菜鸟学IT之python词云初体验
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2822
1. 下载一长篇中文小说。

2. 从文件读取待分析文本。
txt = open(r'G:\aa\三体.txt', 'r', encoding='utf8').read() # 打开三体小说文件
jieba.load_userdict(r'G:\aa\three.txt') # 读取三体小说词库 Filess= open(r'G:\aa\stops_chinese.txt', 'r', encoding='utf8') # 打开中文停用词表
stops = Filess.read().split('\n') # 以回车键作为标识符把停用词表放到stops列表中
3. 安装并使用jieba进行中文分词。

4. 更新词库,加入所分析对象的专业词汇。
- 首先下载你要搜索的txt文本
- 进入词库下载专业词库,参考词库下载地址:https://pinyin.sogou.com/dict/
# -*- coding: utf-8 -*-
import struct
import os # 拼音表偏移,
startPy = 0x1540; # 汉语词组表偏移
startChinese = 0x2628; # 全局拼音表
GPy_Table = {} # 解析结果
# 元组(词频,拼音,中文词组)的列表 # 原始字节码转为字符串
def byte2str(data):
pos = 0
str = ''
while pos < len(data):
c = chr(struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0])
if c != chr(0):
str += c
pos += 2
return str # 获取拼音表
def getPyTable(data):
data = data[4:]
pos = 0
while pos < len(data):
index = struct.unpack('H', bytes([data[pos],data[pos + 1]]))[0]
pos += 2
lenPy = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0]
pos += 2
py = byte2str(data[pos:pos + lenPy]) GPy_Table[index] = py
pos += lenPy # 获取一个词组的拼音
def getWordPy(data):
pos = 0
ret = ''
while pos < len(data):
index = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0]
ret += GPy_Table[index]
pos += 2
return ret # 读取中文表
def getChinese(data):
GTable = []
pos = 0
while pos < len(data):
# 同音词数量
same = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] # 拼音索引表长度
pos += 2
py_table_len = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] # 拼音索引表
pos += 2
py = getWordPy(data[pos: pos + py_table_len]) # 中文词组
pos += py_table_len
for i in range(same):
# 中文词组长度
c_len = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0]
# 中文词组
pos += 2
word = byte2str(data[pos: pos + c_len])
# 扩展数据长度
pos += c_len
ext_len = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0]
# 词频
pos += 2
count = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] # 保存
GTable.append((count, py, word)) # 到下个词的偏移位置
pos += ext_len
return GTable def scel2txt(file_name):
print('-' * 60)
with open(file_name, 'rb') as f:
data = f.read() print("词库名:", byte2str(data[0x130:0x338])) # .encode('GB18030')
print("词库类型:", byte2str(data[0x338:0x540]))
print("描述信息:", byte2str(data[0x540:0xd40]))
print("词库示例:", byte2str(data[0xd40:startPy])) getPyTable(data[startPy:startChinese])
getChinese(data[startChinese:])
return getChinese(data[startChinese:]) if __name__ == '__main__':
# scel所在文件夹路径
in_path = r"C:\Users\Administrator\Downloads" #修改为你的词库文件存放文件夹
# 输出词典所在文件夹路径
out_path = r"C:\Users\Administrator\Downloads\text" # 转换之后文件存放文件夹
fin = [fname for fname in os.listdir(in_path) if fname[-5:] == ".scel"]
for f in fin:
try:
for word in scel2txt(os.path.join(in_path, f)):
file_path=(os.path.join(out_path, str(f).split('.')[0] + '.txt'))
# 保存结果
with open(file_path,'a+',encoding='utf-8')as file:
file.write(word[2] + '\n')
os.remove(os.path.join(in_path, f))
except Exception as e:
print(e)
pass
5. 生成词频统计
# 统计词频次数
for word in tokens:
if len(word) == 1:
continue
else:
wcdict[word] = wcdict.get(word, 0) + 1
6. 排序
# 词频排序
wcls = list(wcdict.items())
wcls.sort(key=lambda x: x[1], reverse=True)
7. 排除语法型词汇,代词、冠词、连词等停用词。
Filess= open(r'G:\aa\stops_chinese.txt', 'r', encoding='utf8') # 打开中文停用词表
stops = Filess.read().split('\n') # 以回车键作为标识符把停用词表放到stops列表中 tokens=[token for token in wordsls if token not in stops]
print("过滤后中文内容对比:",len(tokens), len(wordsls))
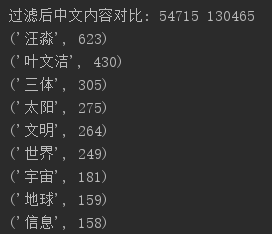
8. 输出词频最大TOP20,把结果存放到文件里
# 打印前25词频最高的中文
for i in range(25):
print(wcls[i]) # 存储过滤后的文本
pd.DataFrame(wcls).to_csv('three.csv', encoding='utf-8') # 读取csv词云
txt = open('three.csv', 'r', encoding='utf-8').read()

