D2-Net: Weakly-Supervised Action Localization via Discriminative Embeddings and Denoised Activations概述
1.针对的问题
目前大多数弱监督动作定位方法通常依赖于分离前景和背景区域(前-背景分离)学习TCAMs,但是在弱监督设置下,学习到的TCAM会存在噪声,而这些方法并没有明确地处理其噪声输出。
2.主要贡献
•引入了一个判别损失项,它同时进行视频分类和增强的前背景分离。
•引入去噪损失项来提高TCAMs的鲁棒性。去噪损失通过最大化视频内(intra-video)和视频间(inter-video)激活和标签之间的MI,明确解决了TCAM中的噪声问题。第一个引入了一个损失项,同时捕获一个视频中的多个片段和一个batch中所有视频的MI,以进行弱监督动作定位。
•在多个基准上进行实验,包括THUMOS14[7]和ActivityNet1.2[3]。D2-Net在所有数据集上优于现有的弱监督方法,在THUMOS14上IoU=0.5获得高达2.3% mAP的增益。
3.方法
模型结构比较简单,主要创新点在于提出的损失函数。
提出了两个损失项:判别损失和去噪损失。判别损失通过使用从输出T-CAMs计算的自顶向下的注意力,寻求最大程度地分离前景和背景片段并解决类别平衡问题。去噪损失通过处理激活中的前背景噪声来改善T-CAMs。这种损失使用来自潜在嵌入的前景得分的自底向上的注意力。
判别损失LDis:
首先通过自顶向下注意力计算前景嵌入和背景嵌入,公式如下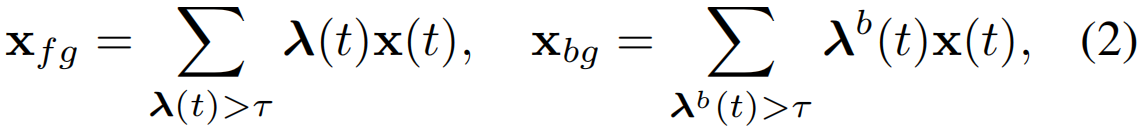
λb(t)=1−λ(t)是背景注意力。此外,引入了三个权重项wfb,wfg和wbg,分别针对分离前景和背景,聚合前景及聚合背景。
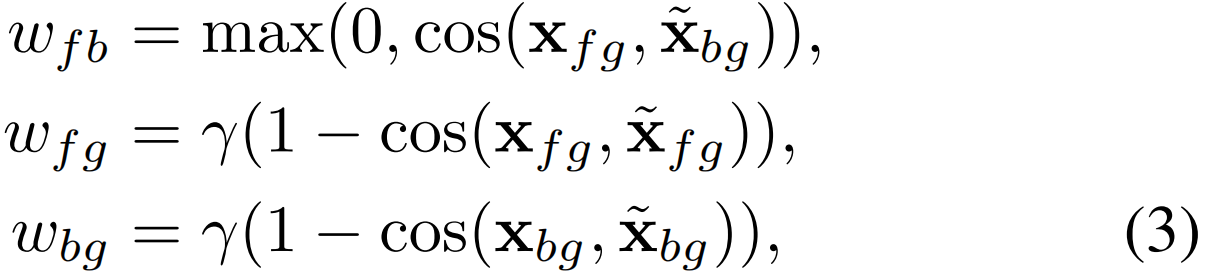
x和 表示来自mini-batch中不同视频的嵌入,判别损失的另一个作用是解决类别平衡问题,即简单的背景片段的数量远远超过了困难的前景。受focal loss的启发,作者在判别损失中加入基于上面计算出来的权重的惩罚项。则判别损失定义如下:
表示来自mini-batch中不同视频的嵌入,判别损失的另一个作用是解决类别平衡问题,即简单的背景片段的数量远远超过了困难的前景。受focal loss的启发,作者在判别损失中加入基于上面计算出来的权重的惩罚项。则判别损失定义如下:
