SQLAlchemy的基本使用
一、介绍
SQLAlchemy是一种ORM(Object-Relational Mapping)框架,用来将关系型数据库映射到对象上。该框架建立在DB API之上,将类和对象转化成SQL,然后使用API执行SQL并获取执行结果。
二、组成
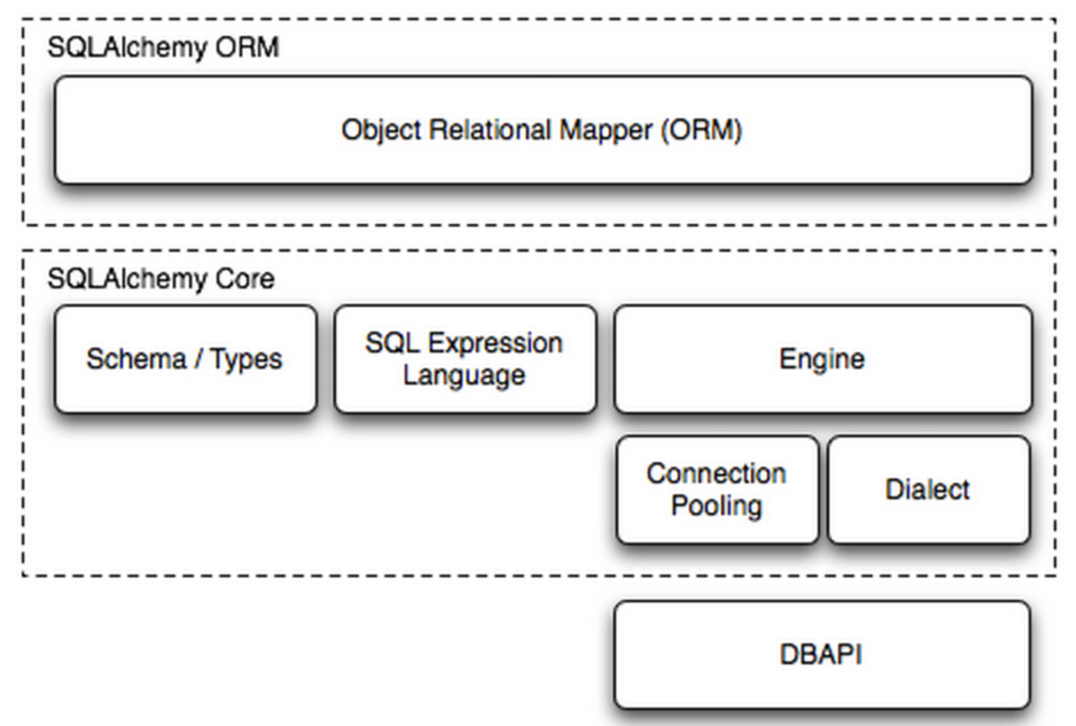
- Schema/Types,架构和类型
- SQL Exprression Language,SQL表达式语言
- Engine,框架的引擎
- Connection Pooling ,数据库连接池
- Dialect,选择连接数据库的DB API种类
三、基本使用
1、流程:
1)使用者通过ORM对象提交命
2)命令交给SQLAlchemy Core(Schema/Types SQL Expression Language)转换成SQL
3)使用 Engine/ConnectionPooling/Dialect 进行数据库操作
3.1)匹配使用者事先配置好的egine
3.2)egine从连接池中取出一个链接
3.3)基于该链接通过Dialect调用DB API,将SQL转交给它去执行
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
2、启用
如果我们不依赖于SQLAlchemy的转换而自己写好sql语句,就意味着我们可以直接从第3个阶段开始执行了,事实上正是如此,我们完全可以只用SQLAlchemy执行纯sql语句,如下:
from sqlalchemy import create_engine # 1 准备
# 需要事先安装好pymysql
# 配置好要使用的数据库,这里用MySQL为例
# 需要事先创建好数据库:create database db1 charset utf8; # 2 创建引擎
egine=create_engine('mysql+pymysql://root@127.0.0.1/db1?charset=utf8') # 3 执行sql
# egine.execute('create table if not EXISTS user(id int PRIMARY KEY auto_increment,name char(32));')
# cur=egine.execute('insert into user values(%(id)s,%(name)s);',name='ming',id=3) # 4 查询
cur=egine.execute('select * from user') cur.fetchone() #获取一行
cur.fetchmany(2) #获取多行
cur.fetchall() #获取所有行
3、ORM
1)创建表
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime, Enum, ForeignKey, UniqueConstraint, ForeignKeyConstraint, \
Index egine = create_engine('mysql+pymysql://root@127.0.0.1:3306/db1?charset=utf8', max_overflow=5) # 创建一个Base类,后面创建的每个表都需要继承这个类
Base = declarative_base() # 创建单表:业务线
class Business(Base):
__tablename__ = 'business'
id = Column(Integer, primary_key=True, autoincrement=True)
bname = Column(String(32), nullable=False, index=True) # 多对一:多个服务可以属于一个业务线,多个业务线不能包含同一个服务
class Service(Base):
__tablename__ = 'service'
id = Column(Integer, primary_key=True, autoincrement=True)
sname = Column(String(32), nullable=False, index=True)
ip = Column(String(15), nullable=False)
port = Column(Integer, nullable=False) business_id = Column(Integer, ForeignKey('business.id')) __table_args__ = (
UniqueConstraint(ip, port, name='uix_ip_port'),
Index('ix_id_sname', id, sname)
) # 一对一:一种角色只能管理一条业务线,一条业务线只能被一种角色管理
class Role(Base):
__tablename__ = 'role'
id = Column(Integer, primary_key=True, autoincrement=True)
rname = Column(String(32), nullable=False, index=True)
priv = Column(String(64), nullable=False) business_id = Column(Integer, ForeignKey('business.id'), unique=True) # 多对多:多个用户可以是同一个role,多个role可以包含同一个用户
