置文件大概有这么3大类。
- 默认的只读配置文件:
core-default.xml, hdfs-default.xml, yarn-default.xml and mapred-default.xml. - 自定义配置文件:
etc/hadoop/core-site.xml, etc/hadoop/hdfs-site.xml, etc/hadoop/yarn-site.xml and etc/hadoop/mapred-site.xml会覆盖默认的配置。 - 环境配置文件:
etc/hadoop/hadoop-env.sh and optionally the etc/hadoop/mapred-env.sh and etc/hadoop/yarn-env.sh比如配置NameNode的启动参数HDFS_NAMENODE_OPTS等。

3.7.5 配置 hadoop-env.sh(hadoop01操作)
# 切换到hadoopdeploy用户
[root@hadoop01 ~]# su - hadoopdeploy
Last login: Sun Feb 19 14:22:50 CST 2023 on pts/0
# 进入到hadoop的配置目录
[hadoopdeploy@hadoop01 ~]$ cd /opt/bigdata/hadoop-3.3.4/etc/hadoop/
[hadoopdeploy@hadoop01 hadoop]$ vim hadoop-env.sh
# 增加如下内容
export JAVA_HOME=/usr/local/jdk8
export HDFS_NAMENODE_USER=hadoopdeploy
export HDFS_DATANODE_USER=hadoopdeploy
export HDFS_SECONDARYNAMENODE_USER=hadoopdeploy
export YARN_RESOURCEMANAGER_USER=hadoopdeploy
export YARN_NODEMANAGER_USER=hadoopdeploy
3.7.6 配置core-site.xml文件(hadoop01操作)(核心配置文件)
默认配置文件路径:https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/core-default.xml
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop-3.3.4/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoopdeploy,如果不配置的话,当在hdfs页面点击删除时>看看结果 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoopdeploy</value>
</property>
<!-- 文件垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
3.7.7 配置hdfs-site.xml文件(hadoop01操作)(hdfs配置文件)
默认配置文件路径:https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/hdfs-site.xml
<configuration>
<!-- 配置2个副本 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:9870</value>
</property>