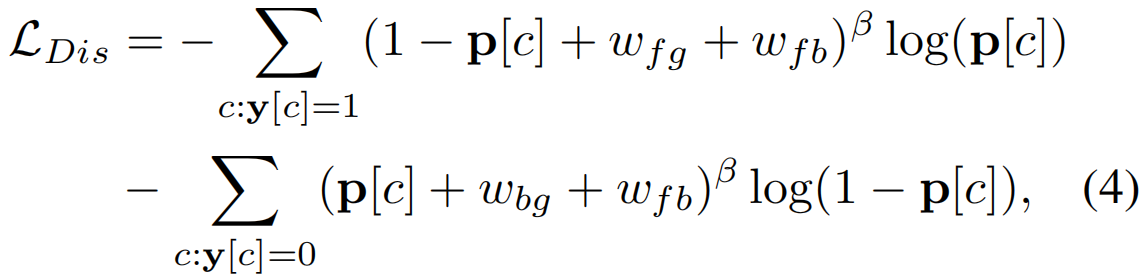
视频级预测p∈RC通过对T进行时序top-k池化获得,第一项表示只有当(i)其预测概率p[c]较高,以及(ii)对应视频的前景分组wfg和前景-背景分离wfb同时较低时,阳性动作类c造成的损失才较低。类似的观察也适用于第二项对负类的观察。因此,LDis通过鼓励前景-背景分离,同时实现分类,提高了嵌入x(t)的可辨别性。
去噪损失LD:
基于DMI(基于行列式的互信息)提出,用于提升对于噪声数据的鲁棒性,DMI是为多类分类提出的,计算为联合分布矩阵的行列式,即DMI(P, Y)=|det(U)|,U = 1/nPY是预测后验概率P和ground-truth (有噪声)标签Y的联合分布,DMI损失Ldmi被定义为
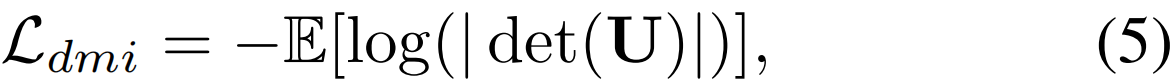
但是这种定义存在问题,Ldmi依赖于U的行列式,为了确保det(U)非零,标签矩阵Y必须是满秩的,即mini-batch必须包含所有类的实例。对于大量的类来说,这是不可行的。这种用于动作定位的mini-batch采样也会导致gpu中的内存问题。
根据公式,若要使Ldmi趋于0,则|det(U)|应趋于1,即U趋于单位矩阵,作者通过实验发现,若用ηU表示U的条件数,当|det(U)|越大,ηU越小,且当|det(U)|趋于1时,ηU也趋于1,因此作者对式5进行了修改,得到Lpdmi
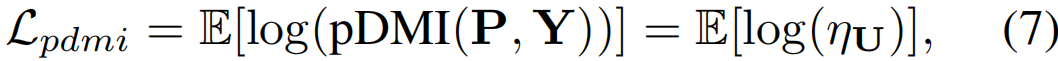
ηU计算为σ1/σr,其中{σ1,…,σr}为U的非零奇异值。
Lpdmi既用于一个视频的片段之间,也用于一个batch的所有视频之间,由于弱监督中得到的P和Y是视频级的,所以作者构造了片段的预测矩阵P1和伪标签矩阵Y1。先通过一种自底向上的注意力机制计算前景分数λ'(t)
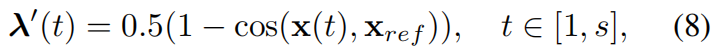
x[m]ref=0.9x[m−1]ref+0.1xµ,[m]bg逐步计算为xbg在m次迭代中的运行平均值。这里,xµ,[m]bg表示迭代m时一个MIni-batch中背景嵌入的平均值。令tf={t:λ'(t)>0.5}和tb={t:λ'(t)<0.5}。使用伪前景时序定位tf,一个宽度为nf=|tf|的行矩阵λf通过自顶向下注意力λ(t), t∈tf构造 。同样, 宽度为nb=|tb|的λb为伪背景片段构造。
