scrapy项目2:爬取智联招聘的金融类高端岗位(spider类)
---恢复内容开始---
今天我们来爬取一下智联招聘上金融行业薪酬在50-100万的职位。
第一步:解析解析网页

当我们依次点击下边的索引页面是,发现url的规律如下:
第1页:http://www.highpin.cn/zhiwei/ci_180000_180100_as_50_100.html
第2页:http://www.highpin.cn/zhiwei/ci_180000_180100_as_50_100_p_2.html
第3页:http://www.highpin.cn/zhiwei/ci_180000_180100_as_50_100_p_3.html
看到第三页时,用我小学学的数据知识,我便已经找到了规律,哈哈,相信大家也是!
接下来说说我要爬取的目标吧:
如下图:我想要得到的是:职位名称、薪资范围、工作地点、发布时间
借助谷歌的xpath我就着手解析和提取这些数据了,这里不做分析,在代码中体现

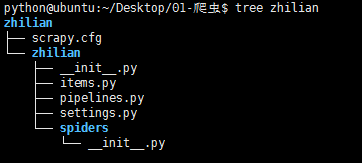
第二步:项目实现 通过 scrapy startproject zhilian创建项目,结构如下:
1. items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy
class ZhilianItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 职位
position = scrapy.Field()
# 公司名称
company = scrapy.Field()
# 薪资
salary = scrapy.Field()
# 工作地点
place = scrapy.Field()
# 发布时间
time = scrapy.Field()
2.爬虫文件:highpin.py 通过命令scrapy genspider highpin 'highpin.cn'创建
# -*- coding: utf-8 -*-
import scrapy
from zhilian.items import ZhilianItem
class HighpinSpider(scrapy.Spider):
# 爬虫名,创建文件时给定
name = "highpin"
allowed_domains = ["highpin.cn"]
url = 'http://www.highpin.cn/zhiwei/ci_180000_180100_as_50_100'
# 用于构造url的参数
offset = 1
start_urls = [url + '.html']
def parse(self, response):
# 用xpath对网页内容进行解析,返回的是一个选择器列表
position_list = response.xpath('//div[@class="c-list-box"]/div/div[@class="clearfix"]')
item = ZhilianItem()
print '------------------------------'
print len(position_list)
print '-----------------------------------'
for pos in position_list:
# 这里的item对应于items.py文件中的字段
item['position'] = pos.xpath('./div/p[@class="jobname clearfix"]/a/text()').extract()[0]
item['company'] = pos.xpath('./div/p[@class="companyname"]/a/text()').extract()[0]
item['salary'] = pos.xpath('./div/p[@class="s-salary"]/text()').extract()[0]
item['place'] = pos.xpath('./div/p[@class="s-place"]/text()').extract()[0]
item['time'] = pos.xpath('./div[@class="c-list-search c-wid122 line-h44"]/text()').extract()[0]
yield item
if self.offset < 150:
self.offset += 1
# 构建下一个要爬取的url
url = self.url + '_p_' + str(self.offset) + '.html'
print url
# 发送请求,并调用parse进行数据的解析处理
yield scrapy.Request(url,callback=self.parse)
3.pipelines.py管道文件用于将数据存于本地
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class ZhilianPipeline(object):
def __init__(self):
# 初始化是创建本地文件
self.filename = open('position.json','w')
def process_item(self, item, spider):
将python数据通过dumps转换成json数据
text = json.dumps(dict(item),ensure_ascii=False) + '\n'
# 将数据写入文件
self.filename.write(text.encode('utf-8'))
return item
def close_spider(self,spider):
# 关闭文件
self.filename.close()
4.settings.py文件
说明1:在settings.py中首先要配置管道文件,如下图:

说明2:USER_AGENT,起初我在settings中所使用的user-agent为:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Mobile Safari/537.36
运行爬虫后,如下图:

如上图所示,服务器对我要访问的url做了重定向,复制重定向后的url到浏览器如下图:
显然,这个页面并没有我们想要的信息,这就是一种反扒策略
为了解决这个问题,我就试着将USER_AGENT 更换为:Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.