<!-- snn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:9868</value>
</property>
</configuration>
3.7.8 配置yarn-site.xml文件(hadoop01操作)(yarn配置文件)
默认配置文件路径:https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否对容器实施虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 设置 yarn 历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop02:19888/jobhistory/logs</value>
</property>
<!-- 开启日志聚集-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 聚集日志保留的时间7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
3.7.9 配置mapred-site.xml文件(hadoop01操作)(mapreduce配置文件)
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/yarn-site.xml
<configuration>
<!-- 设置 MR 程序默认运行模式:yarn 集群模式,local 本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR 程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- MR 程序历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
3.7.10 配置workers文件(hadoop01操作)
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/workers
hadoop01
hadoop02
hadoop03
workers配置文件中不要有多余的空格或换行。
3.7.11 3台机器hadoop配置同步(hadoop01操作)
1、同步hadoop文件
# 同步 hadoop 文件
[hadoopdeploy@hadoop01 hadoop]$ scp -r /opt/bigdata/hadoop-3.3.4/ hadoopdeploy@hadoop02:/opt/bigdata/hadoop-3.3.4
[hadoopdeploy@hadoop01 hadoop]$ scp -r /opt/bigdata/hadoop-3.3.4/ hadoopdeploy@hadoop03:/opt/bigdata/hadoop-3.3.4
2、hadoop02和hadoop03设置hadoop的环境变量
[hadoopdeploy@hadoop03 bigdata]$ su - root
Password:
Last login: Sun Feb 19 13:07:40 CST 2023 on pts/0
[root@hadoop03 ~]# vim /etc/profile
[root@hadoop03 ~]# tail -n 4 /etc/profile
# 配置HADOOP
export HADOOP_HOME=/opt/bigdata/hadoop-3.3.4/
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
