什么是hive
Hadoop Hive概念学习系列之什么是Hive?
参考 《Hadoop大数据分析与挖掘实战》的在线电子书阅读
http://yuedu.baidu.com/ebook/d128cf8e33687e21ae45a935?pn=1&click_type=10010002
Hive最初是应Facebook每天产生的海量新兴社会网络数据进行管理和机器学习的需求而产生和发展的,是建立在Hadoop上的数据仓库基础构架。作为Hadoop的一个数据仓库工具,Hive可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能。
Hive作为构建在Hadoop之上的数据仓库,它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,成为HQL,它允许熟悉SQL的用户查询数据。因此,该语言也允许熟悉MapReduce的开发者开发自定义的Mapper和Reducer来处理内建的Mapper和Reducer无法完成的复杂的分析工作。
Hive没有专门的数据格式。Hive可以很好地工作在Thrift(是个服务器)之上,控制分隔符,也允许用户指定数据格式。
Hive具有以下特点:
.支持索引,加快数据查询。
.不同的存储类型,如纯文本文件、HBase中的文件。
.将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
如, 2 hive的使用 + hive的常用语法 里的.hive的常用语法
.可以直接使用存储在Hadoop文件系统中的数据。
如, 2 hive的使用 + hive的常用语法 里的.hive的常用语法
.内置大量用户函数UDF来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF函数来完成内置函数无法实现的操作。
如, 3 hql语法及自定义函数 里的 .hive自定义函数
.类SQL的查询方式,将SQL查询转换为MapReducer的Job在Hadoop集群上执行。
Hive构建在基于静态批处理的Hadoop之上,Hadoop通常都有较高的延迟并且在作业提交和调度时需要大量的开销。因此,Hive并不能够在大规模数据集上实现低延迟快速的查询。例如,Hive在几百MB的数据集上执行查询一般有分钟级的时间延迟。因此,Hive并不适合那些需要低延迟的应用,如联机事务处理(OLTP)。Hive查询操作过程严格遵守Hadoop MapReduce的作业执行模型,Hive将用户的HiveQL语句通过解释器转换为MapReduce作业提交到Hadoop集群上,Hadoo监控作业执行过程,然后返回作业执行结果给用户。Hive并非为联机事务处理而设计,Hive并不提供实时的查询和基于行级的数据更新操作。
Hive的最佳使用场合是大数据集的批处理作业,如网络日志分析。
Hive的架构

图1 Hive的架构
从图1中可以看到,Hive包含用户访问接口(CLI、JDBC/ODBC、GUI和Thrift Server)、元数据存储(Metastore)、驱动组件(包括编译、优化、执行驱动)。
用户访问接口即用户用来访问Hive数据仓库所使用的工具接口。
CLI(command line interface)即命令行接口。
Thrift Server是Facebook开发的一个软件框架,它用来开发可扩展且跨语言的服务,Hive集成了该服务,能让不同的编程语言调用Hive的接口。
Hive客户端提供了通过网页的方式访问Hive提供的服务,这个接口对应Hive的HWI组件(Hive web interface),使用前要启动HWI服务。
Metastore是Hive中的元数据存储,主要存储Hive中的元数据,包括表的名称、表的列和分区及其属性、表的属性(是否为外部表等)、表的数据所在目录等,一般使用MySQL或Derby数据库。
Metastore和Hive Driver驱动的互联有两种方式,一种是集成模式,如图2所示;一种是远程模式,如图3所示。
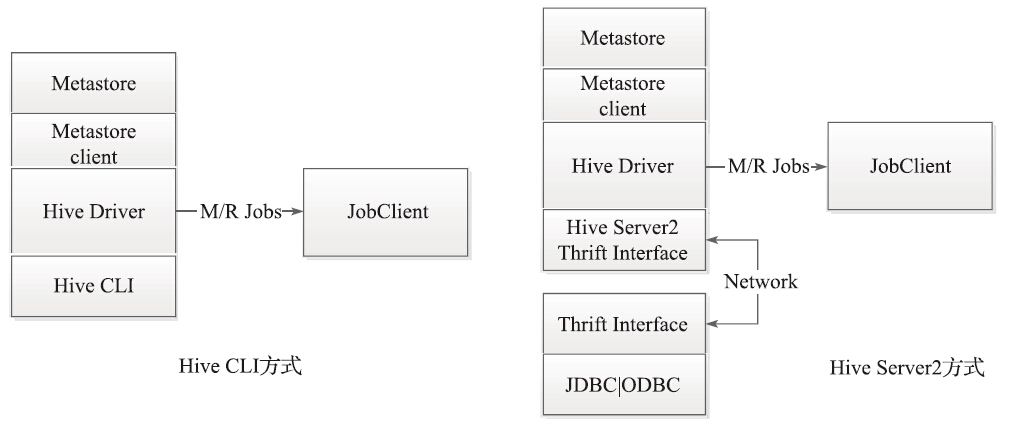
图2 Metastore 和 Driver通信(集成模式)

图3 Metastore 和 Driver通信(远程模式)
什么是hive的更多相关文章
- 初识Hadoop、Hive
2016.10.13 20:28 很久没有写随笔了,自打小宝出生后就没有写过新的文章.数次来到博客园,想开始新的学习历程,总是被各种琐事中断.一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版 ...
