scrapy项目2:爬取智联招聘的金融类高端岗位(spider类)
---恢复内容开始---
今天我们来爬取一下智联招聘上金融行业薪酬在50-100万的职位。
第一步:解析解析网页

当我们依次点击下边的索引页面是,发现url的规律如下:
第1页:http://www.highpin.cn/zhiwei/ci_180000_180100_as_50_100.html
第2页:http://www.highpin.cn/zhiwei/ci_180000_180100_as_50_100_p_2.html
第3页:http://www.highpin.cn/zhiwei/ci_180000_180100_as_50_100_p_3.html
看到第三页时,用我小学学的数据知识,我便已经找到了规律,哈哈,相信大家也是!
接下来说说我要爬取的目标吧:
如下图:我想要得到的是:职位名称、薪资范围、工作地点、发布时间
借助谷歌的xpath我就着手解析和提取这些数据了,这里不做分析,在代码中体现

第二步:项目实现 通过 scrapy startproject zhilian创建项目,结构如下:
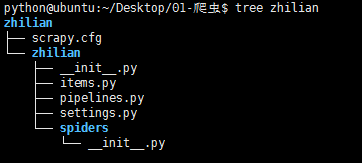
1. items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy
class ZhilianItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 职位
position = scrapy.Field()
# 公司名称
company = scrapy.Field()
# 薪资
salary = scrapy.Field()
# 工作地点
place = scrapy.Field()
# 发布时间
time = scrapy.Field()
2.爬虫文件:highpin.py 通过命令scrapy genspider highpin 'highpin.cn'创建
# -*- coding: utf-8 -*-
import scrapy
from zhilian.items import ZhilianItem
class HighpinSpider(scrapy.Spider):
# 爬虫名,创建文件时给定
name = "highpin"
allowed_domains = ["highpin.cn"]
url = 'http://www.highpin.cn/zhiwei/ci_180000_180100_as_50_100'
# 用于构造url的参数
offset = 1
start_urls = [url + '.html']
def parse(self, response):
# 用xpath对网页内容进行解析,返回的是一个选择器列表
position_list = response.xpath('//div[@class="c-list-box"]/div/div[@class="clearfix"]')
item = ZhilianItem()
print '------------------------------'
print len(position_list)
print '-----------------------------------'
for pos in position_list:
# 这里的item对应于items.py文件中的字段
item['position'] = pos.xpath('./div/p[@class="jobname clearfix"]/a/text()').extract()[0]
item['company'] = pos.xpath('./div/p[@class="companyname"]/a/text()').extract()[0]
item['salary'] = pos.xpath('./div/p[@class="s-salary"]/text()').extract()[0]
item['place'] = pos.xpath('./div/p[@class="s-place"]/text()').extract()[0]
item['time'] = pos.xpath('./div[@class="c-list-search c-wid122 line-h44"]/text()').extract()[0]
yield item
if self.offset < 150:
self.offset += 1
# 构建下一个要爬取的url
url = self.url + '_p_' + str(self.offset) + '.html'
print url
# 发送请求,并调用parse进行数据的解析处理
yield scrapy.Request(url,callback=self.parse)
3.pipelines.py管道文件用于将数据存于本地
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class ZhilianPipeline(object):
def __init__(self):
# 初始化是创建本地文件
self.filename = open('position.json','w')
def process_item(self, item, spider):
将python数据通过dumps转换成json数据
text = json.dumps(dict(item),ensure_ascii=False) + '\n'
# 将数据写入文件
self.filename.write(text.encode('utf-8'))
return item
def close_spider(self,spider):
# 关闭文件
self.filename.close()
4.settings.py文件
说明1:在settings.py中首先要配置管道文件,如下图:

说明2:USER_AGENT,起初我在settings中所使用的user-agent为:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Mobile Safari/537.36
运行爬虫后,如下图:

如上图所示,服务器对我要访问的url做了重定向,复制重定向后的url到浏览器如下图:
显然,这个页面并没有我们想要的信息,这就是一种反扒策略
为了解决这个问题,我就试着将USER_AGENT 更换为:Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.