则预测矩阵P1和伪标签矩阵Y1计算为
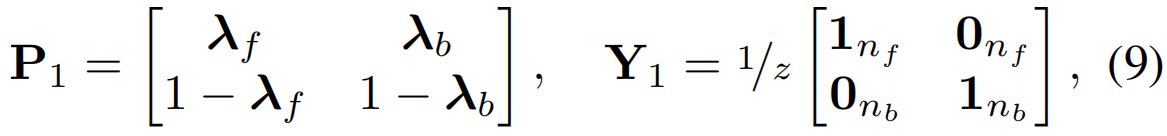
模型总体架构如下:
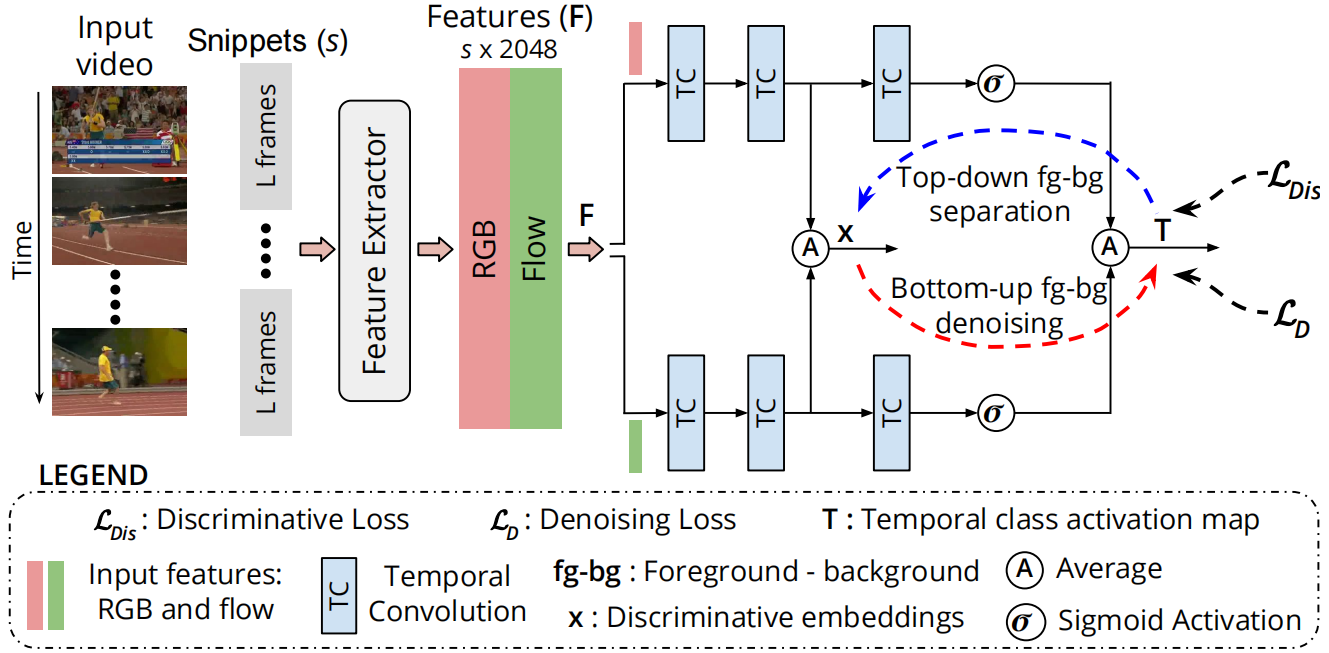
给定一个视频v,把它分成L = 16帧的互不重叠的片段。使用I3D获得每个16帧片段的d = 2048维特征F∈Rs×d,s为片段数,将特征输入D2-Net。
D2-Net由两个并行的RGB流和光流组成。每个流由三个时序卷积(TC)层组成。前两层从输入特征F学习潜在判别嵌入x(t)∈Rd/2(时间t∈[1,s]),最终TC层的输出通过sigmoid激活。随后,对两个流的输出进行平均,得到TCAMs T∈Rs×C 表示C个动作类随时间变化的class-specific得分序列。训练目标结合了判别(LDis)和去噪项(LD),并使用了一个平衡权重α。
D2-Net: Weakly-Supervised Action Localization via Discriminative Embeddings and Denoised Activations概述的更多相关文章
- [CVPR2017] Deep Self-Taught Learning for Weakly Supervised Object Localization 论文笔记
http://openaccess.thecvf.com/content_cvpr_2017/papers/Jie_Deep_Self-Taught_Learning_CVPR_2017_paper. ...
- [CVPR2017] Weakly Supervised Cascaded Convolutional Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #042eee } p. ...
- Background Suppression Network for Weakly-supervised Temporal Action Localization [Paper Reading]
研究内容:弱监督时域动作定位 结果:Thumos14 mAP0.5 = 27.0 ActivityNet1.3 mAP0.5 = 34.5 从结果可以看出弱监督这种瞎猜的方式可以PK掉早些时候的一些全 ...
