Oracle SQL调优之分区表
一、分区表简介
分区通过让您将它们分解为更小且更易于管理的分区(称为分区)来解决支持非常大的表和索引的关键问题。不需要修改SQL查询和DML语句以访问分区表。但是,在定义分区之后,DDL语句可以访问和操作个别分区,而不是整个表或索引。这就是分区可以简化大型数据库对象的可管理性的方式。此外,分区对应用程序完全透明
其它类型的表设计可以看博客:https://smilenicky.blog.csdn.net/article/details/90315980
普通表和分区表区别,分区表分成几部分就有几个segment,RANGE_PART_TAB是一个分区表
select segment_name,
partition_name,
segment_type,
bytes / 1024 / 1024 "字节数(M)",
tablespace_name
from user_segments
where segment_name IN ('RANGE_PART_TAB', 'NOR_TAB');
二、分区表优势
引用Oracle官方文档的说法,https://docs.oracle.com/cd/B19306_01/server.102/b14220/partconc.htm#sthref2604:
(1) 分区支持数据管理操作,例如数据加载,索引创建和重建,以及分区级别的备份/恢复,而不是整个表。这导致这些操作的时间显着减少。
(2)分区可提高查询性能。在许多情况下,查询的结果可以通过访问分区的子集而不是整个表来实现。对于某些查询,此技术(称为分区 修剪)可以提供性能的数量级增益。
(3)分区可以显着减少计划停机对维护操作的影响。
(4)分区维护操作的分区独立性允许您在同一个表或索引的不同分区上执行并发维护操作。您还可以SELECT对不受维护操作影响的分区运行并发和DML操作。
(5)如果将关键表和索引划分为多个分区以减少维护窗口,恢复时间和故障影响,则分区可提高任务关键型数据库的可用性。
(6)无需对应用程序进行任何修改即可实现分区。例如,您可以将非分区表转换为分区表,而无需修改SELECT访问该表的任何语句或DML语句。您无需重写应用程序代码即可利用分区。
三、分区表分类
分区类型:分区分为范围分区、列表分区、HASH分区、组合分区四种,图来自Oracle官方网站
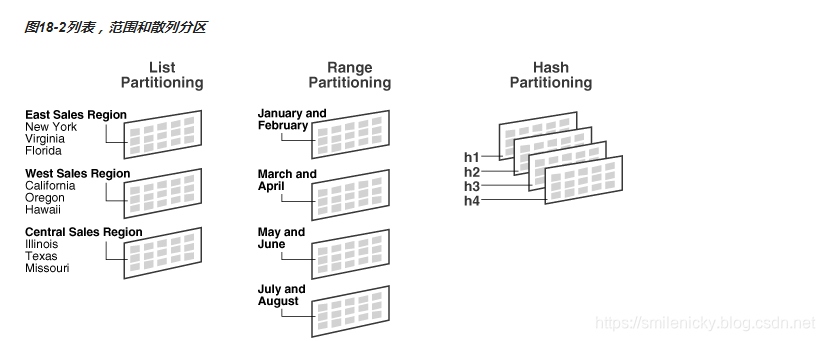
3.1 范围分区
关键字partition by range
create table range_part_tab (seq number,deal_date date,unit_code number,remark varchar2(100))
partition by range (deal_date)
(
partition p1 values less than (TO_DATE('2018-11-01','YYYY-MM-DD')),
partition p2 values less than (TO_DATE('2018-12-02','YYYY-MM-DD')),
partition p3 values less than (TO_DATE('2019-01-01','YYYY-MM-DD')),
partition p4 values less than (TO_DATE('2019-02-01','YYYY-MM-DD')),
partition p5 values less than (TO_DATE('2019-03-01','YYYY-MM-DD')),
partition p6 values less than (TO_DATE('2019-04-01','YYYY-MM-DD')),
partition p7 values less than (TO_DATE('2019-05-01','YYYY-MM-DD')),
partition p8 values less than (TO_DATE('2019-06-01','YYYY-MM-DD')),
partition p9 values less than (TO_DATE('2019-07-01','YYYY-MM-DD')),
partition p10 values less than (TO_DATE('2019-08-01','YYYY-MM-DD'))
);
insert into range_part_tab
(seq, deal_date, unit_code, remark)
select rownum,
to_date(to_char(sysdate-365, 'J') +
trunc(DBMS_RANDOM.value(0, 365)),'J'),
ceil(dbms_random.value(210,220)),
rpad('*', 1, '*')
from dual
connect by rownum <= 1000;
3.2 列表分区
create table list_part_tab (seq number,deal_date date,unit_code number,remark varchar2(100))
partition by list (unit_code)
(
partition p1 values (211),
partition p2 values (212),
partition p3 values (213),
partition p4 values (214),
partition p5 values (215),