再次通过 scrapy crawl highpin启动爬虫,发现爬虫程序已可以正常爬取
5.启动爬虫 命令:scrapy crawl highpin

数据文件内容

---恢复内容结束---
scrapy项目2:爬取智联招聘的金融类高端岗位(spider类)的更多相关文章
- 用Python爬取智联招聘信息做职业规划
上学期在实验室发表时写了一个爬取智联招牌信息的爬虫. 操作流程大致分为:信息爬取——数据结构化——存入数据库——所需技能等分词统计——数据可视化 1.数据爬取 job = "通信工程师&qu ...
- Python+selenium爬取智联招聘的职位信息
整个爬虫是基于selenium和Python来运行的,运行需要的包 mysql,matplotlib,selenium 需要安装selenium火狐浏览器驱动,百度的搜寻. 整个爬虫是模块化组织的,不 ...
- node.js 89行爬虫爬取智联招聘信息
写在前面的话, .......写个P,直接上效果图.附上源码地址 github/lonhon ok,正文开始,先列出用到的和require的东西: node.js,这个是必须的 request,然发 ...
- 用生产者消费模型爬取智联招聘python岗位信息
爬取python岗位智联招聘 这里爬取北京地区岗位招聘python岗位,并存入EXECEL文件内,代码如下: import json import xlwt import requests from ...
- python爬取智联招聘职位信息(多进程)
测试了下,采用单进程爬取5000条数据大概需要22分钟,速度太慢了点.我们把脚本改进下,采用多进程. 首先获取所有要爬取的URL,在这里不建议使用集合,字典或列表的数据类型来保存这些URL,因为数据量 ...
- python爬取智联招聘职位信息(单进程)
我们先通过百度搜索智联招聘,进入智联招聘官网,一看,傻眼了,需要登录才能查看招聘信息 没办法,用账号登录进去,登录后的网页如下: 输入职位名称点击搜索,显示如下网页: 把这个URL:https://s ...
- scrapy 爬取智联招聘
准备工作 1. scrapy startproject Jobs 2. cd Jobs 3. scrapy genspider ZhaopinSpider www.zhaopin.com 4. scr ...
- scrapy框架爬取智联招聘网站上深圳地区python岗位信息。
爬取字段,公司名称,职位名称,公司详情的链接,薪资待遇,要求的工作经验年限 1,items中定义爬取字段 import scrapy class ZhilianzhaopinItem(scrapy.I ...
- python3 requests_html 爬取智联招聘数据(简易版)
PS重点:我回来了-----我回来了-----我回来了 1. 基础需要: python3 基础 html5 CS3 基础 2.库的选择: 原始库 urllib2 (这个库早些年的用过,后来淡忘了) ...
随机推荐
- System.InsufficientMemoryException:无法分配536870912字节的托管内存缓冲区。可用内存量可能不足
一个病人住院太久,一次性打印护理表单超过3000条时报如标题所示的错误, 个人查阅分析应该可以从如下几方面入手: 一:查看程序客户端和服务端的配置文件相关属性是否限制了缓存最大值 (应该不是这个问题, ...
- Linux 查看文件内容(8)
我们知道在图形界面上查看文件内容只需要双击打开就好,那么在终端窗口里怎么查看文件内容呢?显然是需要能有一个命令能把文件内容显示在终端界面上. 查看文件内容主要有两个命令,分别是 cat 和 more, ...
- python笔记——dict和set
学习廖雪峰python3笔记_dict和set dict__介绍 dict --> dictionary(字典)--> python内置 --> 使用键-值(key-value)存储 ...
- E - 卿学姐与城堡的墙(树状数组求逆序数)
卿学姐与城堡的墙 Time Limit: 2000/1000MS (Java/Others) Memory Limit: 65535/65535KB (Java/Others) Submit ...
- 一遍记住 8 种排序算法与 Java 代码实现
☞ 程序员进阶必备资源免费送「21种技术方向!」 ☜ 作者:KaelQ, www.jianshu.com/p/5e171281a387 1.直接插入排序 经常碰到这样一类排序问题:把新的数据插入到已经 ...
- [.net core]7 4种app key value的配置方法及优先顺序
就是这货 点开查看内容 { "Logging": { "LogLevel": { "Default": "Warning" ...
- SQL语句中*号的缺点
我觉得这篇博客说的比较好,参考借鉴一下:https://blog.csdn.net/weixin_44588186/article/details/87263756
- mac osx sed 命令
$ sed -i "s/devicedemo/device/g" `grep devicedemo -rl ./` sed: 1: ".//.coveragerc&quo ...
- es6 filter() 数组过滤方法总结(转载)
1.创建一个数组,判断数组中是否存在某个值 var newarr = [ { num: 1, val: 'ceshi', flag: 'aa' }, { num: 2, val: 'ceshi2', ...
- C# wpf 使用资源文件 resx
随意新建一个wpf应用 在cs代码编辑,增加 using System.Resources; 放在最上 在方案新建文件夹 名 文件 在 文件 新建资源文件 资源.resx 资源.resx 添加字符串 ...