【机器学习入门与实践】数据挖掘-二手车价格交易预测(含EDA探索、特征工程、特征优化、模型融合等)
【机器学习入门与实践】数据挖掘-二手车价格交易预测(含EDA探索、特征工程、特征优化、模型融合等)
note:项目链接以及码源见文末
1.赛题简介
了解赛题
赛题概况
数据概况
预测指标
分析赛题
数据读取pandas
分类指标评价计算示例
回归指标评价计算示例
EDA探索
- 载入各种数据科学以及可视化库
- 载入数据
- 总览数据概况
- 判断数据缺失和异常
- 了解预测值的分布
- 特征分为类别特征和数字特征,并对类别特征查看unique分布
- 数字特征分析
- 类别特征分析
- 用pandas_profiling生成数据报告
特征工程
- 导入数据
- 删除异常值
- 特征构造
- 特征筛选
建模调参,相关原理介绍与推荐
- 线性回归模型
- 决策树模型
- GBDT模型
- XGBoost模型
- LightGBM模型
- 推荐教材
- 读取数据
- 线性回归 & 五折交叉验证 & 模拟真实业务情况
- 多种模型对比
- 模型调参
模型融合
- 回归\分类概率-融合
- 分类模型融合
- 一些其它方法
- 本赛题示例
1.1 数据说明
比赛要求参赛选手根据给定的数据集,建立模型,二手汽车的交易价格。
来自 Ebay Kleinanzeigen 报废的二手车,数量超过 370,000,包含 20 列变量信息,为了保证
比赛的公平性,将会从中抽取 10 万条作为训练集,5 万条作为测试集 A,5 万条作为测试集
B。同时会对名称、车辆类型、变速箱、model、燃油类型、品牌、公里数、价格等信息进行
脱敏。
一般而言,对于数据在比赛界面都有对应的数据概况介绍(匿名特征除外),说明列的性质特征。了解列的性质会有助于我们对于数据的理解和后续分析。
Tip:匿名特征,就是未告知数据列所属的性质的特征列。
train.csv
- name - 汽车编码
- regDate - 汽车注册时间
- model - 车型编码
- brand - 品牌
- bodyType - 车身类型
- fuelType - 燃油类型
- gearbox - 变速箱
- power - 汽车功率
- kilometer - 汽车行驶公里
- notRepairedDamage - 汽车有尚未修复的损坏
- regionCode - 看车地区编码
- seller - 销售方
- offerType - 报价类型
- creatDate - 广告发布时间
- price - 汽车价格
- v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14'(根据汽车的评论、标签等大量信息得到的embedding向量)【人工构造 匿名特征】
数字全都脱敏处理,都为label encoding形式,即数字形式
1.2预测指标
本赛题的评价标准为MAE(Mean Absolute Error):
$$
MAE=\frac{\sum_{i=1}^{n}\left|y_{i}-\hat{y}{i}\right|}{n}
$$
其中$y$代表第$i$个样本的真实值,其中$\hat{y}_{i}$代表第$i$个样本的预测值。
一般问题评价指标说明:
什么是评估指标:
评估指标即是我们对于一个模型效果的数值型量化。(有点类似与对于一个商品评价打分,而这是针对于模型效果和理想效果之间的一个打分)
一般来说分类和回归问题的评价指标有如下一些形式:
分类算法常见的评估指标如下:
- 对于二类分类器/分类算法,评价指标主要有accuracy, [Precision,Recall,F-score,Pr曲线],ROC-AUC曲线。
- 对于多类分类器/分类算法,评价指标主要有accuracy, [宏平均和微平均,F-score]。
对于回归预测类常见的评估指标如下:
- 平均绝对误差(Mean Absolute Error,MAE),均方误差(Mean Squared Error,MSE),平均绝对百分误差(Mean Absolute Percentage Error,MAPE),均方根误差(Root Mean Squared Error), R2(R-Square)
平均绝对误差
平均绝对误差(Mean Absolute Error,MAE):平均绝对误差,其能更好地反映预测值与真实值误差的实际情况,其计算公式如下:
$$
MAE=\frac{1}{N} \sum_{i=1}^{N}\left|y_{i}-\hat{y}_{i}\right|
$$
均方误差
均方误差(Mean Squared Error,MSE),均方误差,其计算公式为:
$$
MSE=\frac{1}{N} \sum_{i=1}{N}\left(y_{i}-\hat{y}_{i}\right)
$$
R2(R-Square)的公式为:
残差平方和:
$$
SS_{res}=\sum\left(y_{i}-\hat{y}{i}\right)^{2}
$$
总平均值:
$$
SS=\sum\left(y_{i}-\overline{y}_{i}\right)^{2}
$$
其中$\overline{y}$表示$y$的平均值
得到$R^2$表达式为:
$$
R{2}=1-\frac{SS_{res}}{SS_{tot}}=1-\frac{\sum\left(y_{i}-\hat{y}_{i}\right){2}}{\sum\left(y_{i}-\overline{y}\right)^{2}}
$$
$R^2$用于度量因变量的变异中可由自变量解释部分所占的比例,取值范围是 0~1,$R2$越接近1,表明回归平方和占总平方和的比例越大,回归线与各观测点越接近,用x的变化来解释y值变化的部分就越多,回归的拟合程度就越好。所以$R2$也称为拟合优度(Goodness of Fit)的统计量。
$y_{i}$表示真实值,$\hat{y}{i}$表示预测值,$\overline{y}$表示样本均值。得分越高拟合效果越好。
1.3分析赛题
- 此题为传统的数据挖掘问题,通过数据科学以及机器学习深度学习的办法来进行建模得到结果。
- 此题是一个典型的回归问题。
- 主要应用xgb、lgb、catboost,以及pandas、numpy、matplotlib、seabon、sklearn、keras等等数据挖掘常用库或者框架来进行数据挖掘任务。
2.数据探索
# 下载数据
!wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/DM/data.zip
# 解压下载好的数据
!unzip data.zip
# 导入函数工具
## 基础工具
import numpy as np
import pandas as pd
import warnings
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.special import jn
from IPython.display import display, clear_output
import time
warnings.filterwarnings('ignore')
%matplotlib inline
## 模型预测的
from sklearn import linear_model
from sklearn import preprocessing
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