partition p6 values (216),
partition p7 values (217),
partition p8 values (218),
partition p9 values (219),
partition p10 values (220),
partition p0 values (DEFAULT)
);
insert into list_part_tab
(seq, deal_date, unit_code, remark)
select rownum,
to_date(to_char(sysdate-365, 'J') +
trunc(DBMS_RANDOM.value(0, 365)),'J'),
ceil(dbms_random.value(210,220)),
rpad('*', 1, '*')
from dual
connect by rownum <= 1000;
commit;
3.3 散列分区
散列分区也叫hash分区,partitions后接分区数,尽量设置为偶数,
create table hash_part_tab (seq number,deal_date date,unit_code number,remark varchar2(100))
partition by hash (deal_date)
partitions 12;
insert into hash_part_tab
(seq, deal_date, unit_code, remark)
select rownum,
to_date(to_char(sysdate-365, 'J') +
trunc(DBMS_RANDOM.value(0, 365)),'J'),
ceil(dbms_random.value(210,220)),
rpad('*', 1, '*')
from dual
connect by rownum <= 1000;
commit;
3.4 组合分区
组合分区又称复合分区,主要有两种:oracle11之前只支持范围列表分区(RANGE-LIST)和范围散列分区(RANGE-HASH),oracle11之后支持(范围范围分区)RANGE-RANGE、 (列表范围分区)LIST-RANGE、(列表散列分区)LIST-HASH、(列表列表分区)LIST-LIST这几种组合,为了避免每个主分区中都写相同的从分区,可以用模板方式(subpartition template)
图来自Oracle官方网站:
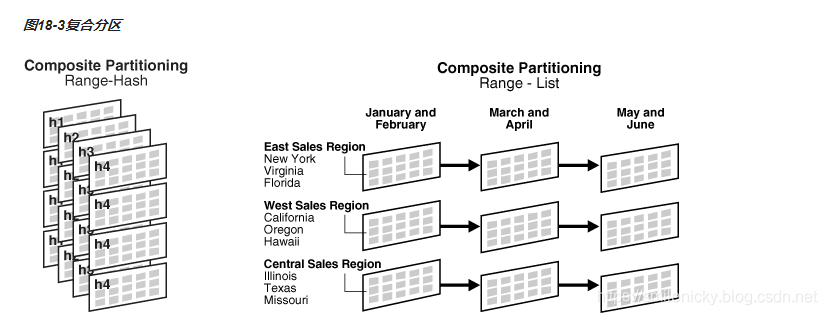
create table range_list_part_tab (seq number,deal_date date,unit_code number,remark varchar2(100))
partition by range (deal_date)
subpartition by list (unit_code)
subpartition template
(subpartition s1 values (211),
subpartition s2 values (212),
subpartition s3 values (213),
subpartition s4 values (214),
subpartition s5 values (215),
subpartition s6 values (216),
subpartition s7 values (217),
subpartition s8 values (218),
subpartition s9 values (219),
subpartition s10 values (220),
subpartition s0 values (DEFAULT) )
(
partition p1 values less than (TO_DATE('2018-11-01','YYYY-MM-DD')),
partition p2 values less than (TO_DATE('2018-12-02','YYYY-MM-DD')),
partition p3 values less than (TO_DATE('2019-01-01','YYYY-MM-DD')),
partition p4 values less than (TO_DATE('2019-02-01','YYYY-MM-DD')),
partition p5 values less than (TO_DATE('2019-03-01','YYYY-MM-DD')),
partition p6 values less than (TO_DATE('2019-04-01','YYYY-MM-DD')),
partition p7 values less than (TO_DATE('2019-05-01','YYYY-MM-DD')),
partition p8 values less than (TO_DATE('2019-06-01','YYYY-MM-DD')),
partition p9 values less than (TO_DATE('2019-07-01','YYYY-MM-DD')),
partition p10 values less than (TO_DATE('2019-08-01','YYYY-MM-DD'))
);
insert into range_list_part_tab
(seq, deal_date, unit_code, remark)
select rownum,