class Users(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True, autoincrement=True)
uname = Column(String(32), nullable=False, index=True) class Users2Role(Base):
__tablename__ = 'users2role'
id = Column(Integer, primary_key=True, autoincrement=True)
uid = Column(Integer, ForeignKey('users.id'))
rid = Column(Integer, ForeignKey('role.id')) __table_args__ = (
UniqueConstraint(uid, rid, name='uix_uid_rid'),
) # 创建所有表
def init_db():
Base.metadata.create_all(egine) # 删除数据库所有表
def drop_db():
Base.metadata.drop_all(egine) if __name__ == '__main__':
init_db()
注:设置外键的另一种方式 ForeignKeyConstraint(['other_id'], ['othertable.other_id'])
2)操作表
表结构
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String,ForeignKey
from sqlalchemy.orm import sessionmaker egine=create_engine('mysql+pymysql://root@127.0.0.1:3306/db1?charset=utf8',max_overflow=5) Base=declarative_base() #多对一:假设多个员工可以属于一个部门,而多个部门不能有同一个员工(只有创建公司才把员工当骆驼用,一个员工身兼数职)
class Dep(Base):
__tablename__='dep'
id=Column(Integer,primary_key=True,autoincrement=True)
dname=Column(String(64),nullable=False,index=True) class Emp(Base):
__tablename__='emp'
id=Column(Integer,primary_key=True,autoincrement=True)
ename=Column(String(32),nullable=False,index=True)
dep_id=Column(Integer,ForeignKey('dep.id')) def init_db():
Base.metadata.create_all(egine) def drop_db():
Base.metadata.drop_all(egine) drop_db()
init_db()
Session=sessionmaker(bind=egine)
session=Session()
增
row_obj=Dep(dname='销售') #按关键字传参,无需指定id,因其是自增长的
session.add(row_obj)
session.add_all([
Dep(dname='技术'),
Dep(dname='运营'),
Dep(dname='人事'),
]) session.commit()
删
session.query(Dep).filter(Dep.id > 3).delete()
session.commit()
改
session.query(Dep).filter(Dep.id > 0).update({'dname':'哇哈哈'})
session.query(Dep).filter(Dep.id > 0).update({'dname':Dep.dname+'_SB'},synchronize_session=False)
session.query(Dep).filter(Dep.id > 0).update({'id':Dep.id*100},synchronize_session='evaluate')
session.commit()
查
#查所有,取所有字段
res=session.query(Dep).all() #for row in res:print(row.id,row.dname) #查所有,取指定字段
res=session.query(Dep.dname).order_by(Dep.id).all() #for row in res:print(row.dname) res=session.query(Dep.dname).first()
print(res) # ('哇哈哈_SB',) #过滤查
res=session.query(Dep).filter(Dep.id > 1,Dep.id <1000) #逗号分隔,默认为and
print([(row.id,row.dname) for row in res])
SQLAlchemy的基本使用的更多相关文章
- sqlalchemy学习
sqlalchemy官网API参考 原文作为一个Pythoner,不会SQLAlchemy都不好意思跟同行打招呼! #作者:笑虎 #链接:https://zhuanlan.zhihu.com/p/23 ...