## 数据降维处理的
from sklearn.decomposition import PCA,FastICA,FactorAnalysis,SparsePCA
import lightgbm as lgb
import xgboost as xgb
## 参数搜索和评价的
from sklearn.model_selection import GridSearchCV,cross_val_score,StratifiedKFold,train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
2.1 数据读取
## 通过Pandas对于数据进行读取 (pandas是一个很友好的数据读取函数库)
Train_data = pd.read_csv('/home/aistudio/dataset/used_car_train_20200313.csv', sep=' ')
TestA_data = pd.read_csv('/home/aistudio/dataset/used_car_testA_20200313.csv', sep=' ')
## 输出数据的大小信息
print('Train data shape:',Train_data.shape)
print('TestA data shape:',TestA_data.shape)
Train data shape: (150000, 31)
TestA data shape: (50000, 30)
2.2 数据简要浏览
## 通过.head() 简要浏览读取数据的形式
Train_data.head()
\3cpre>\3ccode>.dataframe tbody tr th { vertical-align: top }
.dataframe thead th { text-align: right }
| SaleID | name | regDate | model | brand | bodyType | fuelType | gearbox | power | kilometer | ... | v_5 | v_6 | v_7 | v_8 | v_9 | v_10 | v_11 | v_12 | v_13 | v_14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 736 | 20040402 | 30.0 | 6 | 1.0 | 0.0 | 0.0 | 60 | 12.5 | ... | 0.235676 | 0.101988 | 0.129549 | 0.022816 | 0.097462 | -2.881803 | 2.804097 | -2.420821 | 0.795292 | 0.914762 |
| 1 | 1 | 2262 | 20030301 | 40.0 | 1 | 2.0 | 0.0 | 0.0 | 0 | 15.0 | ... | 0.264777 | 0.121004 | 0.135731 | 0.026597 | 0.020582 | -4.900482 | 2.096338 | -1.030483 | -1.722674 | 0.245522 |
| 2 | 2 | 14874 | 20040403 | 115.0 | 15 | 1.0 | 0.0 | 0.0 | 163 | 12.5 | ... | 0.251410 | 0.114912 | 0.165147 | 0.062173 | 0.027075 | -4.846749 | 1.803559 | 1.565330 | -0.832687 | -0.229963 |
| 3 | 3 | 71865 | 19960908 | 109.0 | 10 | 0.0 | 0.0 | 1.0 | 193 | 15.0 | ... | 0.274293 | 0.110300 | 0.121964 | 0.033395 | 0.000000 | -4.509599 | 1.285940 | -0.501868 | -2.438353 | -0.478699 |
| 4 | 4 | 111080 | 20120103 | 110.0 | 5 | 1.0 | 0.0 | 0.0 | 68 | 5.0 | ... | 0.228036 | 0.073205 | 0.091880 | 0.078819 | 0.121534 | -1.896240 | 0.910783 | 0.931110 | 2.834518 | 1.923482 |
5 rows × 31 columns
2.3 数据信息查看
## 通过 .info() 简要可以看到对应一些数据列名,以及NAN缺失信息
Train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150000 entries, 0 to 149999
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 SaleID 150000 non-null int64
1 name 150000 non-null int64
2 regDate 150000 non-null int64
3 model 149999 non-null float64
4 brand 150000 non-null int64
5 bodyType 145494 non-null float64
6 fuelType 141320 non-null float64
7 gearbox 144019 non-null float64
8 power 150000 non-null int64
9 kilometer 150000 non-null float64
10 notRepairedDamage 150000 non-null object
11 regionCode 150000 non-null int64
12 seller 150000 non-null int64
13 offerType 150000 non-null int64
14 creatDate 150000 non-null int64
15 price 150000 non-null int64
16 v_0 150000 non-null float64
17 v_1 150000 non-null float64
18 v_2 150000 non-null float64
19 v_3 150000 non-null float64
20 v_4 150000 non-null float64
21 v_5 150000 non-null float64
22 v_6 150000 non-null float64
23 v_7 150000 non-null float64
24 v_8 150000 non-null float64
25 v_9 150000 non-null float64
26 v_10 150000 non-null float64
27 v_11 150000 non-null float64
28 v_12 150000 non-null float64
29 v_13 150000 non-null float64
30 v_14 150000 non-null float64
