MySQL多数据源笔记3-分库分表理论和各种中间件
一.使用中间件的好处
使用中间件对于主读写分离新增一个从数据库节点来说,可以不用修改代码,达到新增节点数据库而不影响到代码的修改。因为如果不用中间件,那么在代码中自己是先读写分离,如果新增节点,
你进行写操作时,你的轮询求模的数据量就要修改。但是中间件的维护也很麻烦的。
二.各种中间件
1.MYSQL官方的mysqlProxy,它可以实现读写分离,但是它使用率很低,搞笑的是MySQL官方都不推荐使用。
2.Amoeba:这是阿里巴巴工程司写的,是开源的。使用也很少。
3.mycat
4.ShardingJDBC
注意:如果我们单纯的做读写分离,一般都会选择用SpringAOP去做。并不是一定使用中间件就一定好。
读写分离做完,我们数据库的压力就解决了吗?
并没有,做完读写分离,我们都知道知识一个或几个主库,多个从库,每个数据库里面的数据都是一样的。只是一份复制。
这样做的好处就是:
1。数据库可以备份。
2.减轻数据库的压力。
数据库的压力问题就缓解了吗?并没有缓解的特别厉害,当你这真正的高并发,大数据量来的时候,你做读写分离也不够用的。MySQL单表能承受多少数据量呢?
实践来看的话,大概也就7000W-1亿,这根据字段量,和字段里面存的东西,这数据是根据业务走的,不一定那么精确。
当达到这个数量级的时候你的多表关联查询什么的,即便优化到位,我说的优化,第一是索引一定要设置合理,第二SQL优化,但是SQL优化做的很有限。
到这个数据量你去关联那么两三个表,基本都是在5S,10S甚至更长的时间。
这时候就要考虑别的办法了。走到这一步,那该怎么办呢?
那么就要进行分库分表:
1.垂直拆分:
基于领域模型做数据的垂直切分是一种最佳实践。如将订单、用户、支付等领域模型划分到不同的DB库里面。前提必须各领域数据之间join展示场景较少,在这种情况下分库能获得很高的价值,同时各个系统之间的扩展性得到很大程度的提高。