[root@hadoop03 ~]# source /etc/profile
3、启动集群
3.1 集群格式化
当是第一次启动集群时,需要对hdfs进行格式化,在NameNode节点操作。
[hadoopdeploy@hadoop01 hadoop]$ hdfs namenode -format
3.2 集群启动
启动集群有2种方式
方式一:每台机器逐个启动进程,比如:启动NameNode,启动DataNode,可以做到精确控制每个进程的启动。方式二:配置好各个机器之间的免密登录并且配置好 workers 文件,通过脚本一键启动。
3.2.1 逐个启动进程
# HDFS 集群
[hadoopdeploy@hadoop01 hadoop]$ hdfs --daemon start namenode | datanode | secondarynamenode
# YARN 集群
[hadoopdeploy@hadoop01 hadoop]$ hdfs yarn --daemon start resourcemanager | nodemanager | proxyserver
3.2.2 脚本一键启动
start-dfs.sh一键启动hdfs集群的所有进程start-yarn.sh一键启动yarn集群的所有进程start-all.sh一键启动hdfs和yarn集群的所有进程
3.3 启动集群
3.3.1 启动hdfs集群
需要在NameNode这台机器上启动
# 改脚本启动集群中的 NameNode、DataNode和SecondaryNameNode
[hadoopdeploy@hadoop01 hadoop]$ start-dfs.sh
3.3.2 启动yarn集群
需要在ResourceManager这台机器上启动
# 该脚本启动集群中的 ResourceManager 和 NodeManager 进程
[hadoopdeploy@hadoop02 hadoop]$ start-yarn.sh
3.3.3 启动JobHistoryServer
[hadoopdeploy@hadoop01 hadoop]$ mapred --daemon start historyserver
3.4 查看各个机器上启动的服务是否和我们规划的一致

可以看到是一致的。
3.5 访问页面
3.5.1 访问NameNode ui (hdfs集群)
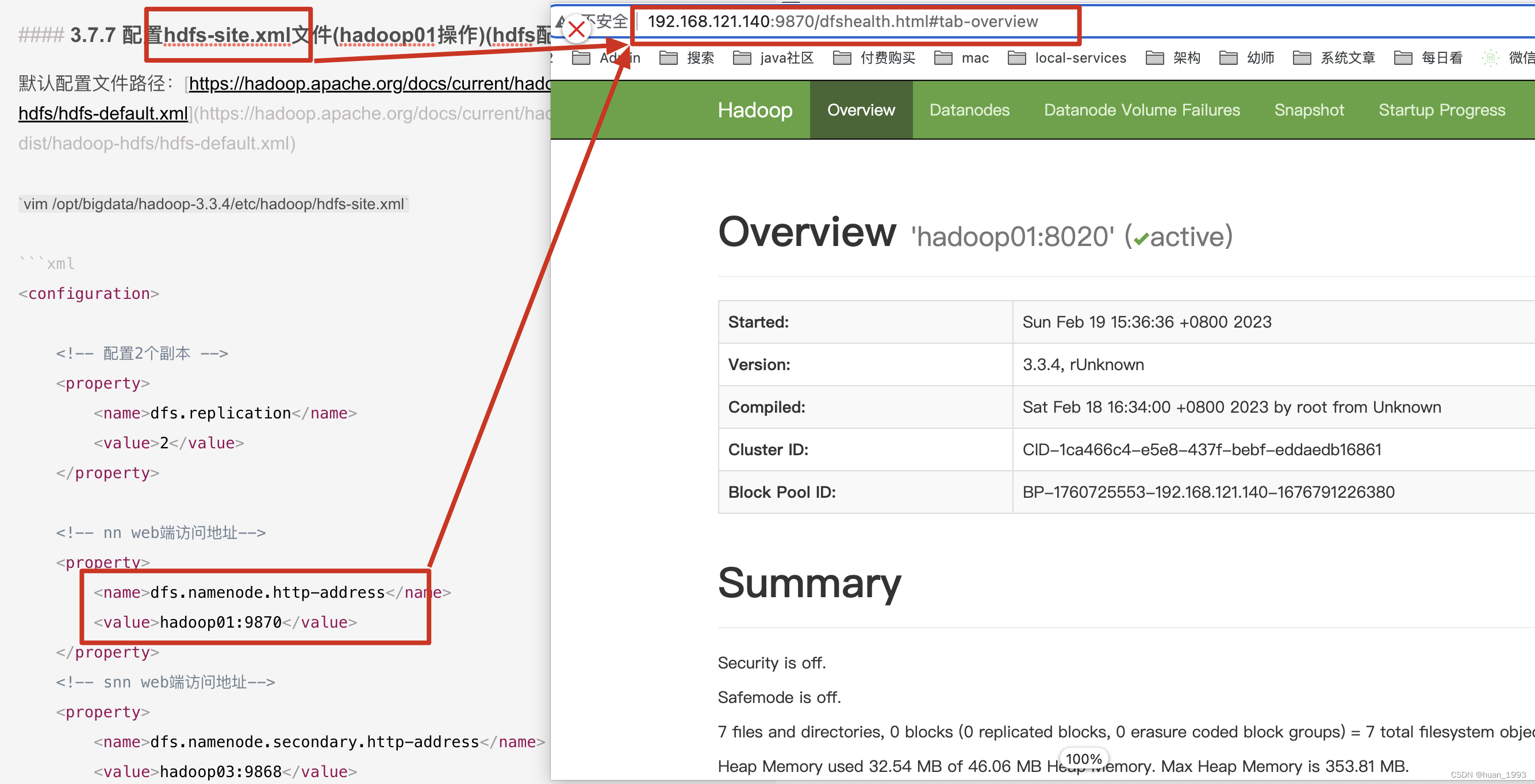
如果这个时候通过 hadoop fs 命令可以上传文件,但是在这个web界面上可以创建文件夹,但是上传文件报错,此处就需要在访问ui界面的这个电脑的hosts文件中,将部署hadoop的那几台的电脑的ip 和hostname 在本机上进行映射。
3.5.2 访问SecondaryNameNode ui
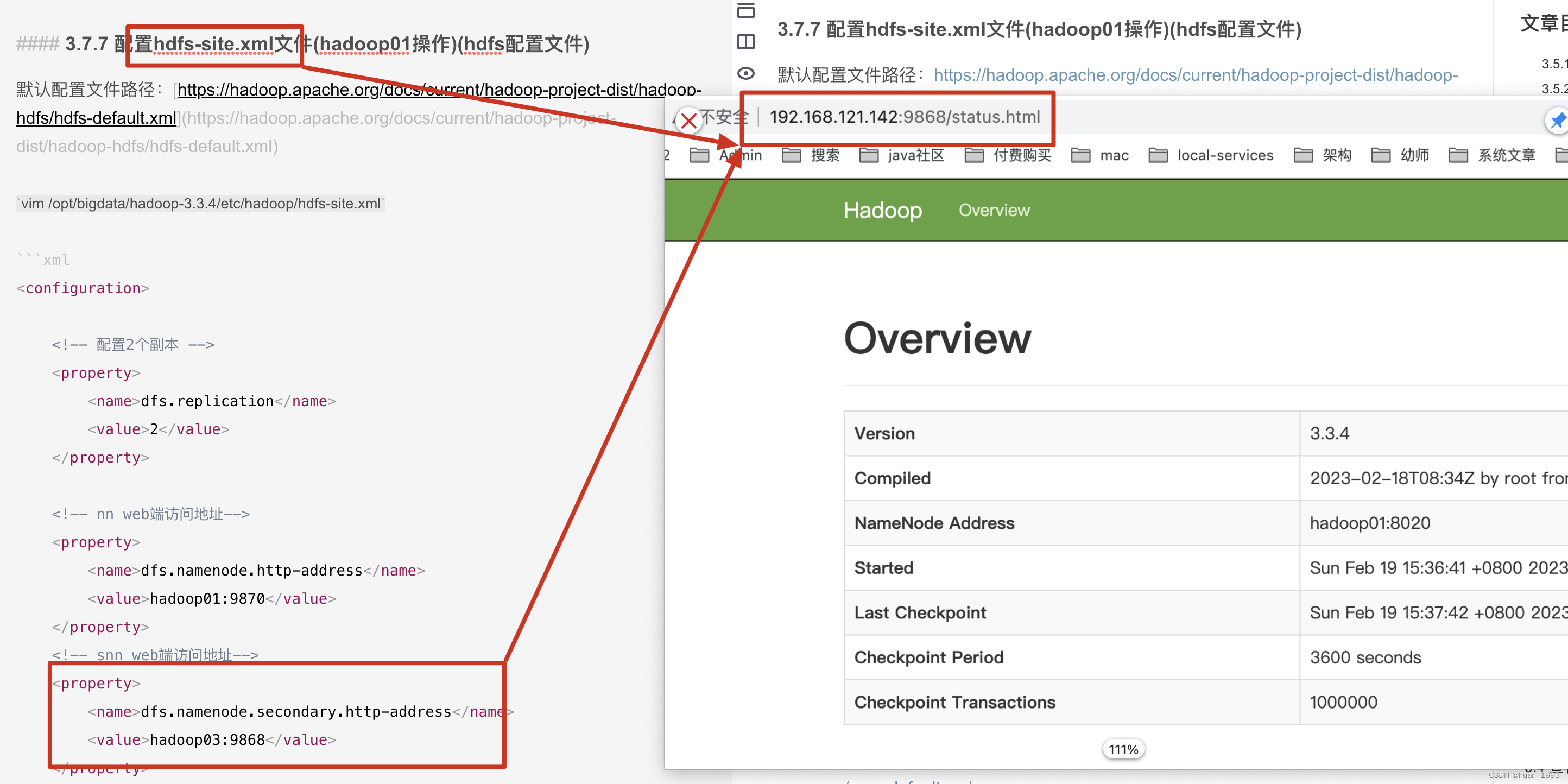
3.5.3 查看ResourceManager ui(yarn集群)
3.5.4 访问jobhistory
4、参考链接
1、https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
2、https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ClusterSetup.html
Centos7搭建hadoop3.3.4分布式集群的更多相关文章
- 亿级Web系统搭建:单机到分布式集群
亿级Web系统搭建:单机到分布式集群 当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压 ...
