6、DRN-----深度强化学习在新闻推荐上的应用
1、摘要:
提出了一种新的深度强化学习框架的新闻推荐。由于新闻特征和用户喜好的动态特性,在线个性化新闻推荐是一个极具挑战性的问题。
虽然已经提出了一些在线推荐模型来解决新闻推荐的动态特性,但是这些方法主要存在三个问题:①只尝试模拟当前的奖励(eg:点击率)②很少考虑使用除了点击 / 不点击标签之外的用户反馈来帮助改进推荐。③ 这些方法往往会向用户推荐类似消息,这可能会导致用户感到厌烦。
基于深度强化学习的推荐框架,该框架可以模拟未来的奖励(点击率)
2、引言:
新闻推荐三个问题:
(1)新闻推荐的动态变化是难以处理的。
(2)用户的兴趣可能随着时间的变化而变化。
(3)创新
强化学习:假定一个智能体(agent),在一个未知的环境中(当前状态state),采取了一个行动(action),然后收获了一个回报(reward),并进入了下一个状态。最终目的是求解一个策略让agent的回报最大化。
因此,本文提出了基于深度强化学习的推荐系统框架来解决上述提到的三个问题:
(1)首先,使用DQN网络来有效建模新闻推荐的动态变化属性,DQN可以将短期回报和长期回报进行有效的模拟。
(2)将用户活跃度作为一种新的反馈信息。
(3)使用Dueling Bandit Gradient Descent 方法来进行有效的探索。
算法的框架如下图所示:
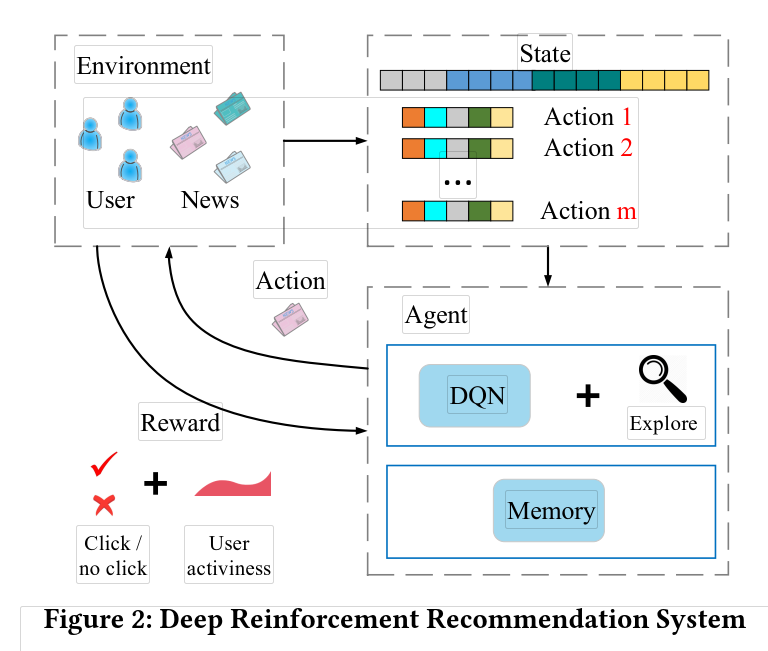
3、问题描述:
当一个用户 u 在时间 t 向推荐系统 G 发送一个新闻请求,系统会利用一个给定的新闻候选集 I 给用户推荐一个 top-k 列表给用户。
4、模型方法:
4.1 整体架构图:
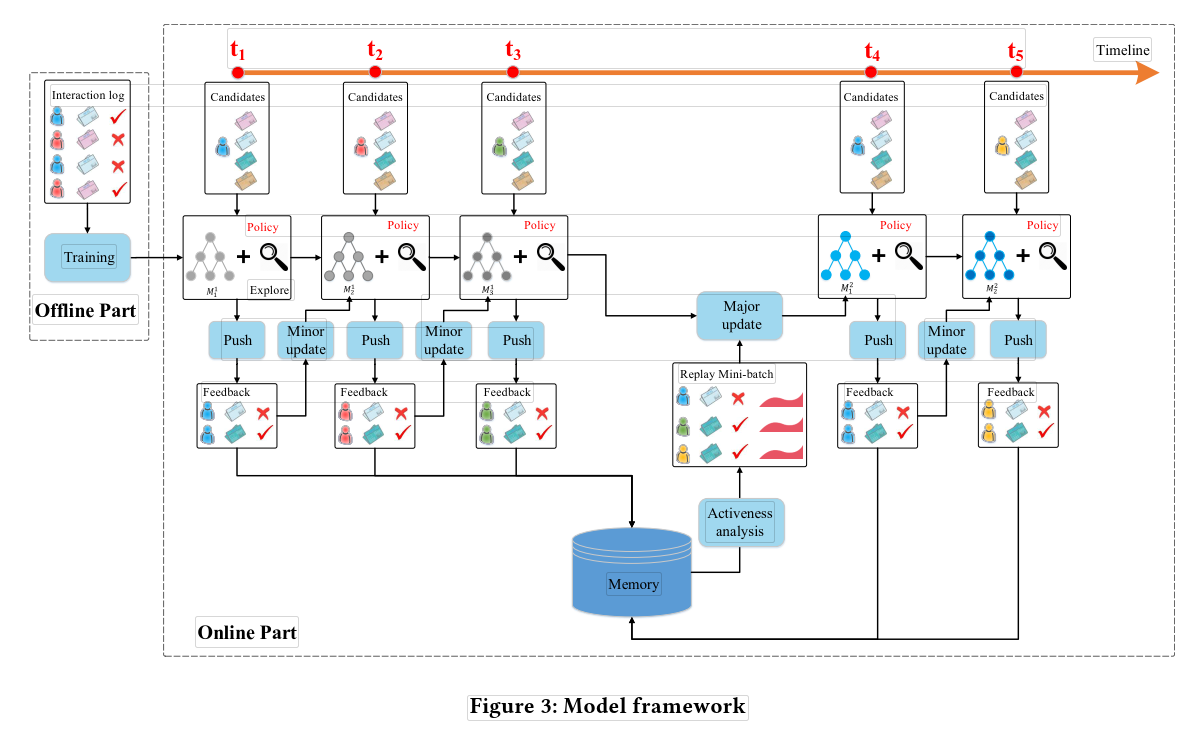
几个关键环节:
push:在每一个时刻,用户发送请求时,agent根据当前的state产生k篇新闻推荐给用户。
Feedback:通过用户对推荐新闻的点击行为得到反馈结果。
minor update:在每个时间点过后,根据用户的信息(state)和推荐的新闻(action)以及得到的反馈(reward),更新参数。
major update:在一段时间后,根据DQN的经验池中存放的历史经验,对模型参数进行更新。
6、DRN-----深度强化学习在新闻推荐上的应用的更多相关文章
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
- 深度强化学习中稀疏奖励问题Sparse Reward
Sparse Reward 推荐资料 <深度强化学习中稀疏奖励问题研究综述>1 李宏毅深度强化学习Sparse Reward4 强化学习算法在被引入深度神经网络后,对大量样本的需求更加 ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
- 深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods)