dtypes: float64(20), int64(10), object(1)
memory usage: 35.5+ MB
## 通过 .columns 查看列名
Train_data.columns
Index(['SaleID', 'name', 'regDate', 'model', 'brand', 'bodyType', 'fuelType',
'gearbox', 'power', 'kilometer', 'notRepairedDamage', 'regionCode',
'seller', 'offerType', 'creatDate', 'price', 'v_0', 'v_1', 'v_2', 'v_3',
'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12',
'v_13', 'v_14'],
dtype='object')
TestA_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 50000 entries, 0 to 49999
Data columns (total 30 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 SaleID 50000 non-null int64
1 name 50000 non-null int64
2 regDate 50000 non-null int64
3 model 50000 non-null float64
4 brand 50000 non-null int64
5 bodyType 48587 non-null float64
6 fuelType 47107 non-null float64
7 gearbox 48090 non-null float64
8 power 50000 non-null int64
9 kilometer 50000 non-null float64
10 notRepairedDamage 50000 non-null object
11 regionCode 50000 non-null int64
12 seller 50000 non-null int64
13 offerType 50000 non-null int64
14 creatDate 50000 non-null int64
15 v_0 50000 non-null float64
16 v_1 50000 non-null float64
17 v_2 50000 non-null float64
18 v_3 50000 non-null float64
19 v_4 50000 non-null float64
20 v_5 50000 non-null float64
21 v_6 50000 non-null float64
22 v_7 50000 non-null float64
23 v_8 50000 non-null float64
24 v_9 50000 non-null float64
25 v_10 50000 non-null float64
26 v_11 50000 non-null float64
27 v_12 50000 non-null float64
28 v_13 50000 non-null float64
29 v_14 50000 non-null float64
dtypes: float64(20), int64(9), object(1)
memory usage: 11.4+ MB
2.4 数据统计信息浏览
## 通过 .describe() 可以查看数值特征列的一些统计信息
Train_data.describe()
\3cpre>\3ccode>.dataframe tbody tr th { vertical-align: top }
.dataframe thead th { text-align: right }
| SaleID | name | regDate | model | brand | bodyType | fuelType | gearbox | power | kilometer | ... | v_5 | v_6 | v_7 | v_8 | v_9 | v_10 | v_11 | v_12 | v_13 | v_14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 150000.000000 | 150000.000000 | 1.500000e+05 | 149999.000000 | 150000.000000 | 145494.000000 | 141320.000000 | 144019.000000 | 150000.000000 | 150000.000000 | ... | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 |
| mean | 74999.500000 | 68349.172873 | 2.003417e+07 | 47.129021 | 8.052733 | 1.792369 | 0.375842 | 0.224943 | 119.316547 | 12.597160 | ... | 0.248204 | 0.044923 | 0.124692 | 0.058144 | 0.061996 | -0.001000 | 0.009035 | 0.004813 | 0.000313 | -0.000688 |
| std | 43301.414527 | 61103.875095 | 5.364988e+04 | 49.536040 | 7.864956 | 1.760640 | 0.548677 | 0.417546 | 177.168419 | 3.919576 | ... | 0.045804 | 0.051743 | 0.201410 | 0.029186 | 0.035692 | 3.772386 | 3.286071 | 2.517478 | 1.288988 | 1.038685 |
| min | 0.000000 | 0.000000 | 1.991000e+07 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.500000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -9.168192 | -5.558207 | -9.639552 | -4.153899 | -6.546556 |
| 25% | 37499.750000 | 11156.000000 | 1.999091e+07 | 10.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 75.000000 | 12.500000 | ... | 0.243615 | 0.000038 | 0.062474 | 0.035334 | 0.033930 | -3.722303 | -1.951543 | -1.871846 | -1.057789 | -0.437034 |