- Hive安装配置指北(含Hive Metastore详解)
个人主页: http://www.linbingdong.com 本文介绍Hive安装配置的整个过程,包括MySQL.Hive及Metastore的安装配置,并分析了Metastore三种配置方式的区 ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- HIVE教程
完整PDF下载:<HIVE简明教程> 前言 Hive是对于数据仓库进行管理和分析的工具.但是不要被“数据仓库”这个词所吓倒,数据仓库是很复杂的东西,但是如果你会SQL,就会发现Hive是那 ...
- 基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库.前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集. 1.安装MySQL 1.1安装MySQL ...
- hive
Hive Documentation https://cwiki.apache.org/confluence/display/Hive/Home 2016-12-22 14:52:41 ANTLR ...
- 深入浅出数据仓库中SQL性能优化之Hive篇
转自:http://www.csdn.net/article/2015-01-13/2823530 一个Hive查询生成多个Map Reduce Job,一个Map Reduce Job又有Map,R ...
- Hive读取外表数据时跳过文件行首和行尾
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 有时候用hive读取外表数据时,比如csv这种类型的,需要跳过行首或者行尾一些和数据无关的或者自 ...
- Hive索引功能测试
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 从Hive的官方wiki来看,Hive0.7以后增加了一个对表建立index的功能,想试下性能是 ...
- 轻量级OLAP(二):Hive + Elasticsearch
1. 引言 在做OLAP数据分析时,常常会遇到过滤分析需求,比如:除去只有性别.常驻地标签的用户,计算广告媒体上的覆盖UV.OLAP解决方案Kylin不支持复杂数据类型(array.struct.ma ...
随机推荐
- Checked异常和Runtime异常体系
Java的异常被分为两大类:Checked异常和Runtime异常(运行时异常).所有的RuntimeException类及其子类的实例被称为Runtime异常:不是RuntimeException类 ...
- Linux静态库与动态库详解
引言 为了代码的复用性和模块化,我们常常使用一些库文件,在Windows操作系统下位.lib .dll作为静态库和动态库的后缀名. 在Linux下,静态链接库名字一般为libabcdef.a,其中ab ...
- python 多继承详解-乾颐堂
1 2 3 4 5 6 7 8 9 10 class A(object): # A must be new-style class def __init__(self): prin ...
- 利用crosstool-ng自动化编译交叉编译环境(转)
原文地址:http://www.bootc.net/archives/2012/05/26/how-to-build-a-cross-compiler-for-your-raspberry-pi/ A ...
- 3.1.5 倒计时器:CountDownLatch
package 第三章.倒计时器CountDownLatch; import java.util.concurrent.CountDownLatch; /** * Created by zzq on ...
- spring-boot-maven-plugin插件作用
转自:http://blog.csdn.net/hotdust/article/details/51404828 OM 文件中添加了“org.springframework.boot:spring-b ...
- ceph的image扩容
root@ceph01:/etc/ceph# rbd create --size 1024 test root@ceph01:/etc/ceph# root@ceph01:/etc/ceph# roo ...
- python之CSV文件格式
1.csv文件是以一些以逗号分隔的值 import csv filename = "wenjian.csv" with open(filename) as f: reader = ...
- CSS 实现等高布局以及多行文本垂直居中
将display属性设置为table-cell,具有table的特点. 1.同行等高. 2.宽度自动调节. 相当于表格是td, <style type="text/css"& ...
- JPA和Hibernate的相关使用技巧
介绍 尽管有SQL标准,但每个关系数据库终将是唯一的,因此你需要调整数据访问层,以便充分利用在使用中的关系数据库. 在本文中,我们将介绍在使用带有JPA和Hibernate的MySQL时,为了提高性能 ...