[深度学习] pytorch学习笔记(4)(Module类、实现Flatten类、Module类作用、数据增强)
一、继承nn.Module类并自定义层
我们要利用pytorch提供的很多便利的方法,则需要将很多自定义操作封装成nn.Module类。
首先,简单实现一个Mylinear类:
from torch import nn # Mylinear继承Module
class Mylinear(nn.Module):
# 传入输入维度和输出维度
def __init__(self,in_d,out_d):
# 调用父类构造函数
super(Mylinear,self).__init__()
# 使用Parameter类将w和b封装,这样可以通过nn.Module直接管理,并提供给优化器优化
self.w = nn.Parameter(torch.randn(out_d,in_d))
self.b = nn.Parameter(torch.randn(out_d)) # 实现forward函数,该函数为默认执行的函数,即计算过程,并将输出返回
def forward(self, x):
x = x@self.w.t() + self.b
return x
这样就可以将我们自定义的Mylinear加入整个网络:
# 网络结构
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__() self.model = nn.Sequential(
#nn.Linear(784, 200),
Mylinear(784,200),
nn.BatchNorm1d(200, eps=1e-8),
nn.LeakyReLU(inplace=True),
#nn.Linear(200, 200),
Mylinear(200, 200),
nn.BatchNorm1d(200, eps=1e-8),
nn.LeakyReLU(inplace=True),
#nn.Linear(200, 10),
Mylinear(200,10),
nn.LeakyReLU(inplace=True)
)
我们可以看出,MLP网络实际上也是继承自Module,这就说明了,nn.Module实际上可以实现一个嵌套的结构,我们的整个网络就是由一个嵌套的树形结构组成的。例如:
# Mylinear继承Module
class Mylinear(nn.Module):
# 传入输入维度和输出维度
def __init__(self, in_d, out_d):
# 调用父类构造函数
super(Mylinear, self).__init__()
# 使用Parameter类将w和b封装,这样可以通过nn.Module直接管理,并提供给优化器优化
self.w = nn.Parameter(torch.randn(out_d, in_d))
self.b = nn.Parameter(torch.randn(out_d)) # 实现forward函数,该函数为默认执行的函数,即计算过程,并将输出返回
def forward(self, x):
x = x @ self.w.t() + self.b
return x # 将几个nn.Module组件综合成一个
class Mylayer(nn.Module):
def __init__(self, in_d, out_d):
super(Mylayer, self).__init__()
# 包含一个全连接层,一个BN层,一个Leaky Relu层
self.lin = Mylinear(in_d, out_d)
self.bn = nn.BatchNorm1d(out_d, eps=1e-8)
self.lrelu = nn.LeakyReLU(inplace=True) # 按顺序跑一遍3种网络,返回最终结果
def forward(self, x):
x = self.lin(x)
x = self.bn(x)
x = self.lrelu(x)
return x # 网络结构
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__() self.model = nn.Sequential(
Mylayer(784, 200),
Mylayer(200, 200),
# nn.Linear(200, 10),
Mylinear(200, 10),
nn.LeakyReLU(inplace=True)
)
上述代表表示的结构如下图所示:
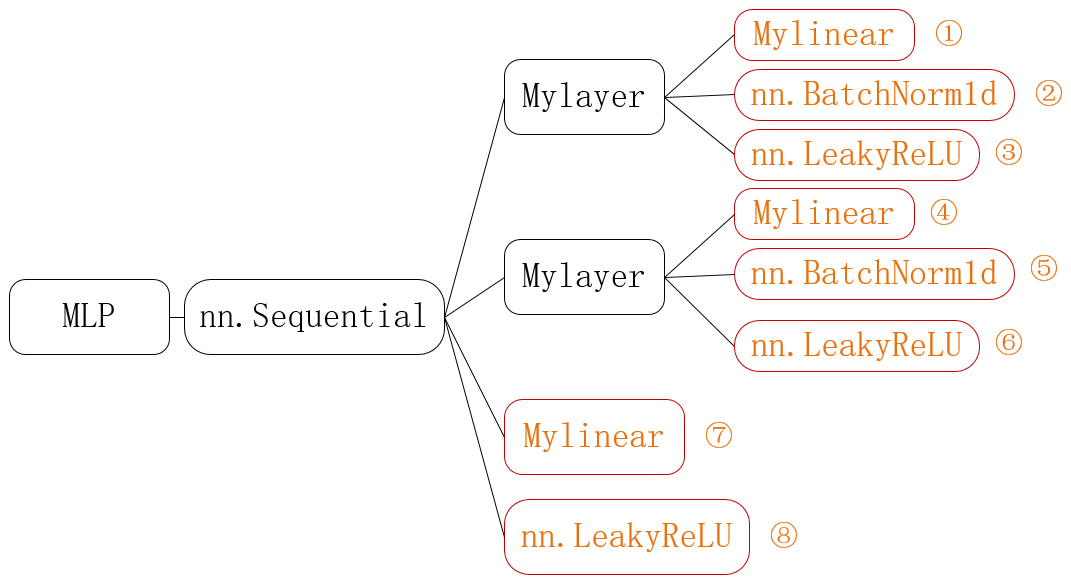
