NIO(一)——缓冲区Buffer
NIO(一)——Buffer
- NIO简介
- NIO即New IO,是用来代替标准IO的,提供了与标准IO完全不同传输方式。
- 核心:通道(Channel)和缓冲区(Buffer)和选择器(Selectors),Channel负责传输,Buffer负责存储
- 与标准IO的区别
- 标准IO是面向字节流的,NIO是面向缓冲区的
- 标准IO是阻塞IO,NIO是非阻塞IO
- 当线程从通道读取数据到缓冲区时,线程还是可以进行其他事情。当数据被写入到缓冲区时,线程可以继续处理它。从缓冲区写入通道也类似。
NIO具有选择器Selectors
- 选择器用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个的线程可以监听多个数据通道
- 缓冲区Buffer
- 在Java NIO中负责数据的存取。缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。
- 根据数据类型的不同,提供了不同类型的缓冲区(boolean除外):
- ByteBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
- CharBuffer
- 上述缓冲区的管理方式几乎一致,通过allocate()获取缓冲区:
- ByteBuffer buf = ByteBuffer.allocate(1024);
缓冲区存储数据的两个核心方法:
- put():存数据到缓冲区
- get():从缓冲区取数据
缓冲区中的核心属性:
- capacity:容量,表示缓冲区中最大存储数据的容量,一旦声明不可改变
- limit:界限,表示缓存区冲可以操作数据的大小。limit后的数据不能进行读写(读和写操作含义不同)
- position:位置,表示缓冲区中正在操作的数据的位置
- mark:标记,表示记录当前position的位置,可以通过reset()恢复到mark的位置
- 0<=mark<=position<=limit<=capacity
- 方法:
- flid()方法:在切换读写模式的时候必须调用flid()方法
- buf.flip();
- flip()方法:

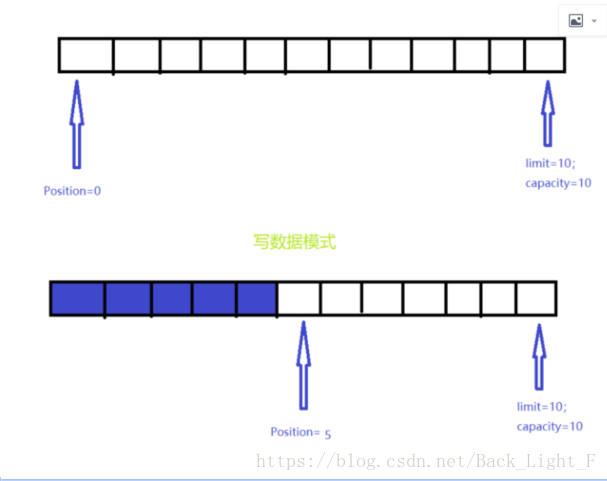
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
- rewind()方法:
- 可重复读数据,将position置0,limit不变
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
clear()与compact()方法:
- 一旦读完缓冲区中的数据,需要让缓冲区准备好再次被写入。可以通过clear()或compact方法来完成。
- 如果调用的是clear()方法,position将被置0,limit被设置为capacity的值。即缓冲区被清空。但缓冲区中的数据并未被清除。
- 如果缓冲区中有一些未读的数据,调用clean()方法,数据将“被遗忘”。
- 如果缓冲区中有一些未读的数据,且后续还需要这些数据,但此时想先写些数据,就使用compact()方法。compact()方法将所有未读的数据拷贝到Buffer起始处,然后将position设到最后一个未读元素后面,limit=capacity。
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}public abstract ByteBuffer compact();
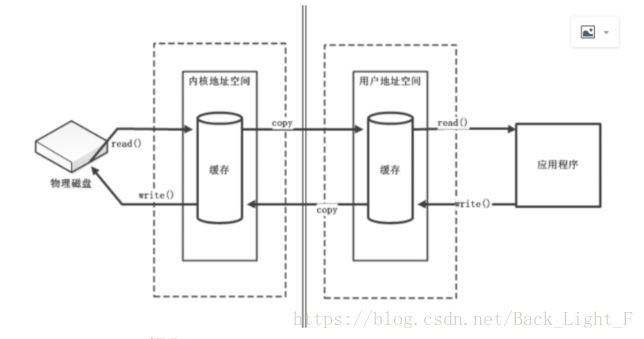
- 直接缓冲区与非直接缓冲区:
- 非直接缓冲区:通过allocate()方法分配缓冲区,将缓冲区建立在JVM内存中
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}HeapByteBuffer(int cap, int lim) {
super(-1, 0, lim, cap, new byte[cap], 0);
}ByteBuffer(int mark, int pos, int lim, int cap, byte[] hb, int offset){
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
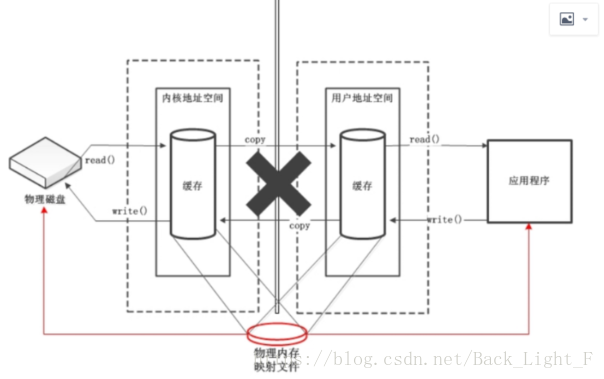
- 直接缓冲区:
- 通过allocateDirect()方法分配直接缓冲区,将缓冲区建立在物理内存中。可以提高效率
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}DirectByteBuffer(int cap) {
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
//调用直接内存方法进行分配
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap); long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
NIO(一)——缓冲区Buffer的更多相关文章
- NIO之缓冲区(Buffer)的数据存取
缓冲区(Buffer) 一个用于特定基本数据类行的容器.有java.nio包定义的,所有缓冲区都是抽象类Buffer的子类. Java NIO中的Buffer主要用于与NIO通道进行交互,数据是从通道 ...