9. 生成词云。
# 读取csv词云
txt = open('three.csv', 'r', encoding='utf-8').read() # 用空格键隔开文本并把它弄进列表中
cut_text = "".join(jieba.lcut(txt))
mywc = WordCloud().generate(cut_text) plt.imshow(mywc)
plt.axis("off")
plt.show()
默认形状:

修改背景:


菜鸟学IT之python词云初体验的更多相关文章
- 菜鸟学IT之豆瓣爬取初体验
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159 可以用pandas读出之前保存的数据: newsdf = pd.re ...
- python词云生成-wordcloud库
python词云生成-wordcloud库 全文转载于'https://www.cnblogs.com/nickchen121/p/11208274.html#autoid-0-0-0' 一.word ...
- Python 词云可视化
最近看到不少公众号都有一些词云图,于是想学习一下使用Python生成可视化的词云,上B站搜索教程的时候,发现了一位UP讲的很不错,UP也给出了GitHub上的源码,是一个很不错的教程,这篇博客主要就是 ...
- Python 词云分析周杰伦《晴天》
一.前言满天星辰的夜晚,他们相遇了...夏天的时候,她慢慢的接近他,关心他,为他付出一切:秋天的时候,两个人终於如愿的在一起,分享一切快乐的时光但终究是快乐时光短暂,因为杰伦必须出国深造,两人面临了要 ...
- python词云的制作方法
第一次接触到词云主要是觉得很好看,就研究了一下,官方给出了代码的,但是新手看的话还是有点不容易,我们来尝试下吧. 环境:python2.7 python库:PIL(pillow),numpy,matp ...
- python 词云小demo
词云小demo jiebawordcloud 一 什么是词云? 由词汇组成类似云的彩色图形.“词云”就是对网络文本中出现频率较高的“关键词”予以视觉上的突出,形成“关键词云层”或“关键词渲染”,从而过 ...
- Python词云生成
一.目的 1. 熟悉jieba库和wordcloud库的使用方法: 2. 熟悉文本词频统计和词云生成的基本方法. 二.内容 1. 从网上自行下载一个长篇英文小说,统计并输出该小说中词频最大的TOP 2 ...
- python 词云学习
词云入门 三步曲 数据获取:使用爬虫在相关网站上获取文本内容 数据清洗:按一定格式对文本数据进行清洗和提取(文本分类,贴标签) 数据呈现:多维度呈现和解读数据(计算,做表,画图) 一 模块的安装 pi ...
- python词云
词云图 from os import path from PIL import Image import numpy as np import matplotlib.pyplot as plt fro ...
随机推荐
- Java数据结构和算法 - OverView
Q: 为什么要学习数据结构与算法? A: 如果说Java语言是自动档轿车,C语言就是手动档吉普.数据结构呢?是变速箱的工作原理.你完全可以不知道变速箱怎样工作,就把自动档的车子从1档开到4档,而且未必 ...
- 解决 HomeBrew 下载缓慢的问题
macOS 自身不提供包管理器,常用的包管理器有 HomeBrew MacPorts MacPorts 第一次使用要 build 整个基本库,编译时间很长.优点是不怎么依赖系统,更新 macOS 不会 ...
- [Nuget]Nuget命令行工具安装
下载 地址:https://www.nuget.org/downloads 直接下最新推荐版本(recommended latest)就好了. 是个单一的nuget.exe文件. 安装配置 想要在wi ...
- C# 实现WebSocket通信
本实例可通过web网页端进行测试,下面直接上代码. 首先要在NuGet导入“Fleck”包,需 .NET Framework 4.5及以上. using System; using System.Co ...
- 从壹开始前后端分离 [ Vue2.0+.NET Core2.1] 十五 ║Vue基础:JS面向对象&字面量& this字
缘起 书接上文<从壹开始前后端分离 [ Vue2.0+.NET Core2.1] 十四 ║ VUE 计划书 & 我的前后端开发简史>,昨天咱们说到了以我的经历说明的web开发经历的 ...
- C#版 - Leetcode49 - 字母异位词分组 - 题解
C#版 - Leetcode49 - 字母异位词分组 - 题解 Leetcode49.Group Anagrams 在线提交: https://leetcode.com/problems/group- ...
- 【朝花夕拾】Android安全之(一)权限篇
前言 从Android6.0开始,Android系统对权限的处理产生了很大的变化.如果APP运行的设备系统版本为Android6.0或更高,并且target在23或更高,那么danger ...
- 基于Log4Net本地日志服务简单实现
背景 项目开发中,我们或多或少会使用诸如NLog,Log4Net,Kafka+ELK等等日志套件: 基于关注点分离原则,业务开发的时候不应该关注日志具体实现:并且后续能方便切换其他日志套件: 这里先实 ...
- kubernetes系列08—service资源详解
本文收录在容器技术学习系列文章总目录 1.认识service 1.1 为什么要使用service Kubernetes Pod 是有生命周期的,它们可以被创建,也可以被销毁,然而一旦被销毁生命就永远结 ...
- Java——容器类库框架浅析
前言 通常,我们总是在程序运行过程中才获得一些条件去创建对象,这些动态创建的对象就需要使用一些方式去保存.我们可以使用数组去存储,但是需要注意数组的尺寸一旦定义便不可修改,而我们并不知道程序在运行过程 ...