其中所有的类都继承自nn.Module,从前往后是嵌套的关系。在上述代码中,真正做计算的是橙色部分1-8,而其他的都只是作为封装。其中nn.Sequential、nn.BatchNorm1d、nn.LeakyReLU是pytorch提供的类,Mylinear和Mylayer是我们自己封装的类。
二、实现一个常用类Flatten类
Flatten就是将2D的特征图压扁为1D的特征向量,用于全连接层的输入。
# Flatten继承Module
class Flatten(nn.Module):
# 构造函数,没有什么要做的
def __init__(self):
# 调用父类构造函数
super(Flatten, self).__init__() # 实现forward函数
def forward(self, input):
# 保存batch维度,后面的维度全部压平,例如输入是28*28的特征图,压平后为784的向量
return input.view(input.size(0), -1)
三、nn.Module类的作用
1.便于保存模型:
# 每隔N epoch保存一次模型
torch.save(net.state_dict(),'ckpt_n_epoch.mdl')
# 下次训练时可以直接导入接着训练
net.load_state_dict(torch.load('ckpt_n_epoch.mdl'))
2.方便切换train和val模式
### 不同模式对于某些层的操作时不同的,例如BN,dropout层等
# 切换到train模式
net.train()
# 切换到validation模式
net.eval()
3.方便将网络转移到GPU上
# 定义GPU设备
device = torch.device('cuda')
# 将网络转移到GPU,注意to函数返回的是net的引用(引用是不变的)
# 不同的是net中的参数都转移到GPU上去了
net.to(device) # 不同于参数直接转移,转移后的w2(在GPU上)和转移前的w(在CPU上)两者完全是不一样的
# 我们要使之在GPU上运行,则必须使用w2
#w2 = w.to(device)
4.方便查看各层参数
# 获取由每一层参数组成的列表
para_list = list(net.parameters())
# 获取一个(name,每层参数)的tuple组成的列表
para_named_list = list(net.named_parameters())
# 获取一个{'model.0.weight': 参数,'model.0.bias': 参数, 'model.1.weight': 参数}
para_named_dict = dict(net.named_parameters())
四、数据增强
torchvision提供了很方便的数据预处理工具,数据增强可以一次性搞定。
from torchvision import datasets, transforms
train_data_trans = datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
# 水平翻转,50%执行
transforms.RandomHorizontalFlip(),
# 垂直翻转,50%执行
transforms.RandomVerticalFlip(),
# 随机旋转范围在正负15°之间,也可以写(-15,15)
transforms.RandomRotation(15),
# 旋转范围在90-270之间
#transforms.RandomRotation([90,270]),
# 将图片方缩放到指定大小
transforms.Resize([32,32]),
# 随机剪裁图片到指定大小
transforms.RandomCrop([28,28]),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
如果pytorch没有提供需要的预处理类,我们可以参照源码仿造写一个自定义处理的类来进行处理。例如对图片添加白噪声,按通道变换颜色等等。
[深度学习] pytorch学习笔记(4)(Module类、实现Flatten类、Module类作用、数据增强)的更多相关文章
- [深度学习] Pytorch学习(一)—— torch tensor
[深度学习] Pytorch学习(一)-- torch tensor 学习笔记 . 记录 分享 . 学习的代码环境:python3.6 torch1.3 vscode+jupyter扩展 #%% im ...