- tornado+sqlalchemy+celery,数据库连接消耗在哪里
随着公司业务的发展,网站的日活数也逐渐增多,以前只需要考虑将所需要的功能实现就行了,当日活越来越大的时候,就需要考虑对服务器的资源使用消耗情况有一个清楚的认知. 最近老是发现数据库的连接数如果 ...
- 冰冻三尺非一日之寒-mysql(orm/sqlalchemy)
第十二章 mysql ORM介绍 2.sqlalchemy基本使用 ORM介绍: orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似pyt ...
- Python 【第六章】:Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度 ...
- SQLAlchemy(一)
说明 SQLAlchemy只是一个翻译的过程,我们通过类来操作数据库,他会将我们的对应数据转换成SQL语句. 运用ORM创建表 #!/usr/bin/env python #! -*- coding: ...
- sqlalchemy(二)高级用法
sqlalchemy(二)高级用法 本文将介绍sqlalchemy的高级用法. 外键以及relationship 首先创建数据库,在这里一个user对应多个address,因此需要在address上增 ...
- sqlalchemy(一)基本操作
sqlalchemy(一)基本操作 sqlalchemy采用简单的Python语言,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型. 安装 需要安装MySQLdb pip install ...
- python SQLAlchemy
这里我们记录几个python SQLAlchemy的使用例子: 如何对一个字段进行自增操作 user = session.query(User).with_lockmode('update').get ...
- Python-12-MySQL & sqlalchemy ORM
MySQL MySQL相关文章这里不在赘述,想了解的点击下面的链接: >> MySQL安装 >> 数据库介绍 && MySQL基本使用 >> MyS ...
- 20.Python笔记之SqlAlchemy使用
Date:2016-03-27 Title:20.Python笔记之SqlAlchemy使用 Tags:python Category:Python 作者:刘耀 博客:www.liuyao.me 一. ...
随机推荐
- 在Windows环境中学习Linux
如何在Windows环境下学习Linux?方法如下: 方法一: 下载Cygwin,Cygwin是一个在windows平台上运行的类UNIX模拟环境,网上有很多安装教程,这里不多说. 方法二: 下载一个 ...
- POJ-3616
Milking Time Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 10434 Accepted: 4378 Des ...
- linux下gsoap的初次使用 -- c风格加法实例
摘自: http://blog.csdn.net/jinpw/article/details/3346844 https://www.cnblogs.com/dkblog/archive/2011/0 ...
- gSoap使用入门(2)----自定义接口头文件
摘自:http://blog.csdn.net/zhuzhihai1988/article/details/8131556 接口头文件的格式在向导中没有看到明确的说明性的内容,但通过看开发包中示例程序 ...
- Matcher的group()/group(int group)/groupCount()用法介绍
直接上代码: package com.dajiangtai.djt_spider.util; import java.util.regex.Matcher;import java.util.regex ...
- win32 API中GetSystemMetrics函数
1. SM_ARRANGE: 用于说明系统如何安排最小化窗口,根据显示器的不同系统数据可能有所不同.其包含一个起始位置和方向.关于在程序中怎么使用我还没有见个这样的代码. 起始位置可为下列值之一: A ...
- 蜂窝网络TDOA定位方法的Fang算法研究及仿真纠错
科学论文为我们提供科学方法,在解决实际问题中,能极大提高生产效率.但论文中一些失误则可能让使用者浪费大量时间.自己全部再推导那真不容易,怀疑的成本特别高,通常不会选择这条路.而如果真是它的问题,其它所 ...
- MYSQL limit,offset 区别(转)
SELECT keyword FROM keyword_rank WHERE advertiserid='59' order by keyword LIMIT 2 OFFSET 1; 比如这个SQL ...
- Python 获取脚本路径以及脚本所在文件夹路径
import os script_path = os.path.realpath(__file__) script_dir = os.path.dirname(script_path)
- cf808D(xjb)
题目链接:http://codeforces.com/problemset/problem/808/D 题意:问能不能通过交换不超过两个元素的位置使得原数组变成能分成前,后和相等的连续两部分: 注意这 ...