| 50% | 74999.500000 | 51638.000000 | 2.003091e+07 | 30.000000 | 6.000000 | 1.000000 | 0.000000 | 0.000000 | 110.000000 | 15.000000 | ... | 0.257798 | 0.000812 | 0.095866 | 0.057014 | 0.058484 | 1.624076 | -0.358053 | -0.130753 | -0.036245 | 0.141246 |
| 75% | 112499.250000 | 118841.250000 | 2.007111e+07 | 66.000000 | 13.000000 | 3.000000 | 1.000000 | 0.000000 | 150.000000 | 15.000000 | ... | 0.265297 | 0.102009 | 0.125243 | 0.079382 | 0.087491 | 2.844357 | 1.255022 | 1.776933 | 0.942813 | 0.680378 |
| max | 149999.000000 | 196812.000000 | 2.015121e+07 | 247.000000 | 39.000000 | 7.000000 | 6.000000 | 1.000000 | 19312.000000 | 15.000000 | ... | 0.291838 | 0.151420 | 1.404936 | 0.160791 | 0.222787 | 12.357011 | 18.819042 | 13.847792 | 11.147669 | 8.658418 |
8 rows × 30 columns
TestA_data.describe()
\3cpre>\3ccode>.dataframe tbody tr th { vertical-align: top }
.dataframe thead th { text-align: right }
| SaleID | name | regDate | model | brand | bodyType | fuelType | gearbox | power | kilometer | ... | v_5 | v_6 | v_7 | v_8 | v_9 | v_10 | v_11 | v_12 | v_13 | v_14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 50000.000000 | 50000.000000 | 5.000000e+04 | 50000.000000 | 50000.000000 | 48587.000000 | 47107.000000 | 48090.000000 | 50000.000000 | 50000.000000 | ... | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 |
| mean | 174999.500000 | 68542.223280 | 2.003393e+07 | 46.844520 | 8.056240 | 1.782185 | 0.373405 | 0.224350 | 119.883620 | 12.595580 | ... | 0.248669 | 0.045021 | 0.122744 | 0.057997 | 0.062000 | -0.017855 | -0.013742 | -0.013554 | -0.003147 | 0.001516 |
| std | 14433.901067 | 61052.808133 | 5.368870e+04 | 49.469548 | 7.819477 | 1.760736 | 0.546442 | 0.417158 | 185.097387 | 3.908979 | ... | 0.044601 | 0.051766 | 0.195972 | 0.029211 | 0.035653 | 3.747985 | 3.231258 | 2.515962 | 1.286597 | 1.027360 |
| min | 150000.000000 | 0.000000 | 1.991000e+07 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.500000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -9.160049 | -5.411964 | -8.916949 | -4.123333 | -6.112667 |
| 25% | 162499.750000 | 11203.500000 | 1.999091e+07 | 10.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 75.000000 | 12.500000 | ... | 0.243762 | 0.000044 | 0.062644 | 0.035084 | 0.033714 | -3.700121 | -1.971325 | -1.876703 | -1.060428 | -0.437920 |
| 50% | 174999.500000 | 52248.500000 | 2.003091e+07 | 29.000000 | 6.000000 | 1.000000 | 0.000000 | 0.000000 | 109.000000 | 15.000000 | ... | 0.257877 | 0.000815 | 0.095828 | 0.057084 | 0.058764 | 1.613212 | -0.355843 | -0.142779 | -0.035956 | 0.138799 |
| 75% | 187499.250000 | 118856.500000 | 2.007110e+07 | 65.000000 | 13.000000 | 3.000000 | 1.000000 | 0.000000 | 150.000000 | 15.000000 | ... | 0.265328 | 0.102025 | 0.125438 | 0.079077 | 0.087489 | 2.832708 | 1.262914 | 1.764335 | 0.941469 | 0.681163 |
| max | 199999.000000 | 196805.000000 | 2.015121e+07 | 246.000000 | 39.000000 | 7.000000 | 6.000000 | 1.000000 | 20000.000000 | 15.000000 | ... | 0.291618 | 0.153265 | 1.358813 | 0.156355 | 0.214775 | 12.338872 | 18.856218 | 12.950498 | 5.913273 | 2.624622 |
8 rows × 29 columns
3.数据分析
#### 1) 提取数值类型特征列名
numerical_cols = Train_data.select_dtypes(exclude = 'object').columns
print(numerical_cols)