- [CVPR 2016] Weakly Supervised Deep Detection Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- 2018年发表论文阅读:Convolutional Simplex Projection Network for Weakly Supervised Semantic Segmentation
记笔记目的:刻意地.有意地整理其思路,综合对比,以求借鉴.他山之石,可以攻玉. <Convolutional Simplex Projection Network for Weakly Supe ...
- Robust Tracking via Weakly Supervised Ranking SVM
参考文献:Yancheng Bai and Ming Tang. Robust Tracking via Weakly Supervised Ranking SVM Abstract 通常的算法:ut ...
- [place recognition]NetVLAD: CNN architecture for weakly supervised place recognition 论文翻译及解析(转)
https://blog.csdn.net/qq_32417287/article/details/80102466 abstract introduction method overview Dee ...
- [ICCV 2019] Weakly Supervised Object Detection With Segmentation Collaboration
新在ICCV上发的弱监督物体检测文章,偷偷高兴一下,贴出我的poster,最近有点忙,话不多说,欢迎交流- https://arxiv.org/pdf/1904.00551.pdf http://op ...
- A brief introduction to weakly supervised learning(简要介绍弱监督学习)
by 南大周志华 摘要 监督学习技术通过学习大量训练数据来构建预测模型,其中每个训练样本都有其对应的真值输出.尽管现有的技术已经取得了巨大的成功,但值得注意的是,由于数据标注过程的高成本,很多任务很难 ...
- 论文笔记(7):Constrained Convolutional Neural Networks for Weakly Supervised Segmentation
UC Berkeley的Deepak Pathak 使用了一个具有图像级别标记的训练数据来做弱监督学习.训练数据中只给出图像中包含某种物体,但是没有其位置信息和所包含的像素信息.该文章的方法将imag ...
随机推荐
- 右键无法新建word文件怎么办?
电脑用久了,总会出现奇奇怪怪的问题. 我最近遇到一个问题:鼠标右键无法新建word文件.如何解决此问题呢? 刚开始,我忍了.解决方法为:把word图标固定到任务栏,就好了呗,需要用的时候, ...
- swagger TypeError: Failed to fetch
最近开发一个项目,项目接口规范是swagger,初次使用swagger遇见很多问题,通过写博记录在项目中遇见的swagger各种情况 我项目中解决方法: 改为: 需要与自己在laravel 框架中e ...
- springboot上传文件失败:The temporary upload location [/tmp/tomcat.7112002115745457830.8765/work/Tomcat/localhost/ROOT] is not valid
字面意思就是上传的临时目录不存在,问题就是linux系统会自动清理tmp目录下超过10天没有任何操作的目录或文件 解决办法 1.重启springboot服务,当然这只是暂时的,下次隔太久一样会失效 2 ...
- 【SSO单点系列】(7):CAS4.0 二级域名
CAS4.0 二级域名 一.描述 当cas成功登录后如果访问同一域名下的资源是 被当作同一应用下资源不需要再次请求登录,但是如果二级域名不同会 被当作不同应用在访问 需要请求CAS 在请求时会把TGC ...
- 关于certutil的探究-文件下载+编码分块上传上传文件再合并
何为certutil certutil.exe 是一个合法Windows文件,用于管理Windows证书的程序. 微软官方是这样对它解释的: Certutil.exe是一个命令行程序,作为证书服务的一 ...
- node 版本管理器 nvs
node 总是在不断的升级,以前老项目在运行时可能会报错 我遇到了一个 PostCSS received undefined instead of CSS string 查了下可能是node-sass ...
- 25 String 对象中的属性
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF ...
- flutter CustomScrollView多个滑动组件嵌套
CustomScrollView是使用Sliver组件创建自定义滚动效果的滚动组件.使用场景: ListView和GridView相互嵌套场景,ListView嵌套GridView时,需要给GridV ...
- Java多线程编程技术方案原理
一 ,多线程相关的一些概念 1,线程和进程: 线程指的是进程中一个单一顺序的控制流, 进程中可以并发多个线程,每条线程并行执行不同的任务,被认为是一个计算资源的集合.进程不能被任务是一个应用,因为有些 ...
- 在C#中Release与Debug的区别小案例
我们都听说过C#写的代码 Release通常会比Debug性能要好一点跑得快一些. 先普及一些相关基础知识: (1)在CLR中将对sbyte.byte.short.ushort.int.uint.ch ...