再次通过 scrapy crawl highpin启动爬虫,发现爬虫程序已可以正常爬取
5.启动爬虫 命令:scrapy crawl highpin

数据文件内容

---恢复内容结束---
scrapy项目2:爬取智联招聘的金融类高端岗位(spider类)的更多相关文章
- 用Python爬取智联招聘信息做职业规划
上学期在实验室发表时写了一个爬取智联招牌信息的爬虫. 操作流程大致分为:信息爬取——数据结构化——存入数据库——所需技能等分词统计——数据可视化 1.数据爬取 job = "通信工程师&qu ...
- Python+selenium爬取智联招聘的职位信息
整个爬虫是基于selenium和Python来运行的,运行需要的包 mysql,matplotlib,selenium 需要安装selenium火狐浏览器驱动,百度的搜寻. 整个爬虫是模块化组织的,不 ...
- node.js 89行爬虫爬取智联招聘信息
写在前面的话, .......写个P,直接上效果图.附上源码地址 github/lonhon ok,正文开始,先列出用到的和require的东西: node.js,这个是必须的 request,然发 ...
- 用生产者消费模型爬取智联招聘python岗位信息
爬取python岗位智联招聘 这里爬取北京地区岗位招聘python岗位,并存入EXECEL文件内,代码如下: import json import xlwt import requests from ...
- python爬取智联招聘职位信息(多进程)
测试了下,采用单进程爬取5000条数据大概需要22分钟,速度太慢了点.我们把脚本改进下,采用多进程. 首先获取所有要爬取的URL,在这里不建议使用集合,字典或列表的数据类型来保存这些URL,因为数据量 ...
- python爬取智联招聘职位信息(单进程)
我们先通过百度搜索智联招聘,进入智联招聘官网,一看,傻眼了,需要登录才能查看招聘信息 没办法,用账号登录进去,登录后的网页如下: 输入职位名称点击搜索,显示如下网页: 把这个URL:https://s ...
- scrapy 爬取智联招聘
准备工作 1. scrapy startproject Jobs 2. cd Jobs 3. scrapy genspider ZhaopinSpider www.zhaopin.com 4. scr ...
- scrapy框架爬取智联招聘网站上深圳地区python岗位信息。
爬取字段,公司名称,职位名称,公司详情的链接,薪资待遇,要求的工作经验年限 1,items中定义爬取字段 import scrapy class ZhilianzhaopinItem(scrapy.I ...
- python3 requests_html 爬取智联招聘数据(简易版)
PS重点:我回来了-----我回来了-----我回来了 1. 基础需要: python3 基础 html5 CS3 基础 2.库的选择: 原始库 urllib2 (这个库早些年的用过,后来淡忘了) ...
随机推荐
- [转贴]linux lsof命令详解
linux lsof命令详解 https://www.cnblogs.com/sparkbj/p/7161669.html 简介 lsof(list open files)是一个列出当前系统打开文件的 ...
- Java学生成绩绩点管理系统
一.考试要求: 1.按照测试内容要求完成程序的设计与编程: 2.建立学号姓名文件夹,如:“信 1805-1 班 20180001 XXX”,将源程序文件保存在文件夹中,压缩成 rar 文件提交. 3. ...
- Java基础(入门Java)
今天是学习Java的第一天,为了保证在暑假里持续高效的学习,决定每周写一篇博客汇报总结当周进度,以此来督促自己不断的向更深更远的方向迈进.Java刚刚入门,看到的人若觉得某些地方不妥欢迎进行批评指导, ...
- Til the Cows Come Home 最短路Dijkstra+bellman(普通+优化)
Til the Cows Come Home 最短路Dijkstra+bellman(普通+优化) 贝西在田里,想在农夫约翰叫醒她早上挤奶之前回到谷仓尽可能多地睡一觉.贝西需要她的美梦,所以她想尽快回 ...
- python-day17(正式学习)
目录 包 一.什么是包? 二.为什么要有包? 三.如何用包? 3.1 模块和包 3.2 扩展模块功能 3.3 修改__init__.py文件 绝对导入和相对导入 注意事项 模块不来总结了,直接去htt ...
- MySql 缓冲池(buffer pool) 和 写缓存(change buffer) 转
应用系统分层架构,为了加速数据访问,会把最常访问的数据,放在缓存(cache)里,避免每次都去访问数据库. 操作系统,会有缓冲池(buffer pool)机制,避免每次访问磁盘,以加速数据的访问. M ...
- [JavaScript] es6规则总结
let 和 const let 是块级作用域 let 声明的变量只在其所在的作用域内生效 <script> { var today = "周3"; let yester ...
- Jquery复习(三)之链式调用
通过 jQuery,可以把动作/方法链接在一起. Chaining 允许我们在一条语句中运行多个 jQuery 方法(在相同的元素上). jQuery 方法链接 直到现在,我们都是一次写一条 jQue ...
- phpstorm 快捷键2
1.跨平台. 2.对PHP支持refactor功能.支持断点调试,支持 Symfony2 和 Yii 的 MVC 视图 3.自动生成phpdoc的注释,非常方便进行大型编程. 4.内置支持Zencod ...
- Delphi 赋值语句和程序的顺序结构