- [深度学习] pytorch学习笔记(2)(梯度、梯度下降、凸函数、鞍点、激活函数、Loss函数、交叉熵、Mnist分类实现、GPU)
一.梯度 导数是对某个自变量求导,得到一个标量. 偏微分是在多元函数中对某一个自变量求偏导(将其他自变量看成常数). 梯度指对所有自变量分别求偏导,然后组合成一个向量,所以梯度是向量,有方向和大小. ...
- [深度学习] pytorch学习笔记(3)(visdom可视化、正则化、动量、学习率衰减、BN)
一.visdom可视化工具 安装:pip install visdom 启动:命令行直接运行visdom 打开WEB:在浏览器使用http://localhost:8097打开visdom界面 二.使 ...
- [深度学习] pytorch学习笔记(1)(数据类型、基础使用、自动求导、矩阵操作、维度变换、广播、拼接拆分、基本运算、范数、argmax、矩阵比较、where、gather)
一.Pytorch安装 安装cuda和cudnn,例如cuda10,cudnn7.5 官网下载torch:https://pytorch.org/ 选择下载相应版本的torch 和torchvisio ...
- [深度学习] Pytorch学习(二)—— torch.nn 实践:训练分类器(含多GPU训练CPU加载预测的使用方法)
Learn From: Pytroch 官方Tutorials Pytorch 官方文档 环境:python3.6 CUDA10 pytorch1.3 vscode+jupyter扩展 #%% #%% ...
- pytorch学习笔记(十二):详解 Module 类
Module 是 pytorch 提供的一个基类,每次我们要 搭建 自己的神经网络的时候都要继承这个类,继承这个类会使得我们 搭建网络的过程变得异常简单. 本文主要关注 Module 类的内部是怎么样 ...
- [PyTorch 学习笔记] 3.1 模型创建步骤与 nn.Module
本章代码:https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson3/module_containers.py 这篇文章来看下 ...
- 【PyTorch深度学习】学习笔记之PyTorch与深度学习
第1章 PyTorch与深度学习 深度学习的应用 接近人类水平的图像分类 接近人类水平的语音识别 机器翻译 自动驾驶汽车 Siri.Google语音和Alexa在最近几年更加准确 日本农民的黄瓜智能分 ...
- 深度学习Keras框架笔记之AutoEncoder类
深度学习Keras框架笔记之AutoEncoder类使用笔记 keras.layers.core.AutoEncoder(encoder, decoder,output_reconstruction= ...
随机推荐
- centos7基础安装
基础: hostname xxvim /etc/hostname systemctl stop firewalld systemctl disable firewalldsetenforce 0gre ...
- [转帖]互联网同步yum服务器阿里云 reposync createrepo
https://www.cnblogs.com/withfeel/p/10635529.html 这篇文章 比较齐整 参考文章: https://www.cnblogs.com/lldsn/p/104 ...
- Redis数据库连接
1.建立maven项目pox.xml导入依赖包 <dependency> <groupId>io.lettuce</groupId> <artifactId& ...
- 注入(Injection)
注入(Injection)是: Java EE提供了注入机制,使您的对象能够获取对资源和其他依赖项的引用,而无需直接实例化它们.通过使用将字段标记为注入点的注释之一来装饰字段或方法,可以在类中声明所需 ...
- nginx+gunicorn/uwsgi+python web 的前世今生
我们在部署 flask.django 等 python web 框架时,网上最多的教程就是 nginx+gunicorn/uwsgi 的部署方式,那为什么要这么部署呢,本文就来系统地解释这个问题. 必 ...
- JDK 监控和故障处理工具总结 (转)
出处: JDK 监控和故障处理工具总结 JDK 监控和故障处理工具总结 JDK 命令行工具 jps:查看所有 Java 进程 jstat: 监视虚拟机各种运行状态信息 jinfo: 实时地查看和调整 ...
- The Party and Sweets CodeForces - 1159C (拓排)
优化连边然后拓排. #include <iostream> #include <sstream> #include <algorithm> #include < ...
- bootstrap之响应式布局
1.手动配置viewport 在HTML中: <meta name="viewport" content="width=device-width,initial-s ...
- Delphi ListBox组件
- 递归型SPFA+二分答案 || 负环 || BZOJ 4773
题解: 基本思路是二分答案,每次用Dfs型SPFA验证该答案是否合法. 一点细节我注释在代码里了. 代码: #include<cstdio> #include<cstring> ...