缺点:如果在拆分之前,系统中很多列表和详情页所需的数据是可以通过sql join来完成的。而拆分后,数据库可能是分布式在不同实例和不同的主机上,join将变得非常麻烦。而且基于架构规范,性能,安全性等方面考虑,一般是禁止跨库join的。
那该怎么办呢?首先要考虑下垂直分库的设计问题,如果可以调整,那就优先调整。
解决办法:
1.建立全局表:系统中可能出现所有模块都可能会依赖到的一些表。比较类似我们理解的“数据字典”。为了避免跨库join查询,我们可以将这类表在其他每个数据库中均保存一份。这种做法叫做建立全局表
同时,这类数据通常也很少发生修改(几乎不会),一般不用太担心“一致性”问题。
2.进行数据同步:比如,用户库中的tab_a表和订单库中tbl_b有关联,可以定时将指定的表做同步。当然,同步本来会对数据库带来一定的影响,需要性能影响和数据时效性中取得一个平衡。这样来避免复杂的跨库查询。
3.系统层面组装:调用不同模块的组件或者服务,获取到数据并进行字段拼装。不要想着这很容易,实践起来可真没有那么容易,尤其是数据库设计上存在问题但又无法轻易调整的时候。具体情况通常会比较复杂。
组装的时候要避免循环调用服务,循环RPC,循环查询数据库,最好一次性返回所有信息,在代码里做组装。
4.适当的进行字段冗余:比如“订单表”中保存“卖家Id”的同时,将卖家的“Name”字段也冗余,这样查询订单详情的时候就不需要再去查询“卖家用户表”。
如下图:
拆分前:
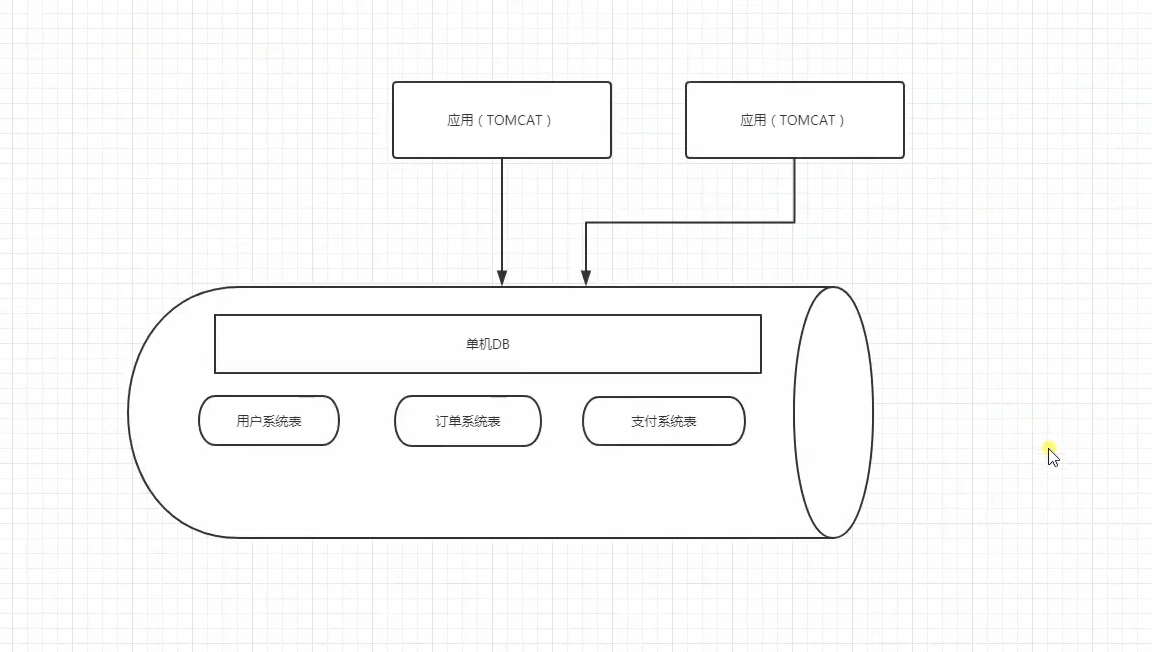
拆分后:

这样的话能够缓解一下压力,我们还可以对每一个独立的DB在进行读写分离。
当然拆分也会出现问题的。比如说分布式事务。比如支付系统支付失败了回滚,那么你订单系统也要回滚的。但是你们都不在同一个库里面,这是就需要分布式事务了。
如果走到这一步,你的系统还是缓解不了压力,那么说明你这系统比较厉害了。说明你公司在你的行业里面能叫的上名字的了。
那么我们就要进行水平拆分了。
2.水平拆分:垂直切分缓解了原来单集群(所有的数据库都存在一张表里,)的压力,但是在抢购时依然捉襟见肘。原有的订单模型已经无法满足业务需求,于是就要进行水平分表也称为横向分表,