深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods) 2018-07-17 16:50:12 Reference:https://www.you ...
随机推荐
- Tomcat转jboss踩的那些坑
问题背景 今天发版本,是一个httpclient的跳转(由于公司网络原因,所以对外网的访问都经过这个代理服务出去). 问题原因 之前的开发一直在window系统的tomcat服务器上进行的,对jbos ...
- 火狐浏览器下载文件中文乱码,文件名中的空格变加号("+")的问题
解决一下问题: 1.火狐浏览器下载文件,中文变乱码 2.IE浏览器下载文件,丢失文件扩展名或强制扩展名为".txt" 3.浏览器下载文件,文件名中的空格变成加号("+&q ...
- J2EE概念汇总
JVM 是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的.Java虚拟 ...
- LeetCode Golang 2. 两数相加
2. 两数相加 给出两个 非空 的链表用来表示两个非负的整数.其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字. 如果,我们将这两个数相加起来,则会返回一个新的链 ...
- 利用Java反射机制对实体类的常用操作工具类ObjectUtil
代码: ObjectUtil类: import java.lang.reflect.Field; import java.math.BigDecimal; import java.text.Simpl ...
- 51nod 1302(贪心+平衡树)
能推出一些性质. 矩形肯定是全部躺着或全部立着比较优. 如图x1显然等于x2,y1显然小于y2. 所以我们就让它们都躺下吧. 然后一定有一组的宽为宽最小的矩形的宽. 然后我们枚举另一组的宽最小的矩形. ...
- JS数组中的indexOf方法
前言 这两天在家中帮朋友做项目,项目中使用了数组的indexOf 方法,找到了一篇文章,感觉非常不错,顺便整理下以防链接丢失. 相信说到 indexOf 大家并不陌生,判断字符串是否包涵子字符串时特别 ...
- 决策树(Decision Trees)
简介 决策树是一个预测模型,通过坐标数据进行多次分割,找出分界线,绘制决策树. 在机器学习中,决策树学习算法就是根据数据,使用计算机算法自动找出决策边界. 每一次分割代表一次决策,多次决策而形成决策树 ...
- ajax异步请求获取数据,实现滚动数字的效果。
BackgroundPositionAnimate.js下载 需要导入的js: <script type="text/javascript" src="js/jqu ...
- SQL SERVER-约束
NOT NULL - 指示某列不能存储 NULL 值. UNIQUE - 保证某列的每行必须有唯一的值. PRIMARY KEY - NOT NULL 和 UNIQUE 的结合.确保某列(或两个列多个 ...