to_date(to_char(sysdate-365, 'J') +
trunc(DBMS_RANDOM.value(0, 365)),'J'),
ceil(dbms_random.value(210,220)),
rpad('*', 1, '*')
from dual
connect by rownum <= 1000;
commit;
四、分区相关操作
- (1) Split分区
拆分分区,范围分区和列表分区都适合分区,注意不能对HASH类型的分区进行拆分
create table list_part_tab (seq number,deal_date date,unit_code number,remark varchar2(100))
partition by list (unit_code)
(
partition p1 values (211),
partition p2 values (212),
partition p3 values (213),
partition p4 values (214),
partition p5 values (215),
partition p6 values (216),
partition p7 values (217),
partition p8 values (218),
partition p9 values (219),
partition p10 values (220),
partition p0 values (DEFAULT)
);
alter table list_part_tab split partition p10 at(220) into (PARTITION p11,PARTITION p12);
- (2)新增分区
ALTER TABLE list_part_tab ADD PARTITION P13 VALUES LESS THAN(250);
新增子分区,子分区名称是P13SUB1
ALTER TABLE list_part_tab MODIFY PARTITION P13 ADD SUBPARTITION P13SUB1 VALUES(350);
- (3)删除分区
ALTER TABLE list_part_tab DROP PARTITION P13;
删除子分区,子分区名称P13SUB1
ALTER TABLE list_part_tab DROP SUBPARTITION P13SUB1;
- (4)TRUNCATE分区
TRUNCATE是指删除分区的数据,并不会删除分区
ALTER TABLE list_part_tab TRUNCATE PARTITION P2;
TRUNCATE子分区
ALTER TABLE list_part_tab TRUNCATE SUBPARTITION P13SUB1;
- (5)合并分区
合并分区是将相邻的分区合并成一个分区,结果分区将采用较高分区的界限,值得注意的是,不能将分区合并到界限较低的分区
ALTER TABLE list_part_tab MERGE PARTITIONS P1,P2 INTO PARTITION P2;
- (6)接合分区(coalesca)
将散列分区中的数据接合到其它分区中,当散列分区中的数据比较大时,可以增加散列分区,然后进行接合,注意接合只适用于散列分区
ALTER TABLE list_part_tab COALESCA PARTITION;
- (7)重命名分区
ALTER TABLE SAlist_part_tabLES RENAME PARTITION P11 TO P1;
- (8)交换分区
交换分区是说交换两张表结构一样的表的数据,注意最好加上including indexs更新全局索引,不加的话,全局索引会失效
alter table list_part_tab exchange partition p1 with table range_part_tab including indexs update global indexs;
五、分区相关查询
分区相关查询
- (1)查询数据库所有分区表的信息
select * from DBA_PART_TABLES
- (2)查询分区表类型、是否有子分区,分区总数
select pt.partitioning_type, pt.subpartitioning_type, pt.partition_count
from user_part_tables pt
- (3)查询分区详细详细:
SELECT tab.* FROM USER_TAB_PARTITIONS tab WHERE TABLE_NAME='LIST_PART_TAB'
- (4)查询分区表哪列建分区
select column_name, object_type, column_position
from user_part_key_columns
where name = 'LIST_PART_TAB';
- (5)查询分区表大小
select sum(bytes / 1024 / 1024)
from user_segments
where segment_name = 'LIST_PART_TAB';
- (6)查询分区表各分区的大小和分区名
select partition_name, segment_type, bytes
from user_segments
where segment_name = 'LIST_PART_TAB';
- (7)查询分区表各索引大小
select segment_name, segment_type, sum(bytes) / 1024 / 1024