比较容易理解,就是将表中不同的数据行按照一定规律分布到不同的数据库表中(这些表保存在同一个数据库中),这样来降低单表数据量,优化查询性能。
最常见的方式就是通过主键或者时间等字段进行Hash和取模后拆分。
如下图:
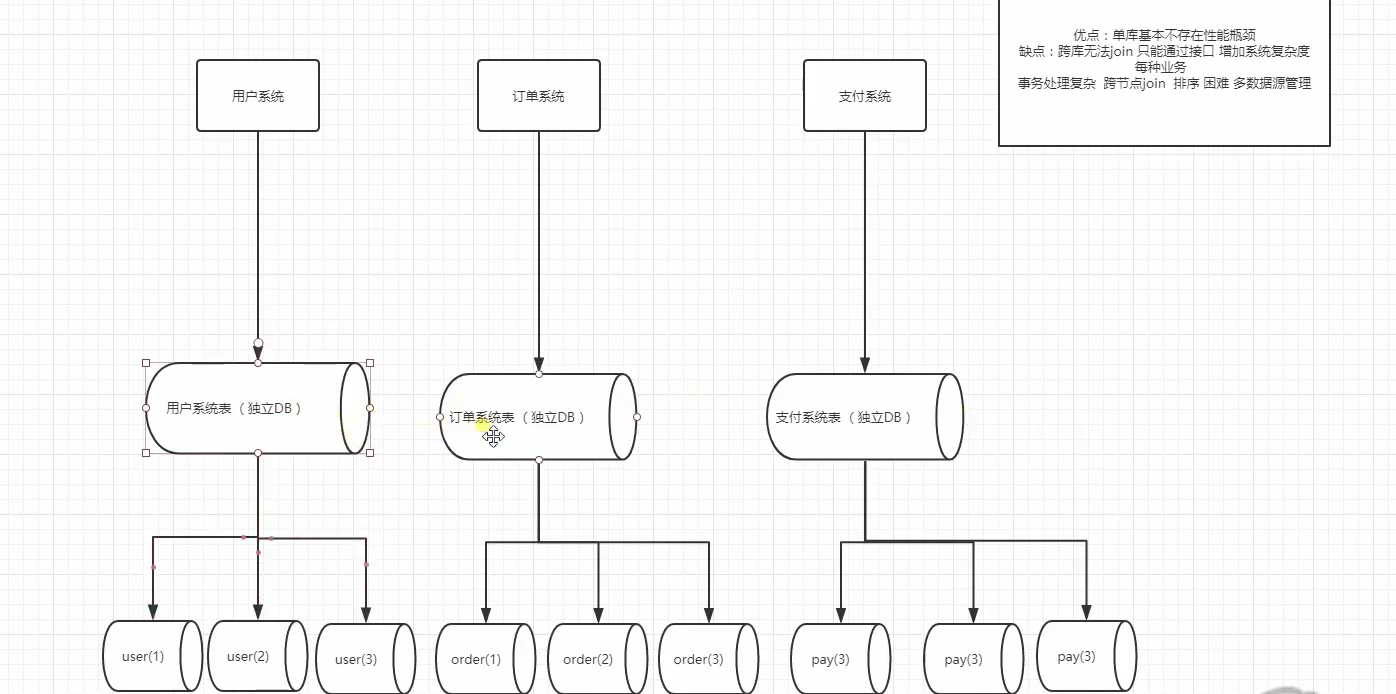
如果数据压力还是比较大怎么呢?,还能怎么办,继续进行水平拆分咯,比如,user(1)user(2)user(3)继续惊醒水平拆分。
水平拆分所带来的问题:
1.常见分片规则问题
1。一致性hash:依据Sharding Key对5取模,根据余数将数据散落到目标表中。比如将数据均匀的分布在5张user表中,如下图:

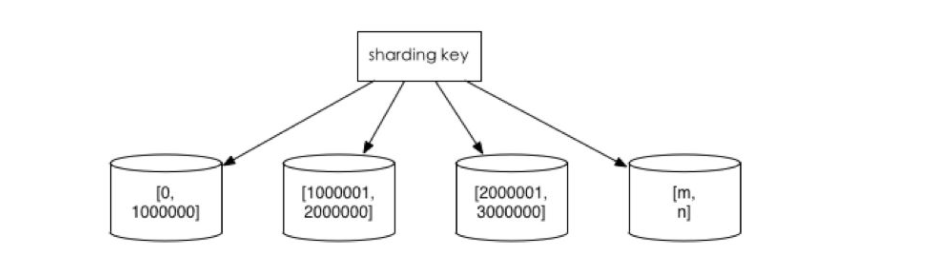
2.范围切分:比如按照时间区间或ID区间来切分。
优点:单表大小可控,天然水平扩展。
缺点:无法解决集中写入瓶颈的问题
如下图:
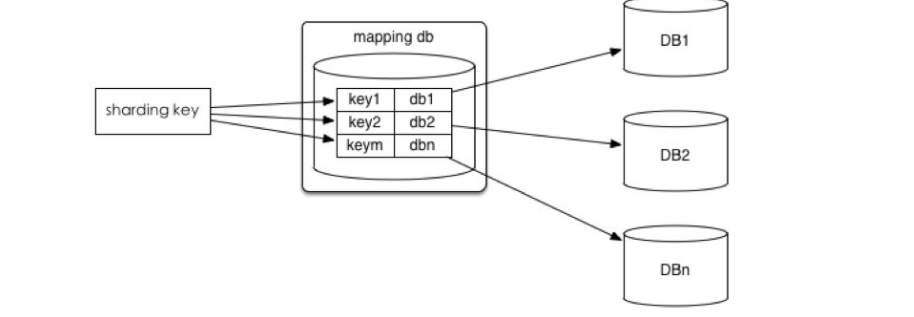
3.将ID和库的Mapping关系记录在一个单独的库中。
优点:ID和库的Mapping算法可以随意更改。
缺点:引入额外的单点。
如下图:
数据迁移问题
很少有项目会在初期就开始考虑分片设计的,一般都是在业务高速发展面临性能和存储的瓶颈时才会提前准备。因此,不可避免的就需要考虑历史数据迁移的问题。
一般做法就是通过程序先读出历史数据,然后按照指定的分片规则再将数据写入到各个分片节点中。
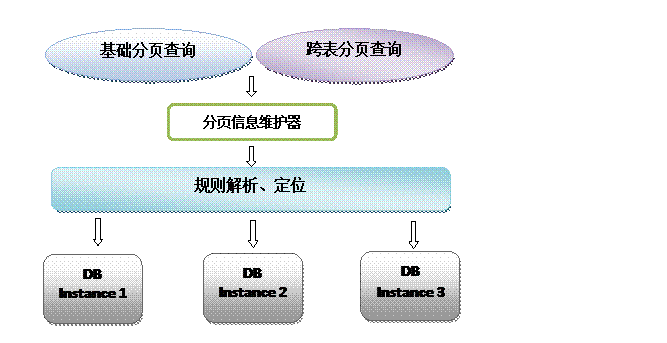
跨分片的排序分页
在分库分表的情况下,为了快速(分页)查询数据,分表策略的选择就显得非常重要了,需要尽最大限度将需要跨范围查询的数据尽量集中,多数情况下在我们做了最大限度的努力之后,数据仍然可能是分布式的。
为了进一步提高查询的性能,维持查询的中间变量信息是我们在分库分表模式下提高分页查询速度的另一个手段:我们每次翻页查询时,通过中间信息的分析,就可以直接定位到目标表的目标位置,通过这种方式提供了近似于在单表模式下的分页查询能力。