- nio之缓冲区(Buffer)理解
一.缓冲区简介 Nio中的 Buffer 是用于存储特定基础类型的一个容器.为了能熟练的使用 Nio中的各种 Buffer , 我们需要理解 Buffer 中的 三个重要 的属性. 1. capaci ...
- Java NIO之缓冲区Buffer
Java NIO的核心部件: Buffer Channel Selector Buffer 是一个数组,但具有内部状态.如下4个索引: capacity:总容量 position:下一个要读取/写入的 ...
- Java NIO流 -- 缓冲区(Buffer,ByteBuffer)
用来定义缓冲区的所有类都以Buffer类为基类,Buffer定义了缓冲区的基本特征. 直接子类: ByteBuffer 用来存储byte类型的缓冲区,可以在这种缓冲区中存储任意其他基本类型的二进制值( ...
- Java NIO -- 缓冲区(Buffer)的数据存取
缓冲区(Buffer): 一个用于特定基本数据类型的容器.由 java.nio 包定义的,所有缓冲区都是 Buffer 抽象类的子类.Java NIO 中的 Buffer 主要用于与 NIO 通道进行 ...
- JAVA NIO缓冲区(Buffer)------ByteBuffer常用方法
参考:https://blog.csdn.net/xialong_927/article/details/81044759 缓冲区(Buffer)就是在内存中预留指定大小的存储空间用来对输入/输出(I ...
- NIO(一):Buffer缓冲区
一.NIO与IO: IO: 一般泛指进行input/output操作(读写操作),Java IO其核心是字符流(inputstream/outputstream)和字节流(reader/writer ...
- Java NIO 缓冲区 Buffer
缓冲区 Buffer 是 Java NIO 中一个核心概念,它是一个线性结构,容量有限,存放原始类型数据(boolean 除外)的容器. 1. Buffer 中可以存放的数据类型 java.nio.B ...
- Java-NIO(二):缓冲区(Buffer)的数据存取
缓冲区(Buffer): 一个用于特定基本数据类行的容器.有java.nio包定义的,所有缓冲区都是抽象类Buffer的子类. Java NIO中的Buffer主要用于与NIO通道进行交互,数据是从通 ...
随机推荐
- window7如何配置修改环境变量
http://jingyan.baidu.com/article/b24f6c82cba6dc86bfe5da9f.html
- How I Turned Down $300,000 from Microsoft to go Full-Time on GitHub
How I Turned Down $300,000 from Microsoft to go Full-Time on GitHub (我是如何拒绝微软30w的诱惑,专注于GitHub事业) 当我老 ...
- C# 操作Word 文档——添加Word页眉、页脚和页码
在Word文档中,我们可以通过添加页眉.页脚的方式来丰富文档内容.添加页眉.页脚时,可以添加时间.日期.文档标题,文档引用信息.页码.内容解释.图片/LOGO等多种图文信息.同时也可根据需要调整文字或 ...
- 获取list,有内容就赋值,根据ID显现NAME,没有显现list
function onTOWN() { var town=mini.get("TOWN_ID"); var town_id =town.getValue(); $.ajax({ u ...
- IT轮子系列(七)——winform 版本更新组件
前言 最近做了一个winform客户端的项目,里面有一个功能是版本更新.以前也有写过,可忘了具体的逻辑.网上也有介绍用发布模式进行更新的,自己尝试后没有成功,提示“vba证书无效”.于是,费了些时间搜 ...
- TCP / IP,HTTP
大学学习网络基础的时候老师讲过,网络由下往上分为物理层.数据链路层.网络层.传输层.会话层.表示层和应用层.通过初步的了解,我知道IP协议对应于网络层,TCP协议对应于传输层,而HTTP协议对应于应用 ...
- Strom topology 设计的演进
场景:采集日志数据,日志数据有多个字段组成,需求是根据日志数据中的N个字段(维度),去统计指标数据(个数.平均值)等.
- Hbase出现ERROR: Can't get master address from ZooKeeper; znode data == null解决办法
问题描述如下: hbase(main)::> list TABLE ERROR: Can't get master address from ZooKeeper; znode data == n ...
- CSS样式渐变代码,兼容IE8
background: -webkit-linear-gradient(top,#ffffff,#f5f5f5); background: -moz-linear-gradient(top,#ffff ...
- eclipse配置tomcat后启动报内存错误解决方法
一.双击tomcat服务,打开配置界面 二.打开launch configuration窗口,在Argument最后面加入:-Xms256m -Xmx512m -XX:PermSize=256M -X ...