Index(['SaleID', 'name', 'regDate', 'model', 'brand', 'bodyType', 'fuelType',
'gearbox', 'power', 'kilometer', 'regionCode', 'seller', 'offerType',
'creatDate', 'price', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6',
'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13', 'v_14'],
dtype='object')
categorical_cols = Train_data.select_dtypes(include = 'object').columns
print(categorical_cols)
Index(['notRepairedDamage'], dtype='object')
#### 2) 构建训练和测试样本
## 选择特征列
feature_cols = [col for col in numerical_cols if col not in ['SaleID','name','regDate','creatDate','price','model','brand','regionCode','seller']]
feature_cols = [col for col in feature_cols if 'Type' not in col]
## 提前特征列,标签列构造训练样本和测试样本
X_data = Train_data[feature_cols]
Y_data = Train_data['price']
X_test = TestA_data[feature_cols]
print('X train shape:',X_data.shape)
print('X test shape:',X_test.shape)
X train shape: (150000, 18)
X test shape: (50000, 18)
## 定义了一个统计函数,方便后续信息统计
def Sta_inf(data):
print('_min',np.min(data))
print('_max:',np.max(data))
print('_mean',np.mean(data))
print('_ptp',np.ptp(data))
print('_std',np.std(data))
print('_var',np.var(data))
#### 3) 统计标签的基本分布信息
print('Sta of label:')
Sta_inf(Y_data)
Sta of label:
_min 11
_max: 99999
_mean 5923.327333333334
_ptp 99988
_std 7501.973469876635
_var 56279605.942732885
## 绘制标签的统计图,查看标签分布
plt.hist(Y_data)
plt.show()
plt.close()

#### 4) 缺省值用-1填补
X_data = X_data.fillna(-1)
X_test = X_test.fillna(-1)
4. 模型训练与预测(特征工程、模型融合)
4.1 利用xgb进行五折交叉验证查看模型的参数效果
## xgb-Model
xgr = xgb.XGBRegressor(n_estimators=120, learning_rate=0.1, gamma=0, subsample=0.8,\
colsample_bytree=0.9, max_depth=7) #,objective ='reg:squarederror'
scores_train = []
scores = []
## 5折交叉验证方式
sk=StratifiedKFold(n_splits=5,shuffle=True,random_state=0)
for train_ind,val_ind in sk.split(X_data,Y_data):
train_x=X_data.iloc[train_ind].values
train_y=Y_data.iloc[train_ind]
val_x=X_data.iloc[val_ind].values
val_y=Y_data.iloc[val_ind]
xgr.fit(train_x,train_y)
pred_train_xgb=xgr.predict(train_x)
pred_xgb=xgr.predict(val_x)
score_train = mean_absolute_error(train_y,pred_train_xgb)
scores_train.append(score_train)
score = mean_absolute_error(val_y,pred_xgb)
scores.append(score)
print('Train mae:',np.mean(score_train))
print('Val mae',np.mean(scores))
4.2 定义xgb和lgb模型函数
def build_model_xgb(x_train,y_train):
model = xgb.XGBRegressor(n_estimators=150, learning_rate=0.1, gamma=0, subsample=0.8,\
colsample_bytree=0.9, max_depth=7) #, objective ='reg:squarederror'
model.fit(x_train, y_train)
return model
def build_model_lgb(x_train,y_train):
estimator = lgb.LGBMRegressor(num_leaves=127,n_estimators = 150)
param_grid = {
'learning_rate': [0.01, 0.05, 0.1, 0.2],
}
gbm = GridSearchCV(estimator, param_grid)
gbm.fit(x_train, y_train)
return gbm
4.3 切分数据集(Train,Val)进行模型训练,评价和预测
## Split data with val
x_train,x_val,y_train,y_val = train_test_split(X_data,Y_data,test_size=0.3)
print('Train lgb...')
model_lgb = build_model_lgb(x_train,y_train)
val_lgb = model_lgb.predict(x_val)
MAE_lgb = mean_absolute_error(y_val,val_lgb)
print('MAE of val with lgb:',MAE_lgb)
print('Predict lgb...')
model_lgb_pre = build_model_lgb(X_data,Y_data)
subA_lgb = model_lgb_pre.predict(X_test)
print('Sta of Predict lgb:')
Sta_inf(subA_lgb)
print('Train xgb...')