但另一方面也需要在业务上做出一定的牺牲:限制查询区段,提高检索速度。
如下图:
跨分片的函数处理
在使用Max、Min、Sum、Count之类的函数进行统计和计算的时候,需要先在每个分片数据源上执行相应的函数处理,然后再将各个结果集进行二次处理,最终再将处理结果返回。
跨分片join
Join是关系型数据库中最常用的特性,但是在分片集群中,join也变得非常复杂。应该尽量避免跨分片的join查询(这种场景,比上面的跨分片分页更加复杂,而且对性能的影响很大)。
通常有以下几种方式来避免:
1.全局表
全局表的概念之前在“垂直分库”时提过。基本思想一致,就是把一些类似数据字典又可能会产生join查询的表信息放到各分片中,从而避免跨分片的join。
2.ER分片
在关系型数据库中,表之间往往存在一些关联的关系。如果我们可以先确定好关联关系,并将那些存在关联关系的表记录存放在同一个分片上,那么就能很好的避免跨分片join问题。在一对多关系的情况下,我们通常会选择按照数据较多的那一方进行拆分。
3.内存计算
随着spark内存计算的兴起,理论上来讲,很多跨数据源的操作问题看起来似乎都能够得到解决。可以将数据丢给spark集群进行内存计算,最后将计算结果返回。
总结
并非所有表都需要水平拆分,要看增长的类型和速度,水平拆分是大招,拆分后会增加开发的复杂度,不到万不得已不使用。
在大规模并发的业务上,尽量做到在线查询和离线查询隔离,交易查询和运营/客服查询隔离。
拆分维度的选择很重要,要尽可能在解决拆分前问题的基础上,便于开发。
数据库没你想象的那么坚强,需要保护,尽量使用简单的、良好索引的查询,这样数据库整体可控,也易于长期容量规划以及水平扩展。
MySQL多数据源笔记3-分库分表理论和各种中间件的更多相关文章
- (转) MySQL分区与传统的分库分表
传统的分库分表 原文:http://blog.csdn.net/kobejayandy/article/details/54799579 传统的分库分表都是通过应用层逻辑实现的,对于数据库层面来说,都 ...