from user_segments
where segment_name in
(select index_name
from user_indexes
where table_name = 'LIST_PART_TAB')
group by segment_name, segment_type;
- (8)查询分区表的统计信息
select table_name,
partition_name,
last_analyzed,
partition_position,
num_rows
from user_tab_statistics
where table_name = 'LIST_PART_TAB';
- (9)查询分区表索引情况
select table_name,
index_name,
last_analyzed,
blevel,
num_rows,
leaf_blocks,
distinct_keys,
status
from user_indexes
where table_name = 'LIST_PART_TAB';
- (10)查询索引在哪些列上
select index_name, column_name, column_position
from user_ind_columns
where table_name = 'LIST_PART_TAB';
- (11)查询普通表失效的索引
select ind.index_name,
ind.table_name,
ind.blevel,
ind.num_rows,
ind.leaf_blocks,
ind.distinct_keys
from user_indexes ind
where status = 'INVALID';
- (12)查询分区表失效的索引
select a.blevel,
a.leaf_blocks,
a.index_name,
b.table_name,
a.partition_name,
a.status
from user_ind_partitions a, user_indexes b
where a.index_name = b.index_name
and a.status = 'UNUSABLE';
附录:分区表索引失效的操作
ps:表格来自《收获,不止SQL调优》一书作者的整理
| 操作动作 | 操作命令 | 是否失效(全局索引) | 如何避免(全局索引) | 是否失效(分区索引) | 如何避免(分区索引) |
|---|---|---|---|---|---|
| truncate分区 | alter table part_tab_trunc truncate partition p1 ; | 失效 | alter table part_tab_trunc truncate partition p1 Update GLOBAL indexes; | 没影响 | N/A |
| drop分区 | alter table part_tab_drop drop partition p1; | 失效 | alter table part_tab_drop drop partition p1 Update GLOBAL indexes; | 没影响 | N/A |
| split分区 | alter table part_tab_split SPLIT PARTITION P_MAX at(30000) into (PARTITION p3,PARTITION P_MAX); | 失效 | alter table part_tab_split SPLIT PARTITION P_MAX at (30000) into (PARTITION p3,PARTITION P_MAX) update global indexes; | 没影响 | N/A |
| add分区 | alter table part_tab_add add PARTITION p6 values less than (60000); | 没影响 | N/A | 没影响 | N/A |
| exchange分区 | alter table part_tab_exch exchange partition p1 with table normal_tab including indexes; | 失效 | alter table part_tab_exch exchange partition p1 with table normal_tab including indexes update global indexes; | 没影响 | N/A |
Oracle SQL调优之分区表的更多相关文章
- Oracle SQL 调优健康检查脚本
Oracle SQL 调优健康检查脚本 我们关注数据库系统的性能,进行数据库调优的主要工作就是进行SQL的优化.良好的数据架构设计.配合应用系统中间件和写一手漂亮的SQL,是未来系统上线后不出现致命性 ...
- Oracle SQL调优记录
目录 一.前言 二.注意点 三.Oracle执行计划 四.调优记录 @ 一.前言 本博客只记录工作中的一次oracle sql调优记录,因为数据量过多导致的查询缓慢,一方面是因为业务太过繁杂,关联了太 ...
- Oracle SQL调优系列之SQL Monitor Report
@ 目录 1.SQL Monitor简介 2.捕捉sql的前提 3.SQL Monitor 参数设置 4.SQL Monitor Report 4.1.SQL_ID获取 4.2.Text文本格式 4. ...