- Linux Centos7 环境搭建Docker部署Zookeeper分布式集群服务实战
Zookeeper完全分布式集群服务 准备好3台服务器: [x]A-> centos-helios:192.168.19.1 [x]B-> centos-hestia:192.168.19 ...
- [转]亿级Web系统搭建:单机到分布式集群
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架构层 ...
- 亿级Web系统搭建:单机到分布式集群【转】
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架构层 ...
- Ganglia环境搭建并监控Hadoop分布式集群
简介 Ganglia可以监控分布式集群中硬件资源的使用情况,例如CPU,内存,网络等资源.通过Ganglia可以监控Hadoop集群在运行过程中对集群资源的调度,作为简单地运维参考. 环境搭建流程 1 ...
- 一张图讲解最少机器搭建FastDFS高可用分布式集群安装说明
很幸运参与零售云快消平台的公有云搭建及孵化项目.零售云快消平台源于零售云家电3C平台私有项目,是与公司业务强耦合的.为了适用于全场景全品类平台,集团要求项目平台化,我们抢先并承担了此任务.并由我来主 ...
- Spark(二)CentOS7.5搭建Spark2.3.1分布式集群
一 下载安装包 1 官方下载 官方下载地址:http://spark.apache.org/downloads.html 2 安装前提 Java8 安装成功 zookeeper 安 ...
- Flink(二)CentOS7.5搭建Flink1.6.1分布式集群
一. Flink的下载 安装包下载地址:http://flink.apache.org/downloads.html ,选择对应Hadoop的Flink版本下载 [admin@node21 soft ...
- Docker中自动化搭建Hadoop2.6完全分布式集群
这一节将在<Dockerfile完成Hadoop2.6的伪分布式搭建>的基础上搭建一个完全分布式的Hadoop集群. 1. 搭建集群中需要用到的文件 [root@centos-docker ...
- hadoop备战:一台x86计算机搭建hadoop的全分布式集群
主要的软硬件配置: x86台式机,window7 64位系统 vb虚拟机(x86的台式机至少是4G内存,才干开3台虚机) centos6.4操作系统 hadoop-1.1.2.tar.gz jdk- ...
随机推荐
- bugku 矛盾
我承认这道题给我上了一课.... 我觉得很简单的结果不是我想的那样.... 看到这道题我第一个反应是用ascii码表示1或则16进制,或则md5,或则url,base64结果都没对 ..... 去翻了 ...
- ORCL 时间
一.计算时间差 两个Date类型字段:START_DATE,END_DATE,计算这两个日期的时间差(分别以天,小时,分钟,秒,毫秒): 天: ROUND(TO_NUMBER(END_DATE - S ...
- 【十次方微服务后台开发】Day01:环境、缓存(吐槽)、ES搜索文章、MQ注册时发送验证码
一.系统设计与工程搭建 1.需求分析 程序员的专属社交平台,包括头条.问答.活动.交友.吐槽.招聘 SpringBoot+SpringCloud+SpringMVC+SpringData全家桶架构 s ...
- 协程- gevent模块
协程 1.什么是协助:在单线程下实现并发效果 2.协程的原理: 通过代码监听IO操作一旦遇到 IO 操作就立刻切换下一个程序 让cpu一直在工作 这样就可以一直占用CPU的效率 提高程序执行效率 切换 ...
- 【精选】前端JS面试题35个
1.问:什么是匿名函数?作用是什么? 答:没有名字的函数就是匿名函数,作用有三,把函数当作变量赋值,把函数当作参数(回调函数),把函数当作另一个函数的返回值(闭包) ...
- MySQL事务(四大特性)-存储过程
目录 一:事务 1.四大特性(ACID) 2.事物存在的必要性(真实比喻) 3.如何使用事务 4.开启事务-回滚-确认 二:事务案例实战 1.模拟消费 2.创建 3.插入数据 4.开启事务 5.修改操 ...
- JavaScript冒泡排序+Vue可视化冒泡动画
冒泡排序(Bubble Sort)算是前端最简单的算法,也是最经典的排序算法了.网上JavaScript版本的冒泡排序很多,今天用Vue实现一个动态的可视化冒泡排序. 01.JavaScript冒泡排 ...
- Salesforce LWC学习(四十) datatable的dynamic action的小坑浅谈
本篇参考:https://developer.salesforce.com/docs/component-library/bundle/lightning-datatable/documentatio ...
- 基于K-means聚类算法进行客户人群分析
摘要:在本案例中,我们使用人工智能技术的聚类算法去分析超市购物中心客户的一些基本数据,把客户分成不同的群体,供营销团队参考并相应地制定营销策略. 本文分享自华为云社区<基于K-means聚类算法 ...
- Windows下Mariadb中文乱码问题
win10 在命令行使用Mariadb出现无法插入中文 并且之前正确插入的中文也无法正常显示了 ERROR 1366 (22007): Incorrect string value: '\xB1\xB ...