- Mysql系列四:数据库分库分表基础理论
一.数据处理分类 1. 海量数据处理,按照使用场景主要分为两种类型: 联机事务处理(OLTP) 面向交易的处理系统,其基本特征是原始数据可以立即传送到计算机中心进行处理,并在很短的时间内给出处理结果. ...
- MYSQL数据库数据拆分之分库分表总结
数据存储演进思路一:单库单表 单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到. 数据存储演进思路二:单库多表 随着用户数量的 ...
- Mysql系列五:数据库分库分表中间件mycat的安装和mycat配置详解
一.mycat的安装 环境准备:准备一台虚拟机192.168.152.128 1. 下载mycat cd /softwarewget http:-linux.tar.gz 2. 解压mycat tar ...
- 高可用Mysql架构_Mysql主从复制、Mysql双主热备、Mysql双主双从、Mysql读写分离(Mycat中间件)、Mysql分库分表架构(Mycat中间件)的演变
[Mysql主从复制]解决的问题数据分布:比如一共150台机器,分别往电信.网通.移动各放50台,这样无论在哪个网络访问都很快.其次按照地域,比如国内国外,北方南方,这样地域性访问解决了.负载均衡:M ...
- <转>MYSQL数据库数据拆分之分库分表总结
数据存储演进思路一:单库单表 单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到. 数据存储演进思路二:单库多表 随着用户数量的 ...
- mysql(5):主从复制和分库分表
主从复制集群 概念:主从复制是指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点. 使用场景: 读写分离:使用主从复制,让主库负责写,从库负责读,这样,即使主库出现了锁表的情景,通过读 ...
- MYSQL数据库数据拆分之分库分表总结 (转)
数据存储演进思路一:单库单表 单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到. 数据存储演进思路二:单库多表 随着用户数 ...
- MySQL全面瓦解28:分库分表
1 为什么要分库分表 物理服务机的CPU.内存.存储设备.连接数等资源有限,某个时段大量连接同时执行操作,会导致数据库在处理上遇到性能瓶颈.为了解决这个问题,行业先驱门充分发扬了分而治之的思想,对大库 ...
随机推荐
- 测试任务汇总v1.0
2017.08.04 整理了目前我们所在团队需要做的日常任务 定义为v1.0
- js中的isNaN()函数
<html> <head> <script type="text/javascript" src="function.js"> ...
- ListIterator的使用
package cn.lonecloud.Iterator; import java.util.ArrayList; import java.util.ListIterator; public cla ...
- WEB服务器防盗链_HttpAccessKeyModule_Referer(Nginx&&PHP)
盗链的概念指在自己的页面上展示一些并不在自己服务器上的内容.也就是获得他人服务器上的资源地址,绕过别人的资源展示页面,直接在自己的页面上向最终用户提供此内容.如,小站盗用大站的图片.音乐.视频.软件等 ...
- 老男孩Python全栈开发(92天全)视频教程 自学笔记21
day21课程内容: json: #序列化 把对象(变量)从内存中 编程可存储和可传输的过程 称为序列化import jsondic={'name':'abc','age':18}with open ...
- 2017CCPC 网络选拔赛1003 Ramsey定理
Ramsey定理 任意6个人中,一定有三个人互为朋友,或者互相不是朋友. 证明 这里我就不证明了.下面链接有证明 鸽巢原理 Ramsey定理 AC代码 #include <stdio.h> ...
- python如何使用pymysql模块
Python 3.x 操作MySQL的pymysql模块详解 前言pymysql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同.但目前pymysql支持python3.x而M ...
- php留言板
这个小项目的学习,就这样结束啦.由于过程中需要使用到js,这个目前还是感觉不会.之前的分析还是不太懂的.现在心里还是有点迷茫.什么都是照着葫芦画瓢. 我的拥有自己的东西才行.
- shell脚本基础 数值运算 判断 及if语句
数值运算 整数运算[三种,随便掌握一种即可]expr 数字 运算符 数字 [root@ceshiji ~]# expr 1 + 1(运算符号都是+ - * / 注:*需要\*.%是取余,余数只有0 1 ...
- FusionCharts封装-Label
Category.java: /** * @Title:Category.java * @Package:com.fusionchart.model * @Description:FusionChar ...