model_xgb = build_model_xgb(x_train,y_train)
val_xgb = model_xgb.predict(x_val)
MAE_xgb = mean_absolute_error(y_val,val_xgb)
print('MAE of val with xgb:',MAE_xgb)
print('Predict xgb...')
model_xgb_pre = build_model_xgb(X_data,Y_data)
subA_xgb = model_xgb_pre.predict(X_test)
print('Sta of Predict xgb:')
Sta_inf(subA_xgb)
4.4进行两模型的结果加权融合
## 这里我们采取了简单的加权融合的方式
val_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*val_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*val_xgb
val_Weighted[val_Weighted<0]=10 # 由于我们发现预测的最小值有负数,而真实情况下,price为负是不存在的,由此我们进行对应的后修正
print('MAE of val with Weighted ensemble:',mean_absolute_error(y_val,val_Weighted))
sub_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*subA_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*subA_xgb
## 查看预测值的统计进行
plt.hist(Y_data)
plt.show()
plt.close()
4.5.输出结果
sub = pd.DataFrame()
sub['SaleID'] = TestA_data.SaleID
sub['price'] = sub_Weighted
sub.to_csv('./sub_Weighted.csv',index=False)
sub.head()
5. 项目详细展开
因篇幅内容限制,将原学习项目拆解成多个notebook方便学习,只需一键fork。
5.1 数据分析详解
- 载入各种数据科学以及可视化库:
- 数据科学库 pandas、numpy、scipy;
- 可视化库 matplotlib、seabon;
- 其他;
- 载入数据:
- 载入训练集和测试集;
- 简略观察数据(head()+shape);
- 数据总览:
- 通过describe()来熟悉数据的相关统计量
- 通过info()来熟悉数据类型
- 判断数据缺失和异常
- 查看每列的存在nan情况
- 异常值检测
- 了解预测值的分布
- 总体分布概况(无界约翰逊分布等)
- 查看skewness and kurtosis
- 查看预测值的具体频数
- 特征分为类别特征和数字特征,并对类别特征查看unique分布
- 数字特征分析
- 相关性分析
- 查看几个特征得 偏度和峰值
- 每个数字特征得分布可视化
- 数字特征相互之间的关系可视化
- 多变量互相回归关系可视化
- 类型特征分析
- unique分布
- 类别特征箱形图可视化
- 类别特征的小提琴图可视化
- 类别特征的柱形图可视化类别
- 特征的每个类别频数可视化(count_plot)
- 用pandas_profiling生成数据报告
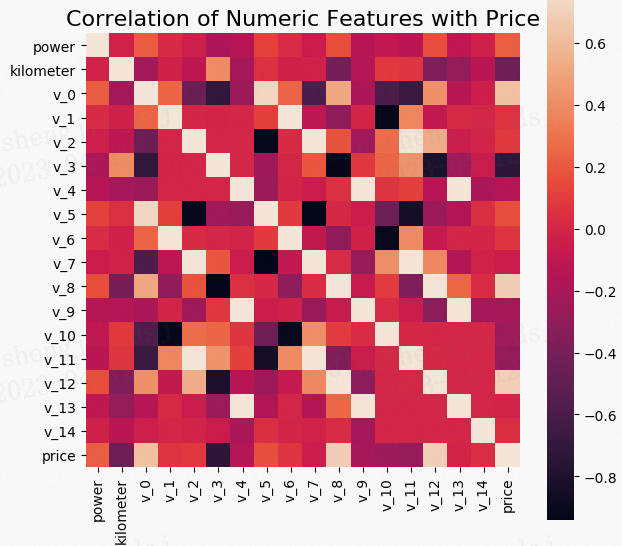
5.2 特征工程
- 异常处理:
- 通过箱线图(或 3-Sigma)分析删除异常值;
- BOX-COX 转换(处理有偏分布);
- 长尾截断;
- 特征归一化/标准化:
- 标准化(转换为标准正态分布);
- 归一化(抓换到 [0,1] 区间);
- 针对幂律分布,可以采用公式: $log(\frac{1+x}{1+median})$
- 数据分桶:
- 等频分桶;
- 等距分桶;
- Best-KS 分桶(类似利用基尼指数进行二分类);
- 卡方分桶;
- 缺失值处理:
- 不处理(针对类似 XGBoost 等树模型);