- Oracle SQL调优之表设计
在看<收获,不止sql优化>一书,并做了笔记,本博客介绍一下一些和调优相关的表比如分区表.临时表.索引组织表.簇表以及表压缩技术 分区表使用与查询频繁而更新数据不频繁的情况,不过要记得加全 ...
- Oracle SQL 调优之 sqlhc
SQL 执行慢,如何 快速准确的优化. sqlhc 就是其中最好工具之一 通过获得sql所有的执行计划,列出实际的性能的瓶颈点,列出 sql 所在的表上的行数,每一列的数据和分布,现有的索引,sql ...
- Oracle SQL调优之绑定变量用法简介
目录 一.SQL执行过程简介 二.绑定变量典型用法 2.1.在SQL中绑定变量 2.2.在PL/SQL中使用绑定变量 2.3.PL/SQL批量绑定变量 2.4.Java代码里使用绑定变量 最近在看&l ...
- Oracle SQL调优
在多数情况下,Oracle使用索引t来更快地遍历表,优化器主要根据定义的索引来提高性能. 但是,如果在SQL语句的where子句中写的SQL代码不合理,就会造成优化器删去索引而使用全表扫描,一般就这种 ...
- ORACLE SQL调优案例一则
收到监控告警日志文件(Alert)的作业发出的告警邮件,表空间TEMPSCM2不能扩展临时段,说明临时表空间已经被用完了,TEMPSCM2表空间不够用了 Dear All: The Instanc ...
- Oracle中SQL调优(SQL TUNING)之最权威获取SQL执行计划大全
该文档为根据相关资料整理.总结而成,主要讲解Oracle数据库中,获取SQL语句执行计划的最权威.最正确的方法.步骤,此外,还详细说明了每种方法中可选项的意义及使用方法,以方便大家和自己日常工作中查阅 ...
随机推荐
- python获取本机IP地址
方法一 通常使用socket.gethostname()方法即可获取本机IP地址,但有时候获取不到(比如没有正确设置主机名称) import socket #获取计算机名称hostname=socke ...
- HDU - 2612 Find a way 【BFS】
题目链接 http://acm.hdu.edu.cn/showproblem.php?pid=2612 题意 有两个人 要去一个城市中的KFC 一个城市中有多个KFC 求两个人到哪一个KFC的总时间最 ...
- JAVA源码分析------锁(1)
http://870604904.iteye.com/blog/2258604 第一次写博客,也就是记录一些自己对于JAVA的一些理解,不足之处,请大家指出,一起探讨. 这篇博文我打算说一下JAVA中 ...
- python增删改查zabbix主机等
摘自: http://www.jianshu.com/p/e087cace8ddf 一.API简介 Zabbix API是在1.8版本中开始引进并且已经被广泛应用.所有的Zabbix移动客户端都是基于 ...
- 关于for 循环里 线程执行顺序问题
最近在做项目时遇到了 这样的需求 要在一个for循环里执行下载的操作, 而且要等 下载完每个 再去接着走循环.上网查了一些 觉得说的不是很明确.现在把我用到的代码 贴上 希望可以帮到有此需求的开发者 ...
- Java IO(输入输出)
1. System.out.System.in System 内部: public final static InputStream in = null; public final static Pr ...
- ACM学习历程——HDU4814 Golden Radio Base(数学递推) (12年成都区域赛)
Description Golden ratio base (GRB) is a non-integer positional numeral system that uses the golden ...
- 相对路径转绝对路径C++实现
#include<iostream> #include<string> #include<vector> using namespace std; //相对路径转绝 ...
- dubbo设计实现的健壮性
Dubbo 作为远程服务暴露.调用和治理的解决方案,是应用运转的经络,其本身实现健壮性的重要程度是不言而喻的. 这里列出一些 Dubbo 用到的原则和方法. 日志 日志是发现问题.查看问题一个最常用的 ...
- JQuery Mobile+cordova构建一个Android项目
1.安装Android开发环境 Android开发环境的安装,现在主要是由于不能访问谷歌站点,在windows下在host文件中添加一个对应的74.125.195.190 dl-ssl.goo ...