- 删除(缺失数据太多);
- 插值补全,包括均值/中位数/众数/建模预测/多重插补/压缩感知补全/矩阵补全等;
- 分箱,缺失值一个箱;
- 特征构造:
- 构造统计量特征,报告计数、求和、比例、标准差等;
- 时间特征,包括相对时间和绝对时间,节假日,双休日等;
- 地理信息,包括分箱,分布编码等方法;
- 非线性变换,包括 log/ 平方/ 根号等;
- 特征组合,特征交叉;
- 仁者见仁,智者见智。
- 特征筛选
- 过滤式(filter):先对数据进行特征选择,然后在训练学习器,常见的方法有 Relief/方差选择发/相关系数法/卡方检验法/互信息法;
- 包裹式(wrapper):直接把最终将要使用的学习器的性能作为特征子集的评价准则,常见方法有 LVM(Las Vegas Wrapper) ;
- 嵌入式(embedding):结合过滤式和包裹式,学习器训练过程中自动进行了特征选择,常见的有 lasso 回归;
- 降维
- PCA/ LDA/ ICA;
- 特征选择也是一种降维。
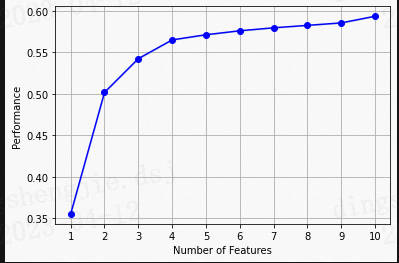
5.3 模型优化
- 线性回归模型:
- 线性回归对于特征的要求;
- 处理长尾分布;
- 理解线性回归模型;
- 模型性能验证:
- 评价函数与目标函数;
- 交叉验证方法;
- 留一验证方法;
- 针对时间序列问题的验证;
- 绘制学习率曲线;
- 绘制验证曲线;
- 嵌入式特征选择:
- Lasso回归;
- Ridge回归;
- 决策树;
- 模型对比:
- 常用线性模型;
- 常用非线性模型;
- 模型调参:
- 贪心调参方法;
- 网格调参方法;
- 贝叶斯调参方法;
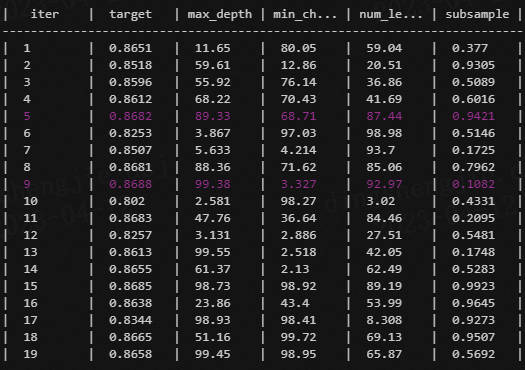
5.4模型融合
简单加权融合:
- 回归(分类概率):算术平均融合(Arithmetic mean),几何平均融合(Geometric mean);
- 分类:投票(Voting)
- 综合:排序融合(Rank averaging),log融合
stacking/blending:
- 构建多层模型,并利用预测结果再拟合预测。
boosting/bagging(在xgboost,Adaboost,GBDT中已经用到):
- 多树的提升方法
训练:

预测:

6.总结
二手车预测项目是非常经典项目,数据挖掘实践(二手车价格预测)的内容来自 Datawhale与天池联合发起的,现在通过整理和调整让更多对机器学习感兴趣可以上手实战一下
因篇幅内容限制,将原学习项目拆解成多个notebook方便学习,只需一键fork。
项目链接:
一键fork直接运行,所有项目码源都在里面
https://www.heywhale.com/mw/project/64367e0a2a3d6dc93d22054f
机器学习数据挖掘专栏:
https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc
参考链接:
https://github.com/datawhalechina/team-learning-data-mining/tree/master/SecondHandCarPriceForecast
【机器学习入门与实践】数据挖掘-二手车价格交易预测(含EDA探索、特征工程、特征优化、模型融合等)的更多相关文章
- 机器学习入门实战——基于knn的airbnb房租预测
数据读取 import pandas as pd features=['accommodates','bathrooms','bedrooms','beds','price','minimum_nig ...
- 二手车价格预测 | 构建AI模型并部署Web应用 ⛵
作者:韩信子@ShowMeAI 数据分析实战系列:https://www.showmeai.tech/tutorials/40 机器学习实战系列:https://www.showmeai.tech/t ...
- 【机器学习PAI实践一】搭建心脏病预测案例
一.背景 心脏病是人类健康的头号杀手.全世界1/3的人口死亡是因心脏病引起的,而我国,每年有几十万人死于心脏病. 所以,如果可以通过提取人体相关的体侧指标,通过数据挖掘的方式来分析不同特征对于心脏病的 ...
- 机器学习入门 - Google机器学习速成课程 - 笔记汇总
机器学习入门 - Google机器学习速成课程 https://www.cnblogs.com/anliven/p/6107783.html MLCC简介 前提条件和准备工作 完成课程的下一步 机器学 ...
- 零基础入门数据挖掘——二手车交易价格预测:baseline
零基础入门数据挖掘 - 二手车交易价格预测 赛题理解 比赛要求参赛选手根据给定的数据集,建立模型,二手汽车的交易价格. 赛题以预测二手车的交易价格为任务,数据集报名后可见并可下载,该数据来自某交易平台 ...
- Azure机器学习入门(三)创建Azure机器学习实验
在此动手实践中,我们将在Azure机器学习Studio中一步步地开发预测分析模型,首先我们从UCI机器学习库的链接下载普查收入数据集的样本并开始动手实践: http://archive.ics.uci ...
- odoo:开源 ERP/CRM 入门与实践 -- 上海嘉冰信息技术公司提供咨询服务
odoo:开源 ERP/CRM 入门与实践 看了这张图,或许你对odoo有了一些兴趣. 这次Chat就是和大家一起交流开源ERP/CRM系统:odoo 对以下读者有帮助:研发.产品.项目.市场.服务. ...
- Python数据分析入门与实践 ✌✌
Python数据分析入门与实践 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 这是一个数据驱动的时代,想要从事机器学习.人工智能.数据挖掘等前沿技术,都离不开 ...
- Azure机器学习入门(二)创建Azure机器学习工作区
我们将开始深入了解如何使用Azure机器学习的基本功能,帮助您开始迈向Azure机器学习的数据科学家之路. Azure ML Studio (Azure Machine Learning Studio ...
- 机器学习入门09 - 特征组合 (Feature Crosses)
原文链接:https://developers.google.com/machine-learning/crash-course/feature-crosses/ 特征组合是指两个或多个特征相乘形成的 ...
随机推荐
- Spring Boot中使用过滤器和拦截器
过滤器(Filter)和拦截器(Interceptor)是Web项目中常用的两个功能,本文将简单介绍在Spring Boot中使用过滤器和拦截器来计算Controller中方法的执行时长,并且简单对比 ...
- 使用git&GitHub通过两台电脑协同作业,助力办公室摸鱼
前情提要:工作有时候负荷比较小,会接一些咸鱼上的活儿或者自己学点软件技能,这时候会出现一个情况,公司笔记本一般不带回家,家里台式机,白天在公司摸鱼编辑的文件,晚上回家想接着干怎么办呢,或是晚上在家干的 ...
- python 编程找出矩阵中的幸运数字:说明,在一个给定的M*N的矩阵(矩阵中的取值0-1024,且各不相同),如果某一个元素的值在同一行中最小,并且在同一列中元素最大,那么该数字为幸运数字。
假设给定矩阵如下: matrix=[[10,36,52], [33,24,88], [66,76,99]] 那么输出结果应为66(同时满足条件) 代码如下: arr=[[10,36,52], [33, ...
- 优先使用C++的别名声明(using)来替换typedef
C++98中,我们如果想用简写的方式表达一个类型,那么可以使用typedef关键字: typedef std::unique_ptr<std::unordered_map<std::str ...
- java 线程池 带返回值
import java.util.concurrent.ExecutionException;import java.util.concurrent.ExecutorService;import ja ...
- jmeter-脚本制作
HTTP请求 默认端口号 HTTP默认端口号:80 HTTPS默认端口:443 数据来源 通过网络抓包软件(Fiddler.Charles等).接口文档数据 脚本制作+结果 录制脚本 badbod 录 ...
- C/C++ 数据结构顺序栈的基本操作实现
#include <iostream> #include <Windows.h> using namespace std; #define MAXSIZE 6 //顺序栈的实现 ...
- EL_获取域中存储的值_ List 集合&Map集合值和EL _ empty 运算符&隐式对象 pageContext
3.获取对線. List 集合. Map 集合的值 1.对線:${域名称,键名.属性名}本质上会去调用对線的 getter 方法 2. List 集合:${域名称.键名[索引]} List list ...
- Linux调用python文件的同时传参
创建python文件内容如下: 计算两个数相加并打印,需要传递两个参数 vi sum.py import sys def calc(a,b): c=a+b return c a1=int(float( ...
- input number类型去掉箭头和禁用滚轮
input number类型可以输入整型.浮点型.科学计数法的数据 禁用滚轮,在input标签内添加onmouseWheel